Defensive technology refers to the development of systems designed to protect against significant threats posed by technological advancements. It is based on the premise that leveraging advanced tech is often the most effective way to mitigate technological risks. In Vitalik Buterin’s words:
"There are certain types of technology that much more reliably make the world better than other types of technology. There are certain types of technology that could, if developed, mitigate the negative impacts of other types of technology."
This proactive approach focuses on strengthening our defences to ensure that technological innovations benefit society as a whole. With the rapid pace of AI development in recent years, the potential for misuse or unintended consequences has increased. By anticipating and countering these risks, defensive technology provides a safety net that allows us to pursue advancements in AI without compromising safety and security.
In this article, I'll explore the various risks associated with AI and identify specific defensive technologies that can protect us from these threats. By taking a defensive acceleration approach, we can ensure that the innovations of the 21st century lead to a prosperous and secure future for all of us!
Situational Awareness & Cybersecurity
Recently, I’ve been deeply affected by Leopold Aschenbrenner’s stance on "situational awareness". It broadened my understanding of the risks posed by emerging AI capabilities. As a developer, it's easy to focus solely on the technical aspects of AI, overlooking the broader geopolitical and security implications. Aschenbrenner's key perspective relevant here to this article was the urgent need for defensive technologies to mitigate the risks associated with advanced AI, AGI (Artificial General Intelligence), and ASI (Artificial Superintelligence). If you want to read more on what I took from Situational Awareness in general, you can find them in another blog post. However, in terms of defensive technology, here are some key ones that came to mind:
- Investment in Cybersecurity: One of the most striking revelations is the critical lack of investment in cybersecurity, especially for AI startups. Aschenbrenner points out that this oversight leaves these companies vulnerable to national-level espionage attacks. Robust cybersecurity measures are essential to safeguard against these threats, particularly as AI technologies become more capable. But this is also usually the last concern for startups that are trying to fail fast and iterate quickly.
- Comprehensive AI Security and Surveillance Systems: We need these systems for protecting sensitive AI projects and algorithmic advancements, which is our alpha in the scenario in which we are in a race to ASI on a multi-national stage. We need secure environments where researchers can work without fear of security breaches.
- Real-time Threat Detection: Currently, the technology to identify potential security breaches and threats in real-time is lacking, particularly for startups. Implementing real-time monitoring and response mechanisms is crucial to prevent and address suspicious activities within AI development environments.
- Hardware-Based Security Features: There is a significant gap in the use of hardware-based security features to protect data and algorithmic advancements. Sensitive information, like model weights, can easily be stolen by a rogue employee using something as simple as a USB drive; Grok-1 Open weights can fit on one with 30GB of space for example. Strengthening hardware security to prevent unauthorized data extraction is needed to protect valuable AI assets as they become more sophisticated.
- Private Sector Responsibilities: Unlike the public sector, the private sector often lacks stringent security measures, such as employee vetting. AI startups will need to adopt these rigorous security protocols to protect against internal and external threats. Or nationalise the ASI effort, but then this becomes a totally different discussion.
Malicious AI Models
Even established platforms like Hugging Face are not immune to security threats. Recently, malicious AI models were discovered capable of executing code on victims' machines and providing attackers with persistent backdoor access. This incident shows a need for increased wariness, but also potentially automated tech to detect and neutralize malicious models to safeguard the open-source ecosystem.
Agentic Platforms
The adoption of agentic platforms is increasing. Recently, frameworks like LangChain's LangGraph allow for building complex, scalable AI agents using graph-based state machines. Leopold also notes that Agent adoption will only get increase with unhobbling and better models. But they present novel and unpredictable risks as well; the tech is so new that we just don't fully understand all the potential risk modes. For example, adversarial self-replicating prompts, like the AI worm, can spread from one system to another, potentially stealing data or deploying malware.
As adoption increases, we have time to address these risks before treating risk modes on an ad-hoc basis. We need technology for performing automated red team evaluations of these systems, testing them in real-world scenarios to uncover vulnerabilities. However, relying solely on automation for red teaming poses its own risks, as it may also reduce the diversity and effectiveness of these evaluations. It is interesting to note that an agentic approach to red teaming could ironically be the best way to evaluate these systems.
Bias & Misalignment
One thing that genuinely scares me is the centralisation of AI power, and the potential for bias and misalignment that comes with it. People should be as concerned as I am that only a small number of entities (ahem, OpenAI) have the unhindered ability to engineer biases into their consumer-facing models, whether intentionally or unintentionally.
One of the most concerning relevant recent incidents is the whole Google Gemini fiasco, which highlighted the above, but also, difficulties even major tech companies (even self proclaimed "AI-first Companies") face in managing biases and misalignment within their models. Despite Google's resources, the Gemini model was found to be pretty controversial. For example, in an attempt to compensate for skewed data, the model was engineered to always generate diverse representations of people, even when this made no sense. This was evident through simple prompts, not even adversarial ones. This poorly executed strategy led to unnatural and forced diversity outputs:

@TheRabbitHole84 on X also showed some questionable outputs when prompted with controversial questions, such as "Is it okay to misgender Caitlyn Jenner to stop a nuclear apocalypse?"

The complexity of ensuring ethical AI behaviour is a significant risk this decade as we begin integrating these models into important workflows, such as hiring, medicine, credit scoring, and even the judicial system. OpenAI's GPTs, were found to systematically produce biases based on names. This represents a serious risk for automated discrimination at scale, despite efforts to mitigate bias and increase objectivity.
Google's approach to handling risk cases is also worth talking about. It has been a reactive "whack-a-mole" strategy, addressing problems as and when they arise rather than proactively preventing them. We are only doing something about it after the damage is already done. Thankfully, no-one was sentenced to prison or diagnosed based on these outputs, but we cannot afford to wait for these issues to manifest in higher-stakes environments. We need better technology in place to enumerate and predict these risk modes.
This situation also illuminates the shortcomings of our current alignment methods. Google's approach to patching issues with skewed datasets through system prompting fails to address the underlying causes of misalignment. While we can absolutely align away problems in production, this is just an outward manifestation of the deeper problem. The fundamental misalignment of the base model remains unresolved.
In short, the inability to anticipate and enumerate risk modes is a significant flaw in our current technology.
Reinforcement Learning from Human Feedback (RLHF)
To address the growing number of risk modes, we need improved technologies that can predict and pre-emptively mitigate potential biases and misalignments in deployed AI systems. This involves developing better alignment frameworks that go beyond the limitations of current methods like Reinforcement Learning from Human Feedback (RLHF).
RLHF relies on humans being able to understand and supervise AI behaviour, which fundamentally won’t scale to more capable systems. Say, when we are working with complex outputs such as millions of lines of code. If you asked a human rater in an RLHF procedure, "does this code contain any security back-doors?", they simply wouldn't know the answer. This isn't far off either. On top of this, Claude 3 was allegedly aware of being tested in the needle-in-the-haystack eval. If this is taken at face value, what is stopping systems aware of being tested from gaming the alignment procedure?
Developing technology and systems that can align properly with human preferences is crucial for maintaining trust and effectiveness in AI applications.
Open Source and Transparency in AI
Another thing to think about is the lack of transparency from major tech companies like Google and OpenAI when it comes to their models. Should there be mechanisms in place for independent researchers to evaluate these models? Top AI researchers have been advocating for generative AI companies to allow independent access to their systems, arguing that strict protocols are hindering safety-testing and independent evaluations.
Also, what about open-source? It doesn't necessarily have to mean unregulated or unmonitored either. The open-source community has a robust tradition of establishing standards and protocols for the safe development, distribution, and use of software. This includes mechanisms for flagging and addressing misuse, much like how open-source software communities manage vulnerabilities and bugs. By applying these principles to AI, we could potentially ensure that the development and deployment of more competent LLMs is conducted responsibly.
A perfect example of this concept from earlier this year is when an off-the-clock Microsoft worker prevented malicious code from spreading into widely-used versions of Linux just because he got suspicious of a slightly slower SSH login time (0.299s to 0.807s).
However, the opposing perspective, such as that in "situational awareness", says we need to be aware that not all aspects of LLMs should be open at the same level (if at all). And this should be re-evaluated as models get more capable. If we have a model that can generate novel bio-weapons, we don't want that to be in the hands of a rogue state for example.
For example, while the core architecture and training data might be made open for scrutiny and improvement, certain proprietary components and sensitive information could remain closed to prevent replication or misuse.
As we edge closer to developing AGI & ASI, the question of openness becomes even more critical. Should these even more advanced systems ever be open-source? There are compelling arguments on both sides. Openness can foster innovation and accelerate development, but it also poses risks if such powerful technologies fall into the wrong hands. Moreover, overcoming technical challenges like the "data wall" requires collaboration and transparency to leverage collective intelligence effectively.
In conclusion, the open-source model offers a framework for balancing transparency, innovation, and security in AI development. Should the AI community embrace open-source principles, to work collaboratively towards the responsible development of AI technologies? Or is the risk too great, and should we maintain a more closed approach to safeguard against misuse / proliferation? These are questions that need to be addressed as we move forward in the AI space, with defensive technology playing a crucial role to ensure the safe and ethical deployment of AI systems.
Leveraging Private Proprietary Data
While doing customer development this past year, I stumbled on a problem that resonated with a few business owners. They want to leverage their proprietary data with new AI capabilities, but they are reluctant to just hand over their alpha to a third party to just train their next generation of models. They aren't comfortable with the idea of their data being used to train models that they have no control over. This is a seemingly significant barrier to the adoption of AI technologies, especially for small and medium-sized businesses.
You could use Azure OpenAI service to build a private instance of ChatGPT, which addresses some of these concerns by allowing businesses to keep their data private. However, there are more advanced and comprehensive solutions needed to truly address the reservations with data privacy, control, and security.
One approach is the use of confidential computing to train AI agents on a particular user's proprietary data. This involves using hardware-based security features to create a secure enclave where data can be processed without exposing it to unauthorized access. By doing so, businesses can ensure that their proprietary data remains confidential while still benefiting from AI capabilities.
Another possibility is the use of confidential computing with blockchain technology to create a secure and trusted environment for data sharing. The use of a blockchain provides an immutable record of transactions, ensuring transparency and accountability. Blockchain can also be used to manage micro-payments between agents, creating a secure and efficient platform for compensating data owners when their agents are used.
Federated Learning
Another technology that addresses privacy concerns is federated learning. This approach allows AI models to be trained across multiple decentralized devices or servers holding local data samples, without exchanging them. This way, businesses can benefit from collective learning without compromising their proprietary data.
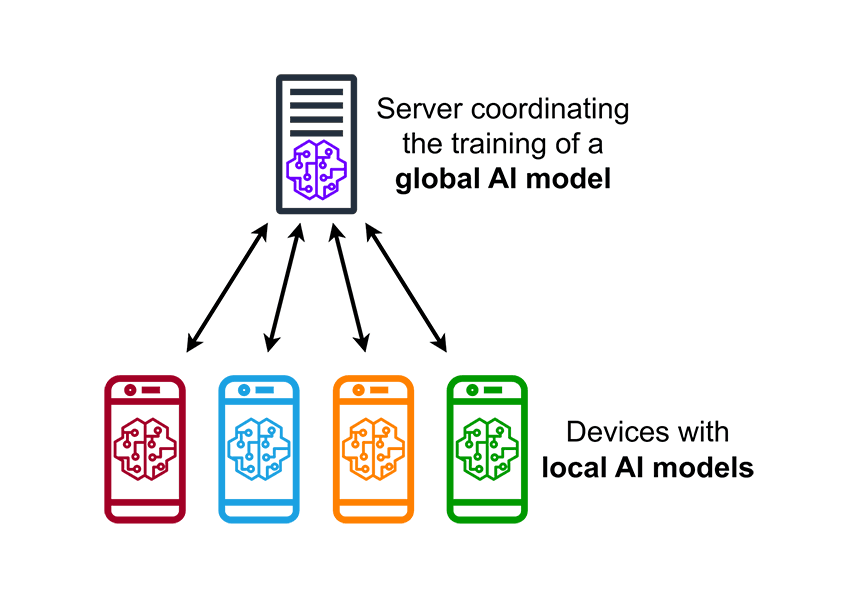
Federated learning works by distributing the training process across multiple nodes, each of which trains the model on its local data. The local updates are then aggregated to improve the global model, ensuring that the raw data never leaves its original location. This method not only enhances data privacy but also reduces the risk of data breaches and ensures compliance with data protection regulations.
Mechanistic Interpretability
The problem of misalignment in AI systems is one that particularly interests me. Recently, Anthropic's papers on mechanistic interpretability 1 2 have had a significant impact on me.
The exploration of using sparse autoencoders for feature interpretability in the paper "Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet" is a milestone towards solving this issue. And while I acknowledge the preliminary nature of this work, it made me see a light at the end of the tunnel; that it is in fact possible to steer models better during deployment. I have written a blog post on my main takeaways after a survey of the related literature.
The Importance of Mechanistic Interpretability
Mechanistic interpretability, which aims to understand why a language model produces a certain output, goes hand in hand with the development of AI in the next decade for a number of reasons:
- Explainable AI:: We need to comprehend why AI systems make certain decisions. This understanding is vital for debugging, improving, and trusting these systems. As we rush towards AGI, balancing this progression with explainability is critical. Without transparency, we risk deploying systems whose operations we cannot fully grasp or control.
- Transparency and Trust: Enhancing transparency allows users to understand, trust, and effectively control AI systems. Without trust, adoption of AI technologies in areas like healthcare and finance should (rightly so) face significant hurdles.
- Ethical and Regulatory Compliance: Frameworks need to be in place to ensure that AI operates within ethical and regulatory boundaries. Protecting human agency by ensuring AI systems are accountable and aligned with human values is non-negotiable.
To address these needs, we need to develop Mechanistic Interpretability tools. We would need to be in a position where we can use interpretable features to make targeted adjustments to a model's behaviour without extensive retraining.
Another aspect that we lack in is a comprehensive understanding of how these models evolve during training. "Phase transitions" 3, where a model suddenly develops emergent capabilities during training, is a key area of concern. As models scale and evolve, knowing when these phase transitions happen can help us address safety issues. We discussed this in more detail in a recent podcast episode
Problems of the Information Economy
In the knowledge-driven economy, information is our most valuable commodity. Yet, ironically, as AI-generated content floods our feeds from Amazon, Twitter, to TikTok, it's getting tougher to pinpoint and access the information that is actually valuable to us. I am seeing the ability to navigate but also trust in information systems becoming a significant concern. This is only set to get worse, and is why I set out to create Dcypher AI.
Specifically, it is estimated that by 2027, AI systems will be able to generate an entire internet's worth of tokens every single day. This is an estimate based on the capacity of the estimated inference fleets in 2027 and the rough size of the internet based a public deduplicated CommonCrawl of around 30T tokens, which contains much of the internet's data used for language model training.
The internet is incredible, but the bitter truth is that it's impossible to consume it all. The sheer volume of information available to us is overwhelming, and only getting worse. The challenge of sifting through it to find what is relevant and reliable to us is also becoming increasingly complex. This is further complicated by the proliferation of misinformation & disinformation, the rapid spread of content through social media and the advancement of AI tech that can generate convincing fake content.
Trust and Misinformation
One simple solution to the erosion of trust in information systems from fake and AI generated content is simply a return to more traditional methods of communication, like in-person conversations. However, with companies like Figure AI developing human form factor robots, even this approach may not last for long...
Mis-information is not a new phenomenon, but the speed and reach of social media have amplified its spread, making it difficult to discern fact from fiction. To combat this, we need to change how we consume information.
More user-intuitive ways to traverse ideas, concepts, and content, effectively escaping "cyber pollution," are necessary. Knowledge graphs are one solution. An inspiring example of this interface is the Imperial Tech Foresights Automated Futures Map. I have been developing Dcypher AI, initially with a prototype to do the same for the AI landscape. These representations of ideas and concepts can enhance discovery, encourage variability in thinking, and identify gaps in knowledge more effectively than traditional methods.
Leveraging Graph ML techniques, which have been around for a while, once we reach this vantage point is the next logical step. An interesting example of this in action is fake news detection on social media using geometric deep learning (Monti et al) 4.
Mis-direction
Mis-direction by consuming all our data from the same vendors is also equally dangerous for variability in thinking. I am not a Trump supporter by any stretch of the imagination, but entertain this example to illustrate the point. On March 16, 2024, Donald Trump said:
We’re going to put a 100% tariff on every single car that comes across the line, and you’re not going to be able to sell those cars if I get elected. Now, if I don't get elected, it's going to be a bloodbath for the whole - that's gonna be the least of it. It's going to be a bloodbath for the country.
Following the speech, the definition of "bloodbath" was changed on Google to remove the financial example, allowing the latter half of the quoted snippet of Trump's speech to be taken out of context easier by the popular media, neglecting the financial context of the auto industry.
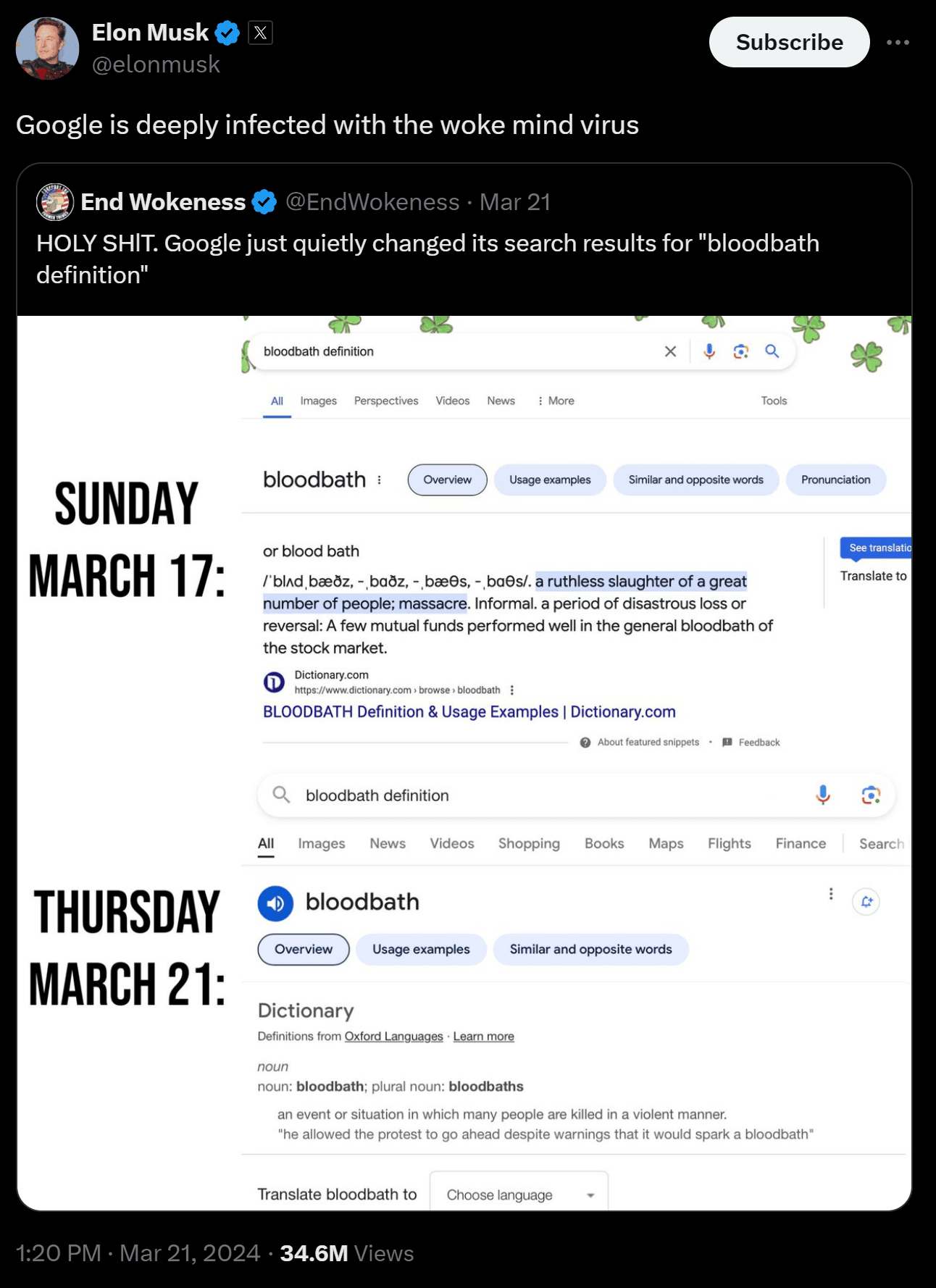
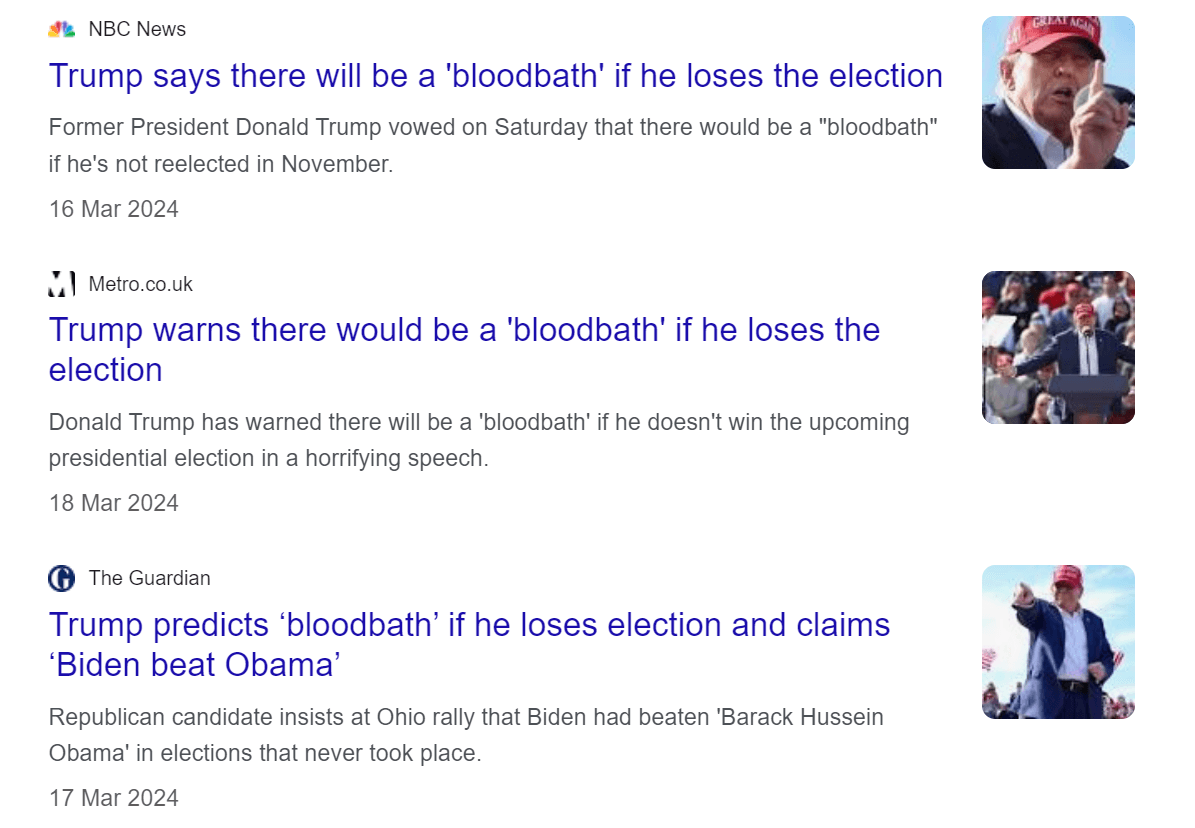
I can appreciate the political implications of this, especially as news outlets focus on the word "bloodbath." Changing definitions and mis-directing at the same time people were likely searching for that very definition is a concerning power centralised information vendors have. To further illustrate the point that this was more likely mis-direction rather than a mis understanding, many of these same news outlets had previously used the word "bloodbath" in a financial context themselves:
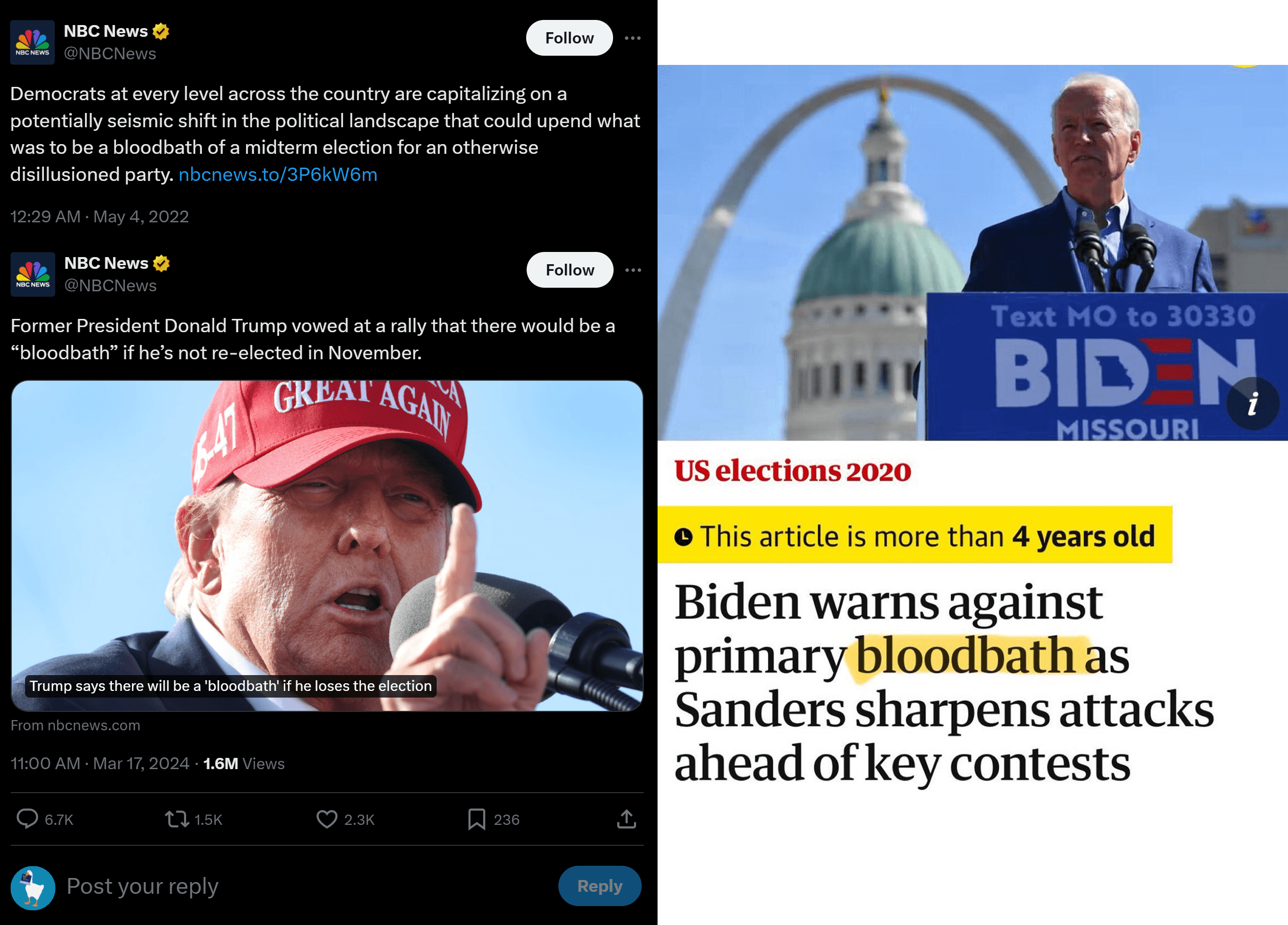
This incident illustrates how the information we consume can be manipulated to fit a particular narrative, highlighting the need for better ways to navigate and trust information systems, especially as AI becomes more prevalent in generating convincingly fake content.
The Challenge of Deepfakes
Deepfakes present another layer of complexity in the information economy. Take Mark Zuckerberg's viral AI-Generated Beard Photo. The whole situation highlights the potential for AI-generated content to influence and shape public perception. Even when people know that the content is fake, it still impact's their views and opinions. This is a light-hearted example, but there are more serious incidents, such as the deepfake's of Taylor Swift and Turkey’s deepfake influenced election.
AI is a prime suspect for creating and spreading misinformation, affecting elections, and potentially other critical societal processes. To combat the challenges posed by deepfakes and misinformation, several technological and educational initiatives are necessary:
- AI Tools for Detection: Developing AI tools that can detect manipulated images, videos, and audio is critical. Companies like Truepic and projects like Microsoft's Video Authenticator are working on verifying the authenticity of multimedia content, which is a step in the right direction.
- Decentralized Verification Networks: There is a potential to use blockchain tech to create immutable records of original content to help track alterations and verify the authenticity of information. Digital watermarks can authenticate the origin and ownership of digital content, reducing the spread of fake content. For example, we can have Taylor Swift sign her content with a private key, and then verify the signature on the content to ensure it is authentic. However, ensuring people sign content that may not be favourable to them is a challenge.
- Educational Initiatives: Educating people on how to critically evaluate information sources is essential. Teaching critical thinking and media literacy can let people identify and question misinformation themselves, reducing its impact. While we are accustomed to being critical of text (most of us don't believe everything we read online), this isn't as intuitive for images and videos yet.
Robotics
Robotics is rapidly advancing trend right now, with big players like Figure AI, Sanctuary AI, Hugging Face, and Physical Intelligence (Pi) in the spotlight at the moment. These firms are integrating AI with humanoid robots; specifically, they are moving towards using LLMs as a reasoning scaffold in the backend. So naturally, risks in the general AI space extend to the robotics space now as well.

Key Players and Innovations in the space include:
- Figure AI: Valued at nearly $2 billion, Figure AI uses OpenAI models as the "brain" for their humanoid robots. This integration allows for advanced reasoning and control, attracting investments from Jeff Bezos, OpenAI, and Nvidia. OpenAI even attempted to acquire Figure AI, highlighting the strategic importance of their advancements.
- Sanctuary AI: Known for its Phoenix robot, which uses hydraulics for precision, dexterity, and strength. This technology sets a new standard for robotic performance.
- Hugging Face: Even though they are traditionally focused on AI models, Hugging Face is launching a new project focused on robotics under the direction of former Tesla Inc. staff scientist Remi Cadene. The pivot to hardware is a vast change in paradigm.
- Physical Intelligence (Pi): Recently emerged with $70 million in seed funding, founded by a team of renowned robotics and AI experts. Pi also aims to develop foundational models and learning algorithms for various robots.
As AI integration with robotics accelerates, ensuring safety and control in a similar way to general AI is critical. Defensive technologies for robotics should focus on the following key areas:
- Mechanistic Interpretability: Understanding and controlling AI decision-making processes to predict and manage robot actions effectively.
- Penetration Testing: Regular testing to identify and mitigate vulnerabilities in robotic systems
- Strict Access Control: Preventing unauthorized access and modifications through strict physical and cybersecurity measures.
- Human-in-the-Loop: Ensuring the ability to have human oversight and intervention capabilities to handle unexpected situations and maintain ethical deployment.
The integration of AI with robotics promises significant advancements but also poses challenges. Developing the control and safety systems is essential to harness the potential of robotics without the associated risks.
Conclusion
Defensive technology is crucial for addressing the risks associated with rapid advancements in AI. The two key themes here are cybersecurity, which includes developing sophisticated risk anticipation, detection and mitigation strategies, as well as Mechanistic interpretability to understand and control AI systems effectively. As we move forward, it is important that we prioritize these defensive technologies to ensure a secure future integrated safely AI.
Resources
- Notes on Differential Technological Development, Michael Nielsen 2024
- My techno-optimism, Vitalik Buterin 2023
References
Footnotes
-
Anthropic: Adly Templeton*, Tom Conerly*, Jonathan Marcus, Jack Lindsey, Trenton Bricken, Brian Chen, Adam Pearce, Craig Citro, Emmanuel Ameisen, Andy Jones, Hoagy Cunningham, Nicholas L Turner, Callum McDougall, Monte MacDiarmid, Alex Tamkin, Esin Durmus, Tristan Hume, Francesco Mosconi, C. Daniel Freeman, Theodore R. Sumers, Edward Rees, Joshua Batson, Adam Jermyn, Shan Carter, Chris Olah, Tom Henighan: “Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet”, 2024 ↩
-
Anthropic: Trenton Bricken*, Adly Templeton*, Joshua Batson*, Brian Chen*, Adam Jermyn, Tom Conerly, Nicholas L Turner, Cem Anil, Carson Denison, Amanda Askell, Robert Lasenby, Yifan Wu, Shauna Kravec, Nicholas Schiefer, Tim Maxwell, Nicholas Joseph, Alex Tamkin, Karina Nguyen, Brayden McLean, Josiah E Burke, Tristan Hume, Shan Carter, Tom Henighan, Chris Olah: “Towards Monosemanticity: Decomposing Language Models With Dictionary Learning”, 2023 ↩
-
Catherine Olsson∗,Nelson Elhage∗, Neel Nanda∗, Nicholas Joseph†, Nova DasSarma†, Tom Henighan†, Ben Mann†, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, Dawn Drain, Deep Ganguli, Zac Hatfield-Dodds, Danny Hernandez, Scott Johnston, Andy Jones, Jackson Kernion, Liane Lovitt, Kamal Ndousse, Dario Amodei, Tom Brown, Jack Clark, Jared Kaplan, Sam McCandlish, Chris Olah‡ "In-context Learning and Induction Heads", 2022 ↩
-
Federico Monti, Fabrizio Frasca, Davide Eynard, Damon Mannion, Michael M. Bronstein: “Fake News Detection on Social Media using Geometric Deep Learning”, 2019 ↩