As a data scientist, one of the crucial aspects of your work is managing and storing datasets efficiently. CSVs may be common and handy when you want to share and read your data, but there are other file formats that are significantly more efficient in terms of speed and disk space.
In this article, I'll explore alternative file formats that can outperform CSVs, especially when dealing with larger datasets.
Performance Comparison
The data speaks for itself when comparing different storage formats across various dataset sizes:
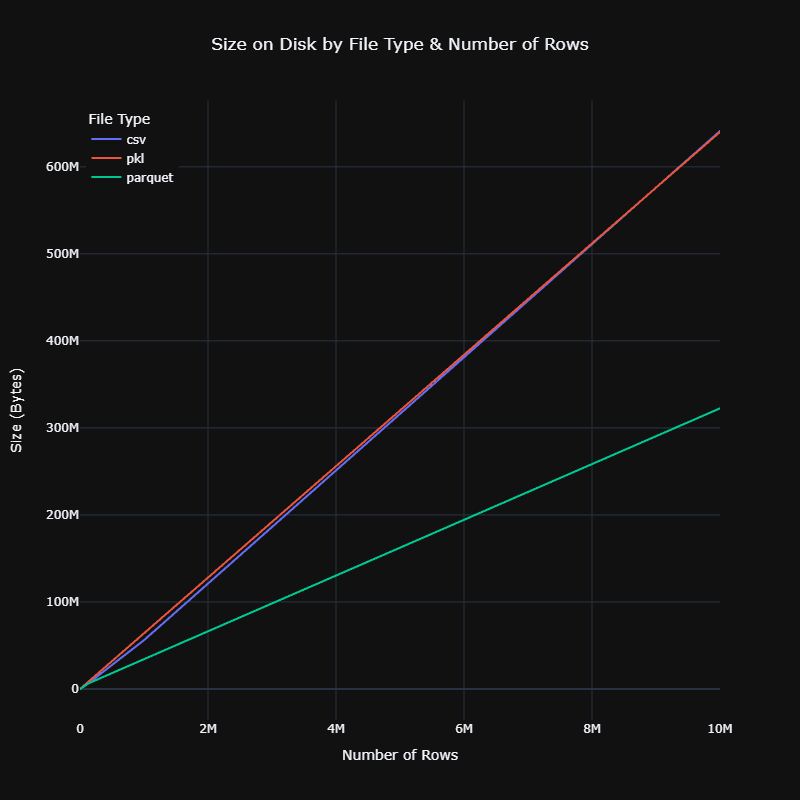
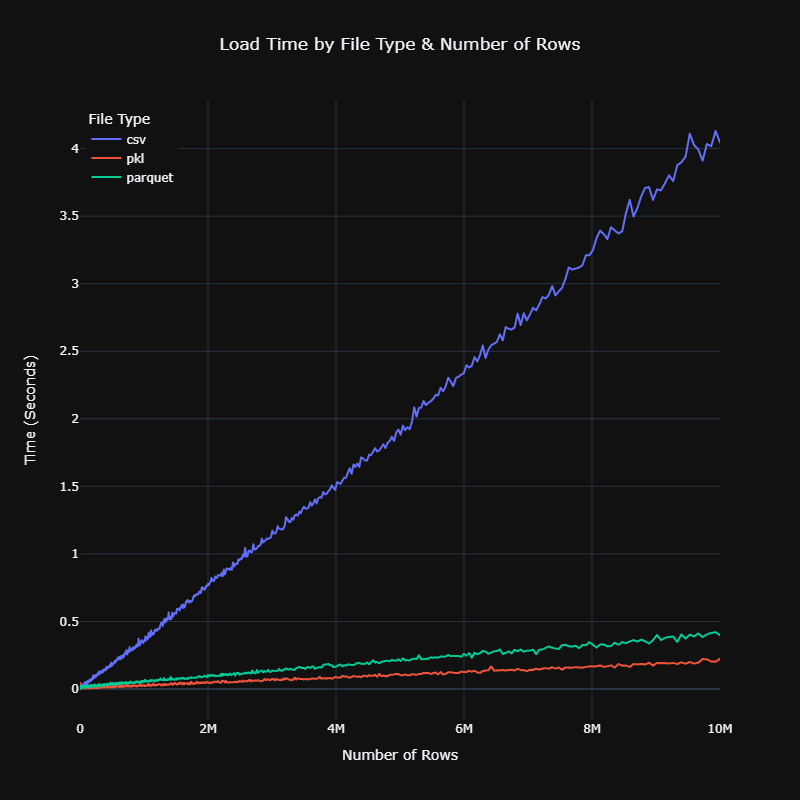
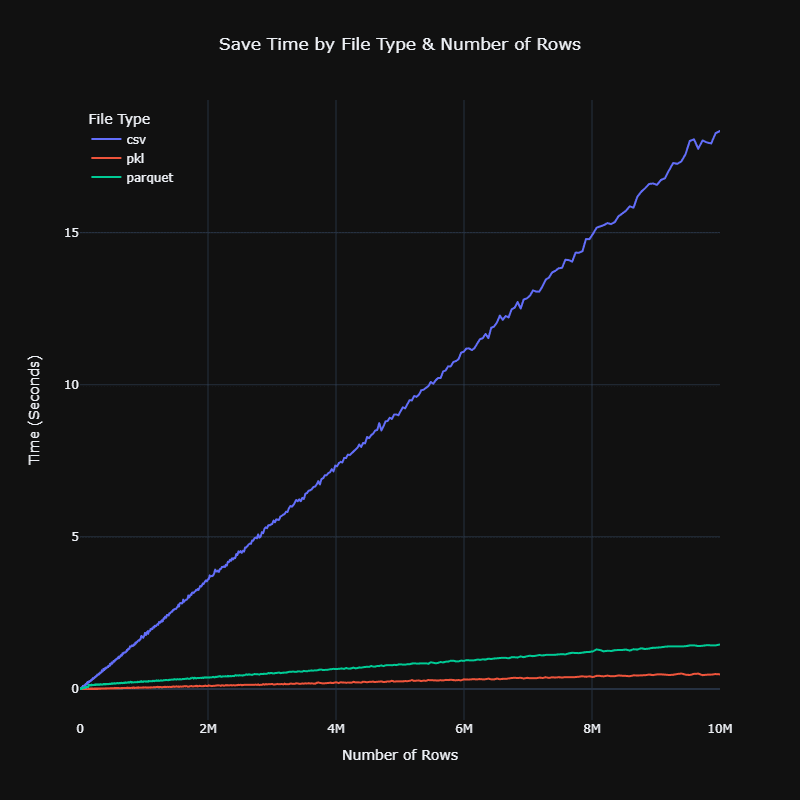
Binary Format Advantages
Binary formats like Pickle and Parquet offer enhanced performance for both reading and compression. The key differences are:
- Pickle: Significantly faster to read/write than CSVs, though file sizes remain similar
- Parquet: Excels in reducing disk space usage with superior compression
- Feather: Another alternative offering better compression than CSV
Both binary formats maintain your data types automatically, eliminating the need to specify column types during loading. This is a significant advantage over CSVs, which store everything as strings by default.
Parquet's Additional Benefits
For a little extra load time, parquet will save substantial space on disk. This becomes increasingly important when working with larger datasets.
Parquet also supports column-wise reading, making it more efficient for large datasets when you only need specific columns:
# load certain columns of a parquet file
master_ref = pd.read_parquet('./datasets/master_ref.parquet',
columns=['short_1', 'short_2'])This selective loading capability can dramatically reduce memory usage and load times for wide datasets.
Conclusion
CSVs may not always be the best option, especially for large datasets. Consider binary formats for better speed and compression - your future self will thank you when working with production-scale data.
The choice between formats depends on your specific needs: use Pickle for maximum speed, Parquet for optimal storage efficiency, and CSVs only when human readability or cross-platform compatibility is essential.