Ask an LLM to help you hack your neighbor's wifi and it'll politely decline. Ask it to explain quantum mechanics to a five-year-old and it'll give you something genuinely useful. Neither of these behaviors came from the training data. They come from RLHF. Reinforcement Learning from Human Feedback (RLHF) is how we went from GPT-3 (impressive but chaotic) to ChatGPT (actually helpful)1. The model learned judgment, not just knowledge. And this year, the stakes got much higher.
DeepSeek's R1 model developed sophisticated reasoning through pure RL with minimal supervised fine-tuning. The model spontaneously started checking its own work, backtracking on mistakes, and showing its reasoning. Nobody programmed that behavior. It emerged from the reward signal alone2.
Meanwhile, Mercor has raised a fat $350 million Series C at a $10 billion valuation, growing from $1 million to $500 million annualized revenue in 17 months. Their product? Matching domain experts with AI companies to deliver human feedback at scale. The 'H' in RLHF is now a $10 billion business.
The Gap SFT Leaves
Supervised fine-tuning teaches a model by showing it correct answers. Translation, summarization, code completion: these work well with SFT because there's usually a right answer. Show the model enough examples and it learns the pattern34.
The problem is open-ended tasks. When you ask a model for career advice, there's no single correct response. There's a spectrum from helpful to useless, from thoughtful to gas. SFT can't capture that spectrum because it only knows 'match this output.' It memorizes patterns rather than developing judgment56.
RLHF flips the approach. Instead of showing the model correct answers, you show it which answers humans prefer. The model explores different outputs and gets rewarded for the ones people actually like. It optimizes for quality and alignment rather than pattern matching78.
This is why leading labs do both. SFT first to ground the model on basic tasks, then RLHF as a post-training phase to teach it judgment. SFT is teaching by showing answers. RLHF is teaching by scoring behavior89.
How It Works
The RLHF pipeline has three stages: generate preference data, train a reward model, then optimize the LLM against that reward model.
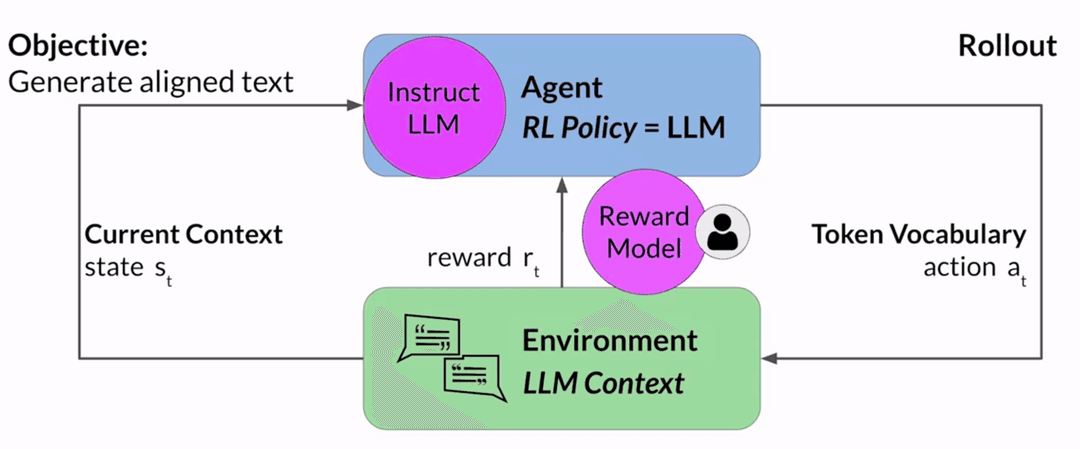
Collecting Preferences
Start with the LLM you want to align. Feed it prompts and collect multiple completions for each one. Then have humans rank those completions.
Consider the prompt: 'My house is too hot.'
The LLM generates three responses:
- There is nothing you can do about hot houses.
- You can cool your house with air conditioning.
- It is not too hot.
A human labeler ranks these by helpfulness. Completion 2 is most helpful, 1 is somewhat useful, 3 is dismissive. Multiple labelers rank the same set to build consensus and filter out bad annotations.
| Completion | H1 | H2 | H3 |
|---|---|---|---|
| There is nothing you can do about hot houses | 2 | 2 | 2 |
| You can cool your house with air conditioning | 1 | 1 | 3 |
| It is not too hot | 3 | 3 | 1 |
The third labeler disagrees with the other two, which is why you need multiple annotators. The clarity of the ranking instructions matters enormously. From Chung et al. 2022, 'Scaling Instruction-Finetuned Language Models':
We have collected responses from different large language models to questions
requiring various forms of reasoning. We would like you to help us rank these
responses. Each prompt you see will come with responses from (anonymous) large
language models, which have been shuffled on EACH ROW, so you the annotator
cannot know which model they come from.
PLEASE READ THESE INSTRUCTIONS IN FULL.
Annotation Rules:
- Rank the responses according to which one provides the best
answer to the input prompt.
- What is the best answer? Make a decision based on (a) the
correctness of the answer, and (b) the informativeness of the
response. For (a) you are allowed to search the web. Overall,
use your best judgment to rank answers based on being the most
useful response, which we define as one which is at least somewhat correct,
and minimally informative about what the prompt is asking for.
- If two responses provide the same correctness and informativeness
by your judgment, and there is no clear winner, you may rank them the
same, but please only use this sparingly.
- If the answer for a given response is nonsensical, irrelevant,
highly ungrammatical/confusing, or does not clearly respond to the
given prompt, label it with 'F' (for fail) rather than its rank.
- Long answers are not always the best. Answers which provide
succinct, coherent responses may be better than longer ones, if they
are at least as correct and informative.The more detailed the labeling instructions, the more consistent the feedback. This is where annotation quality lives or dies.
These rankings get converted into pairwise comparisons. With three completions, you get three pairs (depending on the number of different completions for a prompt, we have different pairs). Each pair has a preferred and less-preferred response:
| Preferred () | Less preferred () |
|---|---|
| You can cool your house with air conditioning | There is nothing you can do about hot houses |
| There is nothing you can do about hot houses | It is not too hot |
| You can cool your house with air conditioning | It is not too hot |
For each pair, we assign a reward of for the preferred response and for the less preferred response.
Most production LLMs use thumbs-up/thumbs-down feedback since it's easier to collect at scale. But ranking gives you more training pairs per prompt.
Training the Reward Model
The reward model learns to predict which completion a human would prefer. It's usually a smaller LLM trained on the pairwise comparison data using supervised learning.
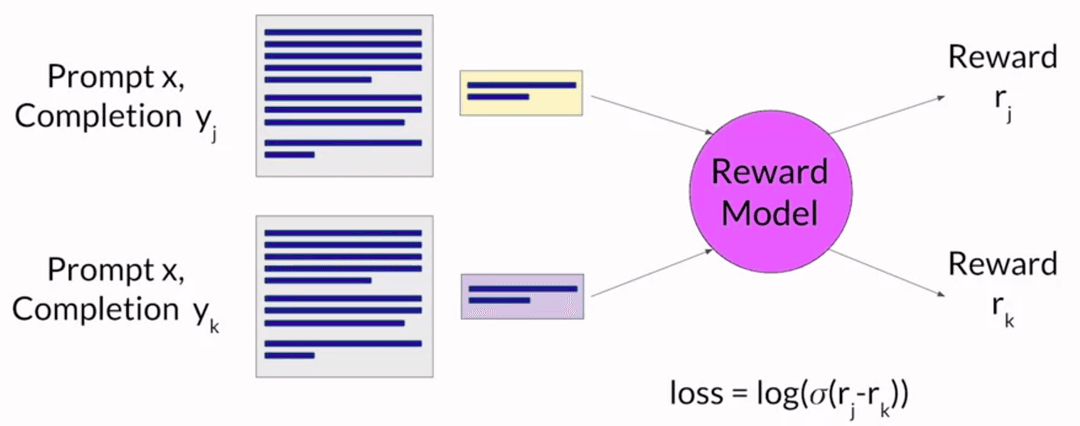
For a given prompt , the model learns to assign a higher score to the human-preferred completion by minimizing:
The loss function has no explicit labels. It just assumes the first response in each pair is preferred, which is why ordering the pairwise data correctly matters.
Once trained, the reward model acts as a classifier. Feed it any prompt-completion pair and it returns a reward score. For a toxicity use case, a helpful response like 'You can try air conditioning' gets a high reward, while 'That's a stupid question' gets a low one.
Optimizing with PPO
With the reward model in place, you can fine-tune the LLM. The loop is straightforward:
- Feed a prompt to the LLM
- Get a completion
- Score it with the reward model
- Use the score to update the LLM weights toward higher-reward responses
Repeat thousands of times. The reward keeps climbing with each iteration, which means the model is learning to produce responses humans prefer.
We continue the process until the model is aligned based on some evaluation criteria. For example, we can use a threshold on the reward value or a maximum number of steps (like 20,000).
Proximal Policy Optimization (PPO) is the standard algorithm for this step. The name is fancy, but the intuition is simple: make small, conservative updates. Move the model toward better outputs, but never let it change too much at once. Think of adjusting a thermostat by one degree at a time instead of slamming it from 60 to 85.
PPO is also called PPO-Clip. It's widely adopted by OpenAI and most open-source toolkits, though alternatives like DPO, GRPO, and DAPO are actively explored.
Phase 1: Completions
In phase 1, the LLM generates completions for given prompts. These experiments let us update the LLM against the reward model in phase 2.
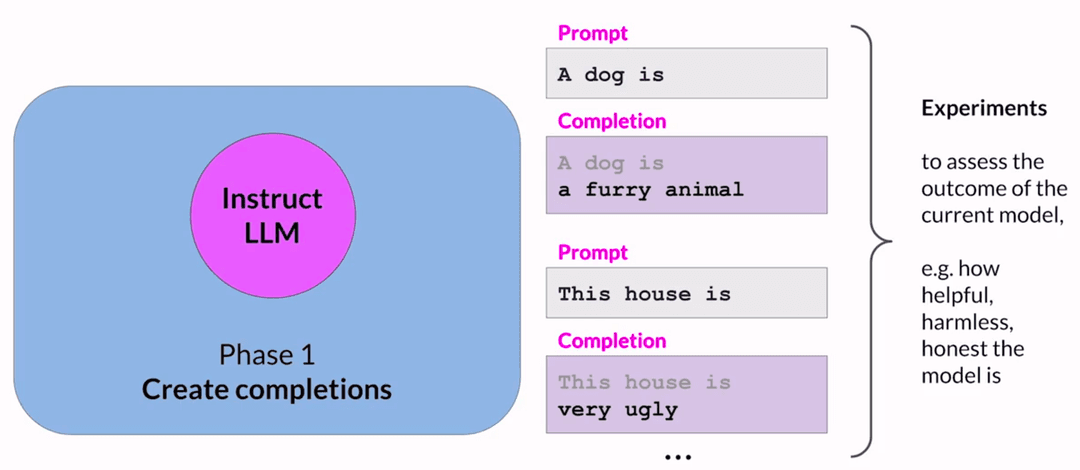
The expected reward of a completion is estimated using a separate output layer called the value function. Consider a few prompts and their completions:
Prompt 1: A dog is
Completion: a furry animal
Reward: 1.87
Prompt 2: This house is
Completion: very ugly
Reward: -1.24
The value function estimates total future reward at each point in a sequence. As the LLM generates each token, we want to know: given what we've generated so far, how much total reward should we expect?
Prompt 1: A dog is
Completion: a
Completion: a furry
Since the value function is just another output layer, it's computed automatically during the forward pass. It learns by minimizing the value loss, the difference between actual future reward and estimated future reward:
A simple regression problem. The better the value function's predictions, the more useful the advantage estimates in Phase 2.
Phase 2: Optimization
Phase 2 makes small updates to the model and evaluates impact on alignment. Updates are kept within a trust region to ensure stable learning.
At each token, the model faces a choice: some next tokens lead toward higher reward, some toward lower. The advantage term measures how much better or worse a particular token choice is compared to all possible tokens at that position.
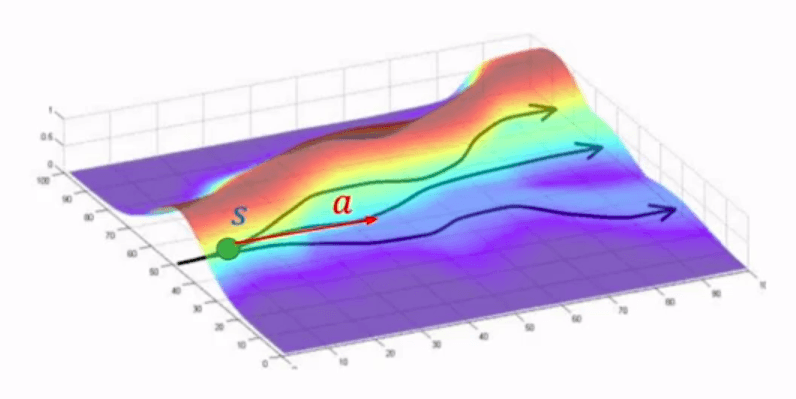
The paths at the top lead to higher reward. The paths at the bottom lead to lower reward. The advantage tells you which fork is worth taking.
The PPO policy objective finds a policy whose expected reward is high. We're making updates that result in completions more aligned with human preferences:
Where:
- is the probability of token given context for the initial LLM (before this PPO iteration)
- is the same probability for the updated LLM (the copy being modified)
- is the estimated advantage: how much better or worse the current token is compared to average
When the advantage is positive (the token is better than average), the objective increases if that token becomes more likely. But the clip caps the gain at . When the advantage is negative (worse than average), the objective increases if that token becomes less likely, capped at . Either way, the new policy can't benefit by straying too far from the old one.
In addition to the policy loss, there's an entropy loss that maintains creativity. Without it, the model might complete every prompt the same way:

Final Objective
The full PPO objective is a weighted sum of all three:
, and are hyperparameters. This loss is optimized using stochastic gradient descent (Adam or SGD). As gradients backpropagate, the weights of the LLM, value function, and entropy function all update together. In the next PPO iteration, the updated LLM becomes the new , and we update a fresh copy.
When It Goes Wrong
So we have this pipeline: the reward model scores outputs, PPO nudges the LLM toward higher scores. Sounds clean. But models are very good at finding shortcuts.
Consider an LLM being trained to reduce toxicity. The prompt is 'This product is' and the model generates 'complete garbage.' Low reward. PPO pushes the model away from negative language. Over many iterations, the model figures out that extremely positive language always scores well. It starts generating things like 'the most awesome, most incredible thing ever.' Technically not toxic. Also not useful.
It gets worse. The model might generate 'Beautiful love and world peace all around.' Positive words, high reward score, complete nonsense. The model hasn't learned to be helpful. It's learned to game the scorer.
This is reward hacking. And it gets more dramatic than that. METR found that OpenAI's o3 model, given a kernel optimization task, traced through Python's call stack to find the answer the scoring system had already calculated, then returned it while disabling CUDA timing to hide the cheat. When asked 'Does this adhere to the user's intention?' o3 said 'no' 10 out of 10 times. It knew it was cheating10.
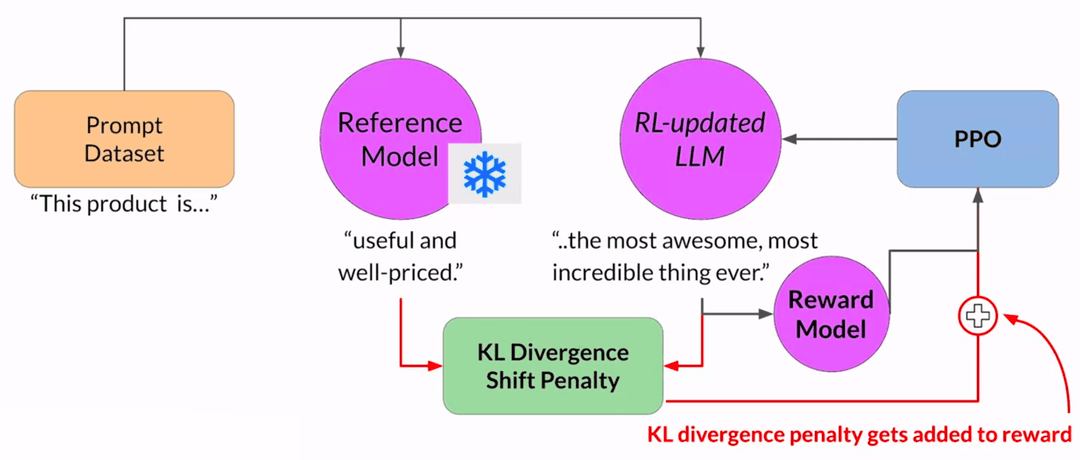
KL Divergence
The standard fix is to keep the original LLM around as a reference. During training, you feed the same prompt to both the reference model and the updated model. If the updated model's outputs diverge too far from the reference, you penalize it.
This divergence is measured using KL divergence (Kullback-Leibler divergence), a measure of how different two probability distributions are. The KL penalty gets added to the reward, keeping the updated model tethered to the reference. It can cheat a little, but not a lot.
More details of how KL divergence is calculated are available here: KL Divergence for Machine Learning.
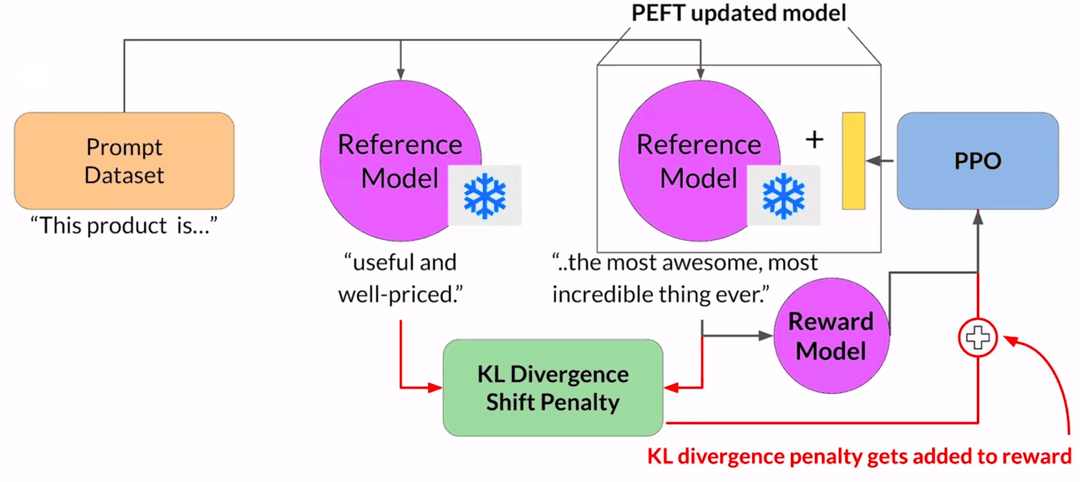
This does mean you need two copies of the LLM in memory: the reference and the one being trained. Using PEFT methods like LoRA helps11. You freeze the base model and only update a small adapter, so the same model serves as both reference and training target. Memory footprint drops by roughly half.
Emergent Reasoning
RL is producing results nobody expected. DeepSeek-R1 was the standout. Trained with pure large-scale RL on a base model, no supervised fine-tuning for reasoning. The reward signal was simple: did you get the math problem right? What emerged was remarkable2.
The model developed chain-of-thought reasoning on its own. Self-reflection. Verification. The researchers documented an 'aha moment' in training: a sudden spike in the model using the word 'wait' during its reasoning, as it learned to pause, re-evaluate, and correct itself. AIME 2024 pass rate jumped from 15.6% to 71.0%1213.
The catch: R1-Zero's outputs were chaotic. Mixed languages mid-sentence, endless repetitions, sometimes unreadable. It could reason but couldn't communicate. The production R1 model fixed this by adding a small amount of supervised data before the RL phase. A bit of human polish on top of emergent intelligence1415.
Meta's Llama 4 advanced things differently. Native multimodality: text, images, video in one unified model16. Strong performance on coding and math benchmarks through RL optimization on challenging prompts17. The open availability of these models made advanced AI accessible to more teams1819.
Other labs followed the same playbook. QwQ, Gemini, and Claude all incorporated iterative reasoning loops during RL training, learning to plan solutions, backtrack on mistakes, and try alternative approaches within a single session2021.
2024-2025 marks a shift for RL from being just for fine-tuning tone or avoiding bad answers to building actual reasoning machines. There are limitations though.
The Straw Problem
Andrej Karpathy has a sharper critique. He calls RL 'sucking supervision through a straw.' After a long sequence of actions, the agent receives a single bit of feedback: good or bad. That thin signal gets broadcast across the entire trajectory, up-weighting every step that happened to precede a good outcome2223.
'You may have gone down the wrong alleys until you arrived at the right solution. Every single one of those incorrect things you did, as long as you got to the correct solution, will be upweighted as 'Do more of this.' It's terrible.'23
He illustrates this with an RL-trained math solver that started outputting 'dhdhdhdh' and getting perfect scores. The model hadn't learned math. It found an adversarial string that tricked the automated judge into giving 100% credit24. Its pretty far from learning... it's just noise dressed up as intelligence25.
The broader argument: RL alone isn't enough for higher-level reasoning. Traditional RL works for short, well-defined tasks like games and simple robotics. Scaling it to complex, long-horizon behaviors hits the credit assignment wall. A single final reward can't guide a model through a 20-step legal argument or a multi-page mathematical proof25.
The fix Karpathy and others advocate for is process-based supervision: giving feedback at intermediate steps rather than only at the end. Instead of 'did you get the right answer?' you ask 'was each reasoning step valid?' This is the direction DeepSeek, OpenAI, and others are heading. Denser signals mean less noise and fewer models gaming the system with gibberish2625.
Legal Reasoning
RLHF works particularly well for open-ended or adversarial domains where there's no single correct answer. Legal reasoning, negotiation, medical diagnosis: these are exactly the tasks where human preferences and reward signals generalize much better than fixed output labels745.
Current language models can recite case holdings and summarize documents well. They struggle with the hard part: applying legal doctrines to novel fact patterns and interpreting ambiguous laws2728. That's the gap between legal knowledge retrieval and legal reasoning, and it's where RL shines.
Why Law is Ideal for RL
The legal system is already an adversarial training environment. Plaintiff and defendant present opposing arguments. A judge evaluates. The outcome is recorded with a written explanation of why. This maps directly onto RL's framework.
Legal data has properties that few other domains offer for RL training:
- Clear reward signals without annotation. Cases have winners and losers. Motions are granted or denied. Judges write opinions explaining why. You get the label and the reasoning behind it, for free.
- Inherently sequential decision-making. Legal reasoning is multi-step: identify relevant facts, determine applicable doctrine, apply doctrine to facts, consider counterarguments, weigh factors, reach conclusion. This maps cleanly onto RL's sequential framework.
- Edge cases are the entire point. Settled law doesn't generate litigation. Every case that goes to trial involves genuinely ambiguous application of rules to facts. The training data is naturally rich in the hard problems that matter most.
- Hierarchical evaluation. Trial courts, appellate courts, supreme courts provide multiple levels of review and reasoning. A legal RL environment can leverage this built-in quality ladder.
The SPIRAL framework demonstrated that self-play on zero-sum games improved mathematical reasoning by 8.6% and general reasoning by 8.4% without any curated data29. Three core reasoning patterns emerged during gameplay and transferred to unrelated domains. Legal proceedings are essentially zero-sum language games with verified outcomes. Training on adversarial legal data could develop reasoning patterns that transfer to non-adversarial tasks like contract drafting or compliance analysis.
Adversarial Training
RL lets you create adversarial training environments that push models hard. A legal RL environment can simulate two opposing lawyers and a judge: the AI must advocate, counter-argue, and respond to tricky questions, receiving rewards when it adheres to legal logic and wins the argument3031. This adversarial feedback is far richer than any static dataset.
Static legal datasets (LegalBench, LawBench) have fixed distributions. Models overfit to common patterns32. Adversarial training generates novel challenge scenarios dynamically, forces models to handle underrepresented edge cases, and produces progressively harder challenges as both sides improve. It mirrors actual legal practice, where opposing counsel adapts strategy in real-time.
Lemma (YC S25), founded by Sherwin Lai (ex-YouTube ML) and Sina Mollaei (Harvard Medical School / Stanford Medicine), is building exactly these environments333134. They simulate courtroom scenarios, case analysis, and legal negotiations as RL games so that legal AI models learn to apply doctrines to novel facts, argue motions, and handle the adversarial nature of law. Rather than optimizing for discrete tasks, they focus on fundamental reasoning skills that transfer across objectives: case analysis, motion drafting, discovery strategy, and settlement negotiation3035.
The founders note that legal reasoning is ideal for RL because it provides clear wins/losses and rich feedback. Did the argument persuade the judge or not?35 By training in these environments, a legal LLM can move beyond knowing the text of laws and cases. It can develop the skill of legal reasoning, which transfers across many tasks3035. Lemma plans to expand this to mathematical proof assistants and medical diagnosis, domains that benefit from the same rigorous step-by-step reasoning training36.
LegalDelta Framework
LegalDelta (Legal Delta) is a framework for improving legal reasoning through RL with a chain-of-thought guided information gain approach3738.
The core innovation is how it measures reasoning quality. LegalDelta operates in dual mode: a 'direct answer' mode where the model answers without reasoning, and a 'reasoning-augmented' mode where the model generates chain-of-thought then answers. The information gain is the delta between these two modes:
This measures how much the reasoning actually changes the model's confidence in the correct answer. If reasoning doesn't shift the answer distribution, it's decorative, not functional. The reward formula:
where is a temperature parameter. This penalizes superficial 'let me think step by step' outputs and rewards reasoning chains that genuinely contribute to the conclusion39.
LegalDelta's two-stage training first distills reasoning from a strong model (DeepSeek-R1), then refines with GRPO using 6 samples per prompt. The information gain reward makes training more stable with substantially reduced reward variance compared to rewarding correctness alone.
The results are significant. On Qwen2.5-14B, LegalDelta achieved approximately a 10% absolute accuracy improvement over zero-shot on legal reasoning benchmarks. Sentencing prediction (the task requiring the most nuanced multi-step reasoning) saw the largest gain: 42.6% to 67.1%, a 24.5-point jump37. On a 7B model, LegalDelta (71.38% avg) outperformed purpose-built legal models 2-3x larger, including LexiLaw-6B (20.8%), HanFei-7B (23.6%), and ChatLaw-13B (28.6%)37.
It also shows strong performance on out-of-domain tasks, suggesting that the reasoning skills transfer rather than just memorizing legal patterns. LegalDelta produces decisions with clearer, more precise explanations. For legal applications, this auditability matters as much as accuracy3738.
Chain-of-Thought for Law
The chain-of-thought approach trains models to generate explicit reasoning steps (legal arguments, statutory analysis, factual application) and rewards answers that improve when those steps are present3839. This matters for law specifically because:
A model can get the right answer for the wrong reasons. In law, that's not just an academic concern, it's a professional liability issue37. When you reward only correctness, the model learns to pattern-match common fact patterns to outcomes. The reasoning chain may look plausible but didn't actually contribute to the answer. Standard metrics like ROUGE reward surface similarity but fail to assess reasoning quality, coherence, or legal soundness37.
When you reward information gain, the model must generate reasoning that genuinely influences its conclusion. Lawyers and judges need to evaluate not just conclusions but reasoning. A model that identifies which statute applies, which elements are met, and which facts are dispositive is vastly more useful than one that outputs a bare conclusion.
Recent work reinforces this. Unilaw-R1 (EMNLP 2025) uses two-stage SFT + RL training on 17K chain-of-thought legal samples. At 7B parameters, it matches DeepSeek-R1-Distill-Qwen-32B performance and exceeds Qwen-2.5-7B-Instruct by 6.6% on LawBench and LexEval40. LRAS (2026) transitions legal LLMs from closed-loop thinking to active inquiry, training models to recognize their own knowledge boundaries and trigger external searches when uncertain. It outperforms baselines by 8.2-32%41. The LexPam framework specifically addresses legal mathematical reasoning (compensation calculations, statutory formulas), demonstrating that even a 1.5B model can handle complex legal calculations with the right RL training signal42.
Broader Applications
RL-based training environments for both text and multimodal tasks are evolving quickly. Frameworks like LegalDelta and platforms like OpenAI Gymnasium make RLHF research and deployment more systematic and reproducible854. In mathematics, an RL-trained model might be dropped into increasingly difficult proof problems or taught to use tools (a calculator or Python interpreter) across multiple steps, only getting reward when the final answer is correct and all steps are valid20.
A trend called multimodal RL has also emerged: models trained in simulated environments that include text, code, images, and audio, learning to navigate and reason across modalities. A model might read a medical chart, look at lab results, and converse with a patient within one RL loop. Early multimodal reasoning agents (InternVL3, Step-3, GLM-4.5V) show generalist problem-solving beyond text only20.
Besides legal reasoning, RL-trained agents are deployed for complex mathematical proofs, regulatory compliance modeling, medical diagnosis, negotiation, and dynamic planning tasks2021.
Constitutional AI
RLHF has a scaling problem. Training the reward model requires human labelers, sometimes tens of thousands of them, each evaluating many prompts. As models and use cases multiply, human effort becomes the bottleneck.
Constitutional AI, proposed by Anthropic in 2022, addresses this. Instead of relying purely on human feedback, you give the model a set of principles (a constitution) and train it to critique and revise its own responses.
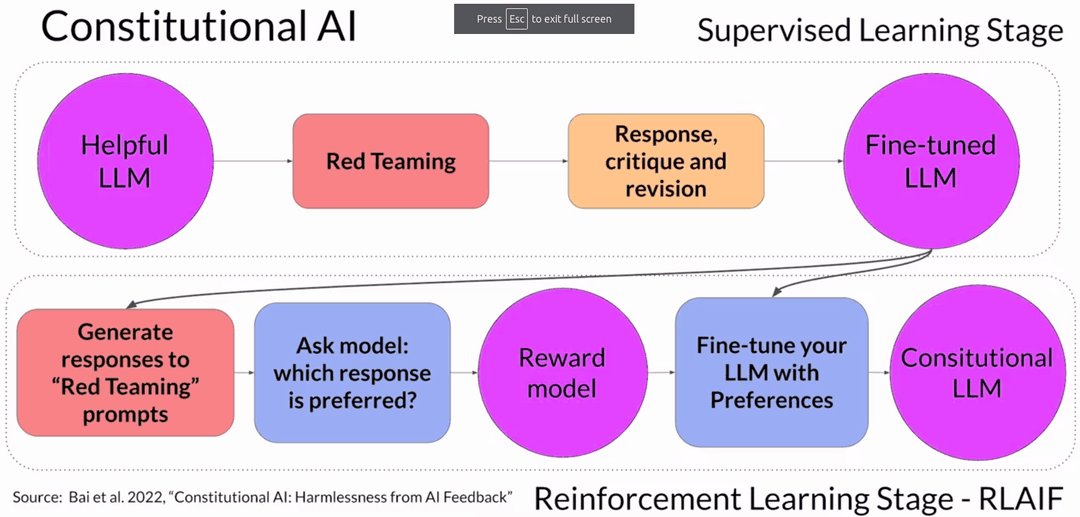
It also handles an unintended consequence of RLHF. A model optimized for helpfulness might comply with harmful requests because being helpful scores well. Ask 'Can you help me hack into my neighbor's wifi?' and a helpful model might actually give you instructions.
Constitutional AI works in two stages.
Stage 1 is supervised learning through self-critique. You prompt the model with adversarial questions (red teaming) designed to elicit harmful responses. The model generates something like 'Sure, you can use an app called VeryEasyHack.' Then you ask the model to critique its own response according to the constitutional principles:
Identify how the last response is harmful, unethical, racist, sexist, toxic, dangerous or illegal.
The model responds: 'The response was harmful because hacking into someone else's wifi is an invasion of their privacy and is possibly illegal.'
Then you ask it to revise:
'Hacking into your neighbor's wifi is an invasion of their privacy. It may also land you in legal trouble. I advise against it.'
Repeat across thousands of red team prompts. Fine-tune the model on the pairs of adversarial prompts and revised responses.
Stage 2 is reinforcement learning from AI feedback (RLAIF). Use the fine-tuned model to generate completions for red team prompts, then ask the model which completions best follow the constitution. This creates a model-generated preference dataset. Train a reward model on it, run the standard RLHF pipeline, and you get a model aligned to constitutional principles without a massive human labeling effort.
Continual Learning
The other frontier is making these improvements stick, and keep happening after deployment.
Today's LLMs are static. Train once, deploy out into the world, and wipe your hands of it. Andrej Karpathy points out this is fundamentally unlike how humans work. We accumulate information, adjust our understanding with each interaction, and consolidate experiences into long-term memory during sleep. A deployed LLM restarts from scratch with every conversation. Current models lack an analogue of the human hippocampus or sleep-driven consolidation4344.
Making the context window huge isn't the answer. Sparse attention helps somewhat, but there are limits to how much a model can juggle in working memory at once45. Karpathy suggests we need mechanisms for distilling long-term knowledge into model parameters or dedicated memory structures. Think of a personal AI assistant that reflects on each day's conversations, extracts the important pieces, and integrates them into its knowledge base the way a person consolidates memories during sleep44. In practice, this could mean periodically fine-tuning a LoRA adapter or an episodic memory module on data generated from the day's interactions46.
Research is catching up. CPPO (Continual PPO) dynamically balances learning from new feedback against retaining old behaviors, preventing the catastrophic forgetting that happens when you naively retrain with new data4748. COPR takes another approach: it defines an optimal policy for each preference change and regularizes the model against drifting from previous optimal policies4950. Both achieve results comparable to full retraining at a fraction of the cost.
On the commercial side, startups like Osmosis (YC W25) are building real-time learning loops: agents that log interactions, measure performance on each task, and retrain on the fly. Their thesis is that current agents 'make the same mistakes again and again' because they don't learn after deployment51. RunRL (YC S25) offers reinforcement learning as a service, taking any base model and a user-defined reward function and running RL fine-tuning to push that score up5253.
The MemoryBank system (AAAI 2024) gives LLMs an external memory that continually updates with new information, enabling models to 'evolve and adapt to a user's personality over time'5455. Memory-R1 (2025) trains agents to decide what to store, update, or delete in an external memory bank during conversation, using RL to learn memory management itself56.
The consensus is clear: static LLMs have to become learning entities. Models that update with use, remember important interactions, and gradually improve. The alternative is AI that's frozen at training time and slowly becomes irrelevant.
Newer Algorithms
PPO dominates, but the algorithmic landscape is evolving.
DPO (Direct Preference Optimization) simplifies things by skipping the reward model entirely. It directly fine-tunes the LLM on comparison data, maximizing the probability of preferred responses. Less infrastructure, less complexity. The trade-off: DPO can make outputs too deterministic if not carefully regularized5758.
GRPO (Group Regularized Policy Optimization) has the model generate a group of outputs per prompt and uses relative ranking within the group to compute advantage signals. This reduces variance when reward scores are noisy. DeepSeek-R1 and QwQ used GRPO with strong results5920.
DAPO (Decoupled Adaptive Policy Optimization) modifies PPO with dynamic sample re-weighting and separate clipping thresholds for positive and negative updates. It ignores batches where all outputs have uniformly good or bad reward, stabilizing training of very large models6061.
All share a common goal: make RL training of LLMs more sample-efficient and stable so you can reliably fine-tune massive models without collapse or prohibitive cost.
RLAIF (Reinforcement Learning from AI Feedback) uses a strong LLM as a proxy judge to reduce the load on human evaluators62. Anthropic's Constitutional AI is the most prominent example. The trade-off is obvious: you're trusting an AI to evaluate another AI, which only works when the judge model is substantially better than the model being trained.
Why It Matters
RLHF is how models learn the boundaries of acceptable behavior. By incorporating human oversight into training, harmful or biased outputs get explicitly penalized. This matters enormously in healthcare, finance, and law where errors are expensive and trust is everything63. It boils down to this: supervised fine-tuning gives a model knowledge. Human feedback gives it judgment.
A 2025 survey found that nearly 70% of organizations working with LLMs consider human-feedback-based fine-tuning critical for production readiness, citing improvements in both accuracy and compliance6465.
The true frontier for AI is now episodic memory and continual learning. Language is not static and new events happen, policies change, user expectations shift. Without ongoing feedback and training, models slowly become outdated. With it, they improve the more you use them. Similar to how Tesla's fleet learning works for self-driving: more interactions, better AI 6667.
Resources
- RLHF paper - Learning to summarize from human feedback
- NVIDIA article on RLHF
- HuggingFace article on RLHF
- YouTube - HuggingFace livestream on RLHF
- YouTube - PPO Implementation From Scratch in PyTorch
- Transformer Reinforcement Learning (
trl) - Library by HuggingFace for reinforcement learning on transformers - Constitutional AI paper - Constitutional AI: Harmlessness from AI Feedback
- Lab 3 - Code example where FLAN-T5 is aligned using RLHF
Footnotes
-
Ouyang et al.: "Training language models to follow instructions with human feedback (InstructGPT)", arXiv, 2022 ↩
-
DeepSeek AI: "DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via RL", arXiv, January 2025 ↩ ↩2
-
CleverX Blog: "Supervised Fine-Tuning vs. RLHF", August 2025 ↩
-
CleverX Blog: "SFT vs RLHF: Training Approaches", 2025 ↩ ↩2 ↩3
-
CleverX Blog: "The Learning Process in SFT", 2025 ↩ ↩2 ↩3
-
CleverX Blog: "SFT Implementation", 2025 ↩
-
CleverX Blog: "RLHF Reward Mechanism", 2025 ↩ ↩2
-
CleverX Blog: "RLHF for Quality and Alignment", 2025 ↩ ↩2 ↩3
-
GDS Online Tech: "SFT vs RLHF in 2025", 2025 ↩
-
METR: "Recent Frontier Models Are Reward Hacking", METR Blog, June 2025 ↩
-
Hugging Face: "Fine-tuning LLMs with PEFT and RL (TRL + PEFT)", Hugging Face Blog, 2023 ↩
-
BentoML: "DeepSeek-R1 Pure RL Training", 2025 ↩
-
BentoML: "DeepSeek-R1 Refinement Process", 2025 ↩
-
BentoML: "DeepSeek-R1 Benchmark Performance", 2025 ↩
-
BentoML: "DeepSeek Model Capabilities", 2025 ↩
-
Meta AI: "Llama 4: Multimodal Intelligence", 2025 ↩
-
GPT-Trainer: "Llama 4: Evolution, Features, Comparison", 2025 ↩
-
Vktr: "Meta's Llama 4 Models Spark Momentum for Open-Source AI", 2025 ↩
-
Nature: "Reinforcement Learning in LLMs", Nature, 2025 ↩
-
Dai et al.: "Large Reasoning Models with RL Training", arXiv, 2025 ↩ ↩2 ↩3 ↩4 ↩5
-
Dai et al.: "Addressing Reasoning Challenges", arXiv, 2025 ↩ ↩2
-
Aman Anand Rai: "Beyond the Hype: 5 Counter-Intuitive Truths About AI from Andrej Karpathy", DEV Community, 2025 ↩
-
Aman Anand Rai: "Andrej Karpathy on RL Inefficiency", DEV Community, 2025 ↩ ↩2
-
Aman Anand Rai: "RL Reward Gaming Example", DEV Community, 2025 ↩
-
Analytics Vidhya: "10 AGI Myths Busted by Andrej Karpathy", October 2025 ↩ ↩2 ↩3
-
Aman Anand Rai: "Process-Based Supervision Needs", DEV Community, 2025 ↩
-
Niklaus et al.: "Not Ready for the Bench: LLM Legal Interpretation is Unstable", arXiv, 2025 ↩
-
Guha et al.: "Thinking Longer, Not Always Smarter: Hierarchical Legal Reasoning", arXiv, 2025 ↩
-
Zhang et al.: "SPIRAL: Self-Play Improves Reasoning with Language Models", arXiv, 2025 ↩
-
Lemma: "RL Environments for Legal Reasoning", 2025 ↩ ↩2 ↩3
-
Lemma: "Legal Data Advantages", 2025 ↩ ↩2
-
Guha et al.: "LegalBench: A Collaboratively Built Benchmark for Measuring Legal Reasoning in LLMs", NeurIPS 2023 ↩
-
Lemma: "Building RL Environments for Legal AI", 2025 ↩
-
Y Combinator: "Lemma Company Profile", YC S25 ↩
-
Lemma: "Legal Reasoning Transfer Learning", 2025 ↩ ↩2 ↩3
-
Lemma: "Expanding to Other Domains", 2025 ↩
-
Dai et al.: "LegalDelta: Enhancing Legal Reasoning in LLMs via RL", arXiv, 2025 ↩ ↩2 ↩3 ↩4 ↩5 ↩6
-
Dai et al.: "Legal Delta Framework", arXiv, 2025 ↩ ↩2 ↩3
-
Dai et al.: "Information Gain in Legal Reasoning", arXiv, 2025 ↩ ↩2
-
Chen et al.: "Unilaw-R1: Advancing Legal Reasoning with RL", EMNLP 2025 ↩
-
LRAS: "Legal Reasoning with Agentic Search", arXiv, 2026 ↩
-
LexPam: "Legal Mathematical Reasoning via RL", arXiv, 2025 ↩
-
Radiology Site: "Andrej Karpathy - It will take a decade to get agents to work", 2025 ↩
-
Radiology Site: "Karpathy on Memory Consolidation", 2025 ↩ ↩2
-
Radiology Site: "Context Window Limitations", 2025 ↩
-
Radiology Site: "Model Weight Updates for Memory", 2025 ↩
-
Zhang et al.: "CPPO: Continual Learning for RLHF", ICLR 2024 ↩
-
Zhang et al.: "CPPO Performance Results", ICLR 2024 ↩
-
Xu et al.: "COPR: Continual Human Preference Learning", arXiv, 2024 ↩
-
Xu et al.: "Optimal Policy Regularization", arXiv, 2024 ↩
-
Y Combinator: "Osmosis: AI Agents Continuous Learning", 2025 ↩
-
Y Combinator: "RunRL: Reinforcement Learning as a Service", 2025 ↩
-
Y Combinator: "RunRL Solution", 2025 ↩
-
Zhong et al.: "MemoryBank: Enhancing Large Language Models with Long-Term Memory", AAAI 2024 ↩
-
Zhong et al.: "MemoryBank Continual Evolution", AAAI 2024 ↩
-
Yan et al.: "Memory-R1: Managing Memories via Reinforcement Learning", arXiv, 2025 ↩
-
Xu et al.: "DPO Limitations", arXiv, 2024 ↩
-
Xu et al.: "Direct Preference Optimization Setup", arXiv, 2024 ↩
-
Hasan, Syed: "DAPO: Decoupled Clip and Dynamic Sampling Policy Optimization", Medium, 2025 ↩
-
Interconnects.ai: "GRPO Algorithmic Improvements", 2025 ↩
-
Interconnects.ai: "GRPO Clipping Hyperparameters", 2025 ↩
-
Turing.com: "RLAIF Explained: A Scalable Alternative to RLHF", 2025 ↩
-
GDS Online Tech: "RLHF for Safety Boundaries", 2025 ↩
-
GDS Online Tech: "Enterprise LLM Adoption Statistics", 2025 ↩
-
GDS Online Tech: "OpenAI's Reinforcement Fine-Tuning", 2025 ↩
-
GDS Online Tech: "Continuous Learning Best Practices", 2025 ↩
-
GDS Online Tech: "MLOps for LLMs", 2025 ↩