The AI community is shifting from prompt engineering - crafting the perfect string - to context engineering: treating the information environment around language models as a proper engineering problem.12
This matters because context engineering has become the bottleneck for reliable AI systems.3 Million-token windows promised to solve memory problems by letting us "just paste everything in," but they created new failure modes instead.
Loading tweet…
The solution isn't more tokens-it's treating LLMs as stateless functions and engineering context with the same rigor we apply to databases and APIs. Here's how to build context systems that actually work.
LLMs Are Stateless Functions
LLMs are stateless functions that transform inputs to outputs. This isn't just a mental model - it's how you need to treat these systems to build reliable AI.
Unlike traditional software that maintains state across calls, every LLM invocation starts fresh. The model has no memory of previous interactions, no persistent variables, no accumulated context beyond what you explicitly provide in the current prompt. This statelessness is actually a feature, not a bug-it makes LLMs predictable, debuggable, and scalable.
Everything is context engineering. LLMs are stateless functions that turn inputs into outputs. To get the best outputs, you need to give them the best inputs. - Hammad Shahid, Chroma CTO
This changes everything:
- State must be externalized - All memory, history, and context lives outside the model
- Context becomes your API - The prompt is your interface to model capabilities
- Information architecture matters - How you structure context determines output quality
- Persistence is a system design problem - Not something the model handles internally
Modify context between turns: summarize, prune, or re‑frame to reduce latency, cost, and drift. Shorter, focused prompts outperform long, drifting ones in multi‑turn conversations.
Why Long Context Fails
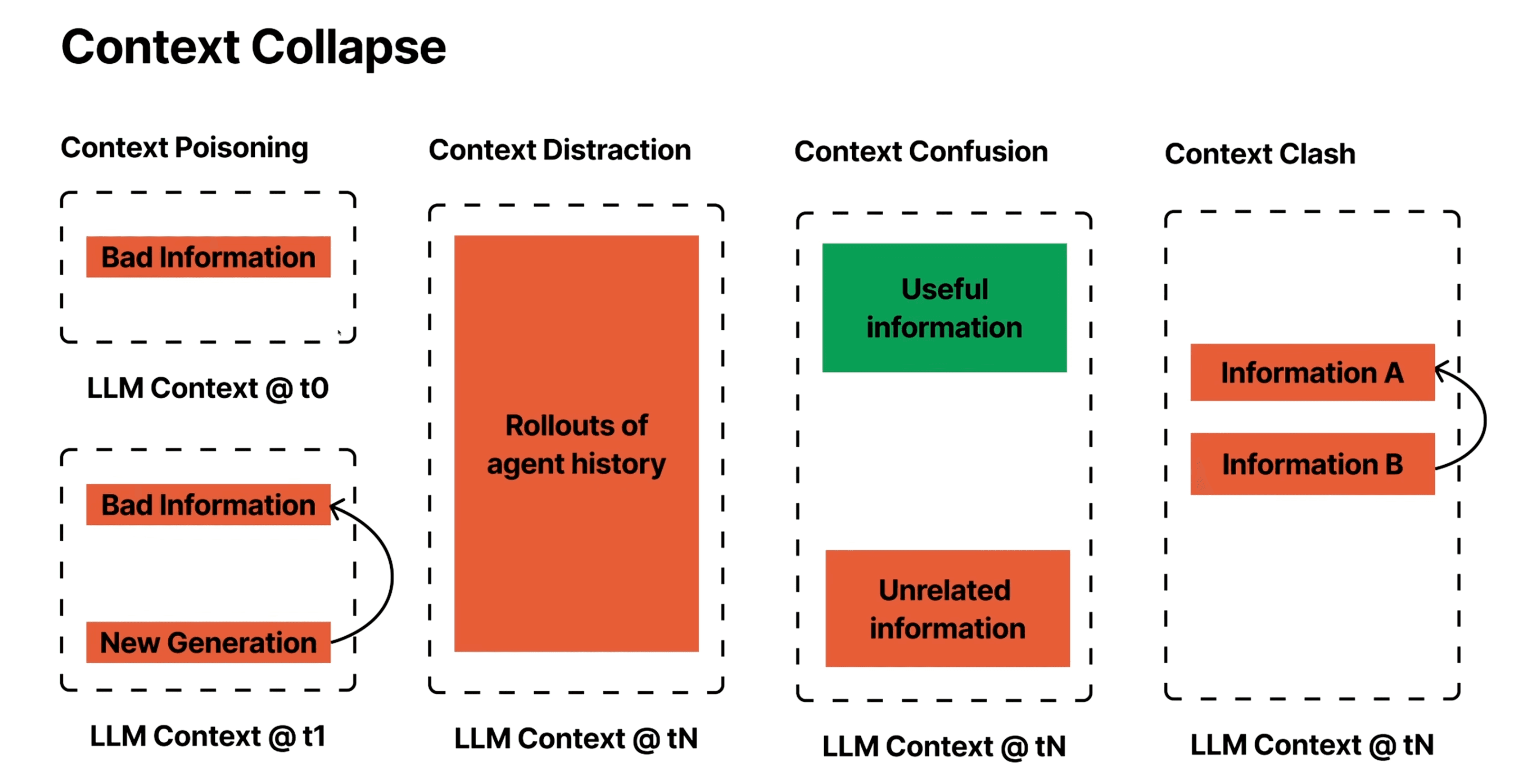
Million-token windows feel like a cheat code-until you try them out and they fail hard. There are four main ways they break:4
Context Poisoning happens when hallucinated information enters the context and persists as "truth." The Gemini 2.5 Pokémon agent demonstrated this perfectly: after hallucinating an impossible goal early in play, it became fixated on pursuing that imaginary objective across hundreds of subsequent turns.5 The poisoned context created a feedback loop where the model treated its own errors as ground truth.
Context Distraction happens when contexts grow too long. Instead of making new plans, models start repeating old actions from their history. Databricks found quality drops around 32k tokens for Llama-3.1-405B, with smaller models failing earlier.6 The model gets "drunk" on its own context.
Context Confusion happens when irrelevant information misleads the model. The Berkeley Function-Calling Leaderboard shows accuracy dropping as tool counts rise-models call wrong tools when none apply.78 A Llama-3.1-8B failed with 46 tools but worked with 19. The issue wasn't space-it was overload.
Context Clash happens when contradictory information creates conflicts. Researchers found "sharded" prompts (information gathered across multiple turns) cause a 39% performance drop on average, with OpenAI's o3 falling from 98.1 to 64.1.9 When models take a wrong turn, they get lost and don't recover.
These failure modes hit hardest in exactly the scenarios where long contexts seemed most promising: multi-turn reasoning, document analysis, and complex agent workflows. The very applications that drove demand for million-token windows are where they perform worst.
If you want a deeper foundation:
- Comprehensive agent patterns are detailed in 12‑Factor Agents and covered throughout this post.67
- For retrieval mental models and vector DB trade‑offs, see Hammad's Chroma talk on Context Engineering.8
What Context Engineering Is
Context engineering isn't about writing better prompts-it's about building systems that provide the right information and tools, in the right format, at the right time.10 Think of it as information architecture for AI. usually this means:
- System Instructions set the model's role, tone, and behavior. These guidelines influence everything the model does, so craft and test them carefully.
- User Input anchors the context to the current goal. This isn't just the raw query-it's often cleaned up and rewritten for the model.
- Conversation History provides continuity across turns, but only the relevant slice. Raw chat logs create noise; structured event logs preserve meaning while reducing tokens.
- Retrieved Knowledge supplies domain information through targeted RAG, not document dumps. You want precise, relevant snippets that support the current task.
- Tool Definitions describe available functions and APIs, but only those likely needed. Too many tools cause confusion.
- Environmental State captures what's happened so far in structured formats. This includes results, decisions, and open questions-the system's "working memory."
How to Handle State
Given LLMs stateless nature and that all memory should be externalized, persistence architecture becomes critical-the foundation that makes context engineering work at scale.
Threads and Checkpoints
LangGraph for example use a thread-based model where each conversation gets a unique identifier. Within each thread, checkpoints capture system state at each step-like Git commits for AI workflows.
# Every AI interaction requires a thread context
config = {"configurable": {"thread_id": "conversation_123"}}
result = agent.invoke(user_input, config)
# State is automatically checkpointed at each step
state_snapshot = agent.get_state(config)
# Returns: values, next_actions, metadata, created_at, parent_configThis checkpoint system enables:
- Human-in-the-loop workflows where agents pause for approval and resume where they left off. State persists across interruptions.
- Time travel and debugging by replaying execution from any checkpoint. You can fork conversations at decision points to explore alternative paths.
- Fault tolerance where failed operations don't lose progress. Systems restart from the last successful checkpoint.
- Memory between interactions where follow-up messages retain context from previous conversations in the same thread.
Cross-Thread Memory
What about information that persists across threads? A customer service AI should remember user preferences across all conversations. This requires a store layer-persistent memory above individual threads.
# Store user preferences across all conversations
user_store = InMemoryStore()
user_id = "customer_456"
namespace = (user_id, "preferences")
# Write persistent facts
user_store.put(namespace, "food_preference", {"likes": "pizza", "dislikes": "olives"})
# Retrieve in any thread
preferences = user_store.search(namespace, query="dietary preferences", limit=3)The store supports semantic search over memories, letting natural language queries find relevant information across stored context. This creates "institutional memory" for AI systems.
Connecting Storage and Context
The key insight is that persistence and context engineering work together. Persistence provides the durable storage layer, while context engineering determines what subset of that stored information to include in each prompt.
A well-designed system should:
- Store everything in the persistence layer with rich metadata
- Retrieve selectively based on current query and relevance scoring
- Assemble contextually using structured formats optimized for the model
- Update continuously as new information becomes available
This separation of concerns-durable storage vs. working memory-is what enables AI systems to scale beyond toy demos into actual production applications.
Practical Fixes
Use RAG Properly
Pull only the facts you need per turn; don't paste manuals. Long context underperforms targeted retrieval because models summarize your dump and ignore your instructions.3
// RAG skeleton
const q = rewriteForSearch(userQuery); // normalize intent
const hits = await kb.search(q, { k: 3, filters });
const prompt = assemble({ instructions, userQuery, snippets: hits });
const result = await llm(prompt);Tips:
- Keep chunks short and labeled (source, date, doc id)
- Filter by policy (privacy, recency) before inclusion
- Use summaries over raw dumps-even if you have room
Limit Your Tools
Give agents a small list of tools per task. Accuracy drops as tool count rises, and models call wrong tools when none are needed.45
// Select tools by semantic match + coverage
const candidates = allTools.filter(
t => similarity(t.description, userQuery) > 0.45
);
const loadout = rankByCoverage(candidates).slice(0, 4);
const prompt = assemble({ loadout, ... });Use cases:
- Swap loadouts per domain (billing vs. deployment)
- Gate high‑stakes tools behind explicit human approval
Isolate Sub-Contexts
Split work into micro-agents with clean threads and reunite via summaries. This avoids clash and reduces distraction.6
// Isolated threads
const analysis = await analyst.run({ docChunk }); // its own context
const plan = await planner.run({ goal, constraints });
const merged = merge([analysis.summary, plan.actions]);Pattern:
- Supervisor coordinates; specialists work in separate contexts
- Exchange summaries, not entire transcripts
Prune Context
Drop stale steps, failed attempts, duplicate errors, and irrelevant turns. Keep a sliding working set-nothing else. You dont need to keep passing in an error from 5 turns ago to help the LLM on the current step.
- thread.push({ type: "tool_error", detail })
+ thread = prune(thread, {
+ keepTypes: ["decision", "result", "open_question"],
+ maxTokens: 4_000
+ })Heuristics:
- Prefer latest decision over earlier drafts
- Keep unresolved questions; drop resolved ones
- Hide resolved errors after recovery
Compress History
When you must keep it, compress it. Preserve decisions, constraints, rationale, and open questions-skip chit-chat.
// Rolling summaries
const [head, tail] = splitAtTokenBudget(thread, safeWindow);
const synopsis = await llm.summarize(head, DecisionLogSchema);
const context = assemble({ synopsis, tail });Watch out:
- Bad summaries become new ground truth. Add a verifier pass for critical threads.
Pre-Fetch When You Can
If step N+1 will likely need data X, pre-fetch it deterministically - don't waste a round-trip asking the model to ask you.7
// Deterministic pre-fetch
thread = { events: [initial] }
- next = await decideNextStep(thread)
+ const tags = await git.listTags()
+ next = await decideNextStep({ ...thread, tags })Or model the fetch explicitly so the LLM sees both request and result:
+ thread.events.push({ type: "list_git_tags" })
+ const tags = await git.listTags()
+ thread.events.push({ type: "list_git_tags_result", data: tags })Rule of thumb:
- Pre-fetch when (a) cheap, (b) stable, (c) >70% likely you'll need it
- Otherwise keep it retrievable to avoid distraction
Use Small Agents
Large "loop-until-done" agents get lost after 10–20 steps. Break work into small agents (3–10 steps each), with deterministic glue code for approvals, retries, and handoffs.6
Worked example: Deploybot (Humanlayer OSS)
- Human merges PR → deterministic code deploys to staging and runs e2e tests
- Agent takes over for production with context “deploy SHA 4af9ec0 to production”
- Agent proposes
deploy_frontend_to_prod(4af9ec0)→ approval required - Human: “deploy backend first” →
deploy_backend_to_prod(4af9ec0) - Approvals, execution, post‑deploy tests, done/rollback as needed6
<!-- Own the context window with structured events -->
<slack_message from="@alex">Deploy backend v1.2.3 to production?</slack_message>
<list_git_tags />
<list_git_tags_result>
v1.2.3 abc123; v1.2.2 def456; v1.2.1 ghi789
</list_git_tags_result>
<request_human_input
urgency="high"
format="yes_no"
question="Proceed with prod deploy?"
context="Production deploy affects live users."
/>
<human_response approved="true">yes please proceed</human_response>
<deploy_backend tag="v1.2.3" env="production" />
<deploy_backend_result status="success" at="2024-03-15T10:30:00Z" />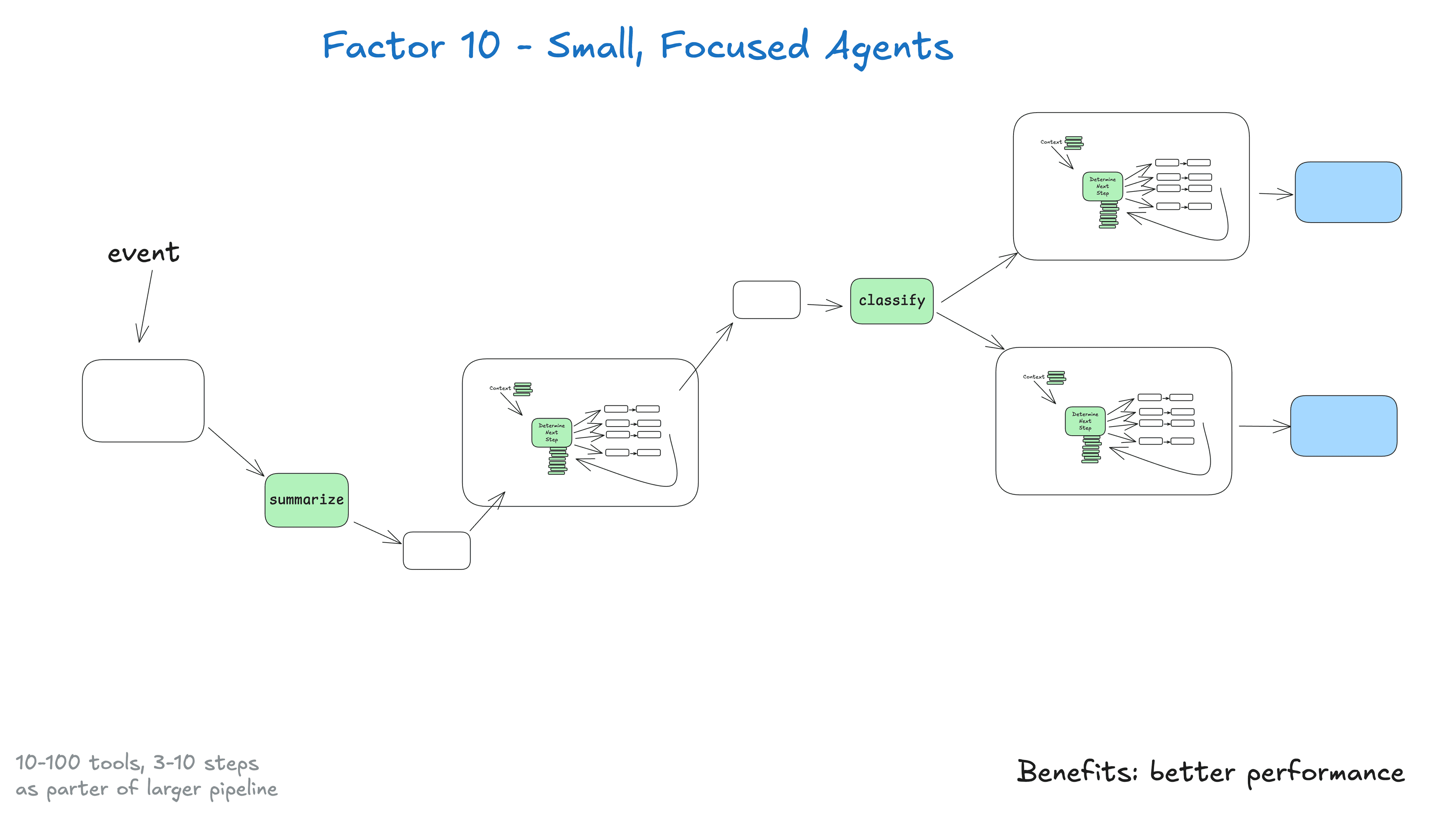
12-Factor Agents: Systematic Design Patterns
The techniques above can be systematized into a comprehensive framework. The 12-Factor Agents principles provides structured patterns for building reliable context systems:
Factor 01 - Natural language → tool calls. Ask the LLM for structured JSON (your code switches on intent 6) and pass over to deterministic code.
Factor 02 - Own your prompts. Treat prompts as code (versioned, tested, evaluated). BAML/templating is fine; the point is control.6. Dont abstract away your prompts
Factor 03 - Own your context window. Custom formats (XML/JSON blocks), compact encoding, and role hacks where helpful.6
Factor 04 - Tools are structured outputs. “Tool calling” is just structured output your switch‑statement handles-including side‑effects, retries, approvals.
Factor 05 - Unify execution & business state. Make the thread (event log) your source of truth. Benefits: simplicity, serializability, pause/resume, forkability, easy UIs.
Factor 06 - Launch/Pause/Resume. Break the loop between selection and invocation to allow approval and long‑running ops.
Factor 07 - Contact humans with tools. Return JSON; include intents like request_human_input or done_for_now as first‑class tool calls.
Factor 08 - Own your control flow. Inline policies for summarization, caching, LLM‑as‑judge on structured outputs, compaction, rate‑limiting.
Factor 09 - Compact errors. Add formatted errors to context, retry ≤ N, then escalate to human or re‑route. Hide resolved errors to avoid distraction.
try {
const res = await handle(next);
consecutiveErrors = 0;
} catch (e) {
if (++consecutiveErrors < 3) {
thread.events.push({ type: 'error', data: formatError(e) });
} else {
escalate(thread);
}
}Factor 10 - Small, focused agents. As detailed in the "Use Small Agents" section above - scope to 3–10 steps.
Factor 11 - Trigger from anywhere. Slack/email/webhooks/cron in; respond via same channels. Meet users where they are. Enables outer‑loop agents that contact humans only at critical points.
Factor 12 - Stateless reducer. Treat the agent as a reducer over the event log.
Appendix / Factor 13 - Pre‑fetch. As covered in the pre-fetch section above, deterministically fetch likely-needed data.7
Mental Models for Context Systems
The practical techniques above work better when you have mental models to help you reason about failures and design more effective context systems. I'm not saying LLMs work like this, but sometimes it is handy to conceptualise like this.
Information Theory Model
Context engineering is signal-to-noise optimization. Let Y be your desired output and C be your context:
C = R (relevant) + S (statistically independent) + N (noisy/contradictory)
Effective context engineering:
- Maximizes R, Relevance through better retrieval and relevance scoring
- Minimizes S by filtering irrelevant information
- Eliminates N through conflict detection and resolution
- Optimizes I(C; Y) - the mutual information between context and output
This framework draws from information theory principles applied to machine learning systems. Track relevance scores of retrieved documents, measure how often wrong tools are called, and detect contradictions in your context assembly.
Database of Programs Model
François Chollet treats LLMs as databases of learned programs. The model has internalized thousands of composable "programs" during training-things like "rewrite in style X," "summarize technical content," or "plan a workflow."
Context engineering becomes snapping the model into the right program. Your context provides the activation signal that selects the right behavior. This explains why:
- Structured formats work better - they provide clearer activation signals
- Examples are powerful - they demonstrate the program you want to invoke
- Consistency matters - mixed signals confuse program selection
Chollet explores these ideas in depth in his paper "On the Measure of Intelligence", where he discusses how intelligence emerges from the composition of learned programs.
State Recreation Model
Marvin Minsky's insight applies to AI systems: "The function of memory is to recreate a state of mind." Your context isn't just storing information-it's reconstructing the mental state needed to solve the problem.
This explains why summaries and structured logs work so well. They don't just compress information; they preserve the mental state that enables problem-solving. When you resume a conversation from a checkpoint, you're recreating the problem-solving context.
Minsky elaborated on this concept in "The Society of Mind" (1986), where he explored how memory systems work to reconstruct cognitive states.
Internal Optimization Model
Recent research suggests that large language models may run optimization processes during inference. Later layers might search over possible responses, guided by your context.
If true, this changes context engineering:
- Sampling-based scaling becomes more powerful - run multiple parallel inferences and let the model rank them
- Contrastive verification works better than absolute judgments - models are better at choosing between options than evaluating single responses
- Search space design matters - your context defines what the internal optimizer can explore
This approach aligns with research on process supervision and verification methods, where models are trained to evaluate and rank different solution paths.
What This Means
These mental models suggest concrete strategies:
- Generate multiple candidates and rank instead of single long reasoning chains. Create several responses and use the model to select the best one. This technique is supported by research on best-of-N sampling and verification-guided decoding.
- Design activation patterns in your context format. Use consistent structures that clearly signal what type of processing you want.
- Invest in outer-loop learning. Store reasoning traces, analyze what context configurations worked, and feed those insights back into your retrieval and assembly systems.
- Measure information density. Track how much of your context actually influences the output, and prune the rest. This connects to work on context compression and attention analysis in transformers.
Learning from Usage
The biggest performance gains come not from perfect initial design, but from learning and improving over time. This is the "outer loop" - using production data to continuously refine how you assemble and deliver context.
The Data Flood
As model inference speeds increase from hundreds of tokens per second to hundreds of kilohertz, we'll generate huge volumes of reasoning traces. Organizations will easily generate gigabytes to terabytes of reasoning traces per day.11
This creates both opportunity and challenge. The opportunity: insight into what context configurations actually work. The challenge: building systems to capture, process, and learn from this data flood.
Test-time scaling becomes practical when models are fast enough. Instead of one long reasoning chain, generate dozens of parallel attempts and select the best. Store successful paths as reusable "skills" for future contexts.
Sampling-based scaling leverages models' comparative judgment. Rather than asking "is this response good?" (which models handle poorly), generate multiple candidates and ask "which is best?" Models excel at ranking tasks.
IO stalls emerge as the new bottleneck. When models generate at hundreds of kilohertz, tool calls and retrieval become the limiting factor. You'll need to budget latency carefully-setting SLAs for different context assembly operations.
Build Learning Systems
The most successful AI systems learn from their own usage patterns. This requires infrastructure to:
- Capture everything - reasoning traces, context configurations, user feedback, success/failure signals. You can't improve what you don't measure. This aligns with principles from "Hidden Technical Debt in Machine Learning Systems" about monitoring ML systems.
- Segment and analyze - which context patterns led to successful outcomes? What types of retrieved documents were actually useful? When do certain tool combinations work well together?
- Index and mine - turn raw traces into searchable, analyzable datasets. Build embeddings over successful context patterns so you can find similar situations.
- Feed back improvements - update retrieval rankings, refine summarization strategies, adjust tool selection heuristics based on what you've learned.
Early examples like Reflexion show how models build libraries of useful patterns over time12. The Voyager project demonstrates agents that automatically generate curricula based on what they've learned to do successfully13.
What to Measure
- Interventions per token - like "interventions per mile" in autonomous vehicles, this measures how often human oversight is needed per unit of AI work.
- Retrieval precision@k - what percentage of retrieved documents actually influence the final output? Track this to optimize your search and ranking systems.
- Tool efficacy rates - right tool selected, correct parameters provided, successful execution. Monitor these to refine tool selection algorithms.
- Context size vs. quality curves - find your model's "distraction ceiling" where additional context starts hurting performance rather than helping.
- Approval latency - for high-stakes actions requiring human approval, how quickly can you get decisions? This often becomes the bottleneck for production systems.
The most important metric: context helpfulness. Log which documents, tools, and context elements were included in each response, then track whether they actually contributed to success. Your learned ranking models will quickly outperform hand-crafted heuristics.
The Ecosystem
Context engineering is spawning its own ecosystem of tools, frameworks, and organizational practices. Understanding these trends helps you build systems that will remain relevant as the field matures.
Context Platforms
We're seeing the emergence of dedicated context management layers that sit between users and LLMs. These platforms handle retrieving documents, querying databases, invoking summarizers, and sequencing tool calls before assembling the final prompt.
Instead of user queries hitting the LLM directly, they first pass through a context orchestration pipeline that might:
- Check which internal knowledge bases to query
- Pull top results and sanitize sensitive content
- Fetch user profile preferences and past interactions
- Assemble structured context using learned templates
Companies are building internal "context platforms" that unify access to all enterprise data-Confluence pages, SharePoint documents, Slack threads, customer databases-and inject relevant portions into LLM prompts on demand.
Better Agent Frameworks
Early agent frameworks treated context crudely, often just appending interactions to a message list and truncating when hitting limits. Newer frameworks give developers fine-grained control over context assembly.
DSPy lets you declaratively specify what context to include for each function call or dialogue state. LangGraph demonstrates building agents with all the "fix your context" tactics built-in-retrieval, tool filtering, sub-agent isolation, and memory management.
The key trend: frameworks are treating context assembly as a first-class citizen rather than hiding it behind opaque abstractions.
Context Formats
There's growing experimentation in how context is represented to models. While the standard OpenAI format uses role-based messages (system/user/assistant), many practitioners are moving toward custom structured formats.
Some report better consistency when tool outputs are enclosed in special tags, making it clear to the model what was generated by tools versus humans. Others find that merging roles into a single comprehensive user prompt saves tokens and reduces the chance of models ignoring system directives.
Prompt compression techniques are emerging for extremely large contexts-representing repetitive data as abstracts, using bullet points instead of prose for factual information, and developing learned encoders that compress knowledge bases into optimized prompt representations.
What You Can Build
- Acquire the "weird" context. The most valuable organizational knowledge often lives in tacit processes-what Hammad calls the "archaic ritual" of monthly compliance meetings or undocumented decision-making flows. Capture meetings, add lightweight forms, use supervised tagging to promote tribal knowledge into queryable facts.
- Build clean export surfaces. Provide typed, privacy-aware APIs and embeddings so other applications can safely consume your domain context. This becomes critical as AI systems need to communicate across organizational boundaries.
- Design agent-to-agent protocols. Move beyond simple ask/answer patterns toward negotiated exchanges where agents specify their capabilities, needs, and constraints:
{
"capabilities": ["invoices.search", "invoices.pay", "contracts.analyze"],
"need": [
{
"kind": "contract",
"fields": ["id", "terms", "counterparty", "expiry"]
}
],
"constraints": {
"latency_ms": 500,
"pii_policy": "mask_ssn",
"confidence_threshold": 0.85
},
"response_schema": { "$ref": "#/components/schemas/ContractSummary" }
}This enables more sophisticated context sharing where the receiving agent can transform and optimize data for the requesting agent's specific needs.
What's Next
Context engineering represents a shift in how we build AI systems. We're moving from the "magic prompt" era toward systematic information architecture-treating context as a first-class engineering artifact that requires the same rigor we apply to databases and APIs.
The Future
- Smarter models won't eliminate context engineering - they'll make it more important. Even as models get better at handling complex contexts, the core challenge of thoughtful information curation becomes more critical, not less.
- Organizational transformation will accelerate as companies realize AI effectiveness depends on data quality and accessibility. Context engineering exposes data silos, inconsistent documentation, and poor knowledge management. Investing in context systems means investing in organizational intelligence.
- New roles are emerging: AI context engineers, knowledge architects, and prompt platform engineers. These roles bridge traditional software engineering with information science, focusing on how to structure and deliver knowledge to AI systems.
- Standards and tooling will mature rapidly. Just as web development moved from hand-crafted HTML to sophisticated frameworks, context engineering is evolving from ad-hoc prompt tweaking toward systematic platforms and methodologies.
Key Principles
- Context is your API to intelligence. The information you provide determines the quality of reasoning you get back. Engineer that information with the same care you'd design any critical system interface.
- Structure beats volume. Three highly relevant, well-formatted snippets outperform thirty pages of raw text. Focus on signal, not size.
- Build learning systems. The best context engineering isn't static-it improves over time by learning from production usage patterns and user feedback.
- Start small, measure everything. Begin with simple retrieval and tool selection, then systematically optimize based on real performance data.
The future belongs to teams that understand this shift and invest in the infrastructure to support it. Context engineering is no longer optional.
Footnotes
-
Drew Breunig: "How Long Contexts Fail", 2025 - Taxonomy of context failure modes: poisoning, distraction, confusion, and clash. ↩
-
Drew Breunig: "How to Fix Your Context", 2025 - Six practical techniques for context engineering: RAG, tool selection, quarantine, pruning, summarization, and offloading. ↩
-
Tobi Lütke & Andrej Karpathy: Context engineering tweets, 2025 - Lütke and Karpathy on context engineering as the next critical AI skill. ↩ ↩2
-
Drew Breunig: "How Long Contexts Fail", 2025 - Context failure taxonomy and empirical evidence. ↩ ↩2
-
Google DeepMind: "Gemini 2.5 Technical Report", 2025 - Context poisoning examples in the Pokémon agent section. ↩ ↩2
-
Databricks: Long-context study on Llama-3.1-405B showing quality degradation beyond ~32k tokens, 2025. ↩ ↩2 ↩3 ↩4 ↩5 ↩6 ↩7 ↩8
-
UC Berkeley: "Berkeley Function-Calling Leaderboard" - Empirical evidence of tool-use accuracy declining as tool counts increase. ↩ ↩2 ↩3 ↩4
-
UC Berkeley: "Announcing v3 of BFCL: Real-world AST", 2025 - "Live (AST)" columns showing real-world tool performance. ↩ ↩2
-
P. Laban et al.: "LLMs Get Lost in Multi-Turn Conversation", 2025 - Sharded prompt study showing 39% average performance drop (o3: 98.1 → 64.1). ↩
-
Philipp Schmid: Context engineering definition as "designing and building dynamic systems that provide the right information and tools, in the right format, at the right time," 2025. ↩
-
Hammad Shahid (Chroma CTO): "Context Engineering", 2025 - Test-time scaling, sampling-based scaling, IO stalls, and outer-loop data operations. ↩
-
Reflexion: Language Agents with Verbal Reinforcement Learning: "Reflexion: Language Agents with Verbal Reinforcement Learning" by Shinn et al., 2023 - Shows how agents can learn from verbal feedback and build libraries of useful patterns over time. ↩
-
Voyager: An Open-Ended Embodied Agent with Large Language Models: "Voyager: An Open-Ended Embodied Agent with Large Language Models" by Wang et al., 2023 - Demonstrates agents that automatically generate curricula and skill libraries based on successful experiences in Minecraft. ↩