One of the issues I wanted to tackle when I created Dcypher was information overload. In the knowledge-driven economy, information is our most valuable commodity. Yet, ironically, as AI-generated content floods our feeds from Amazon, Twitter, and TikTok, it's getting tougher to pinpoint and access the information that is actually valuable to us. The challenge has never been about finding updates; it's always been about sifting through the noise to uncover the gems that truly matter and optimizing our time amidst an ocean of information.
To address this, I created an online platform that aggregates AI news with the dream of a world where the AI landscape is seamlessly navigable, enabling everyone to access the information they need without the noise and clutter of today's digital age. The first step in this journey is Topic Modelling: mapping out the AI landscape to identify the clusters and trends that are shaping AI right now.
To this end, I created an online platform that aggregates AI news, with the dream of a world where the landscape of AI is seamlessly navigable, enabling every individual to access the information they need without the noise and clutter of today's digital age. The first step in this journey is Topic Modelling; to map out the AI landscape and identify the clusters, topics and trends that are shaping AI right now.
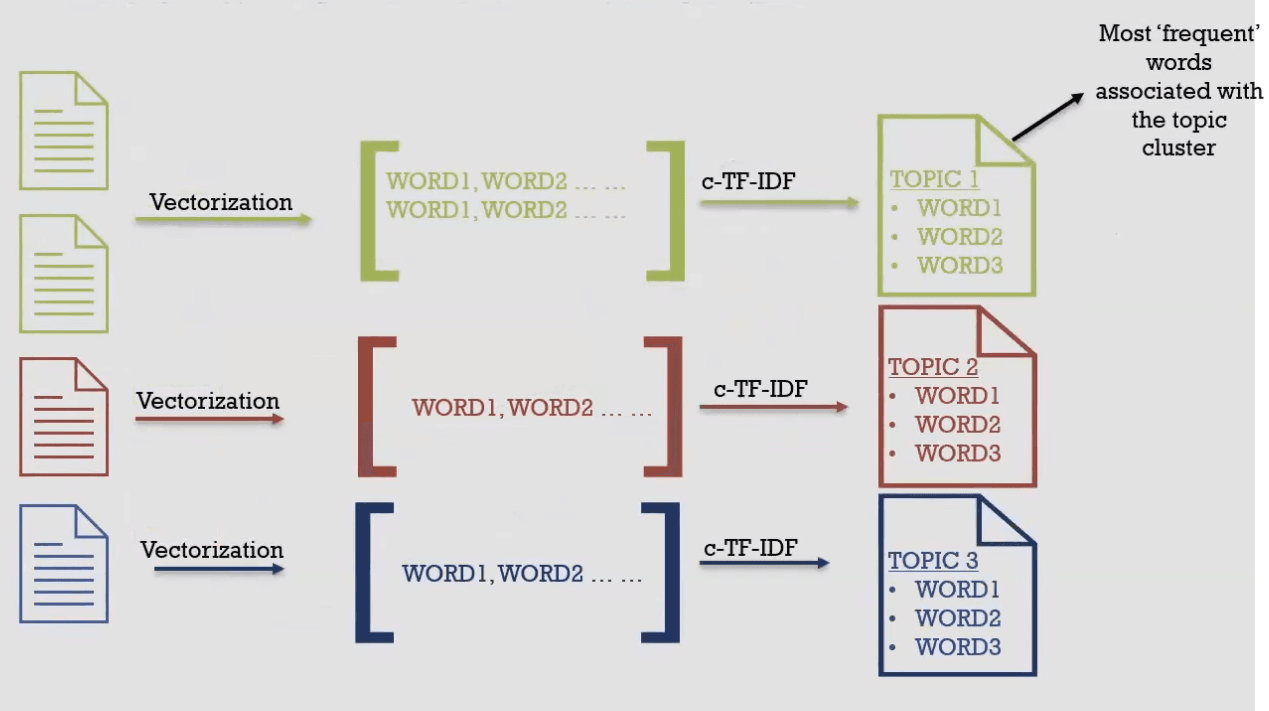
Tl;dr: Essentially, I perform unsupervised clustering on the news we have collected, and find human readable names for each cluster. To that end, I have created this visual:
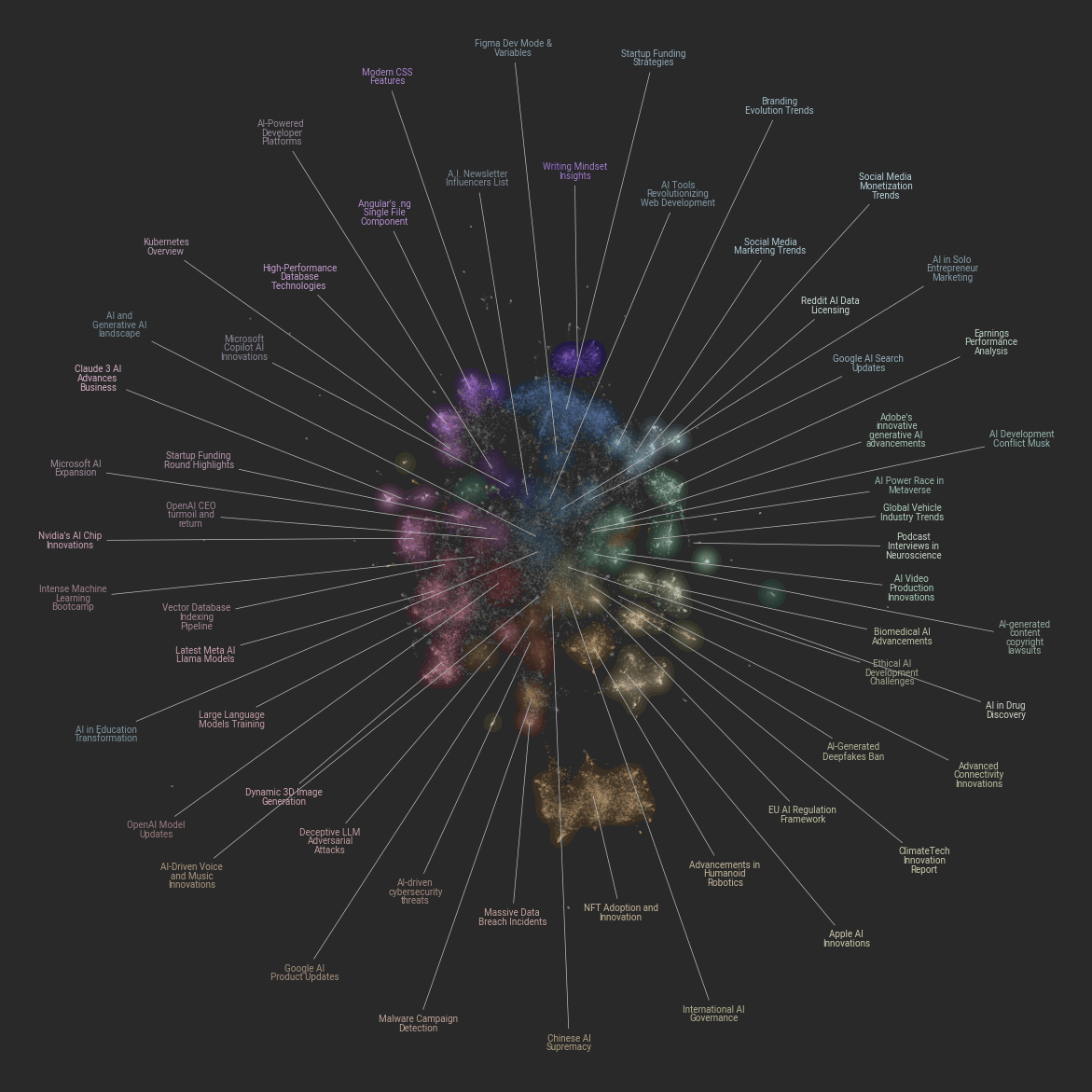
Motivation
Clustering topics is the first point of action. We need to develop interactive graphs and visual exploration tools that allow users to visually navigate through trends, relationships, and clusters of AI developments. For inspiration, consider the visual approaches used by Zeta Alpha, a search engine for papers with topical feeds, Technology Radar by ThoughtWorks, and Imperial Tech Foresight, all of which employ a visual graphical representation.
These platforms enable users to easily map out items and their relationships, and we should aim for a similar visualization with dynamic filtering options to streamline information discovery based on user-defined criteria in the AI space.
Traditional Methods
Traditional methods for topic modelling mainly consist of Latent Dirichlet Allocation (LDA). This iterative process, performed through Gibbs sampling (a Monte-Carlo Markov-chain method), faces several challenges:
- Polysemy: Words with multiple meanings can cause confusion. For example, "Let's go to the LA Galaxy soccer game" and "Let's learn about the galaxy at the observatory" use the word "galaxy" differently.
- Attention and Long-Range Dependencies: The bag-of-words format treats words independently, losing the interdependencies between words in a sentence.
- Domain Knowledge: Traditional models require strong domain knowledge to interpret results correctly.
Here come Large Language Models (LLMs)
LLMs provide contextual representations, improving the accuracy of topic models. However, they introduce challenges such as:
- Curse of Dimensionality: We have too many dimensions, especially when we want to perform unsupervised clustering.
- Mapping: Translating contextual vector representations back to a topic can be difficult, especially when we want to start representing the topic by an understandable title.
- Unsuitability for Clustering: The optimal number of topics often matches the number of tokens in the model, complicating clustering tasks. In the Masked Language modelling task, we are doing some sense of topic clustering.
Approach
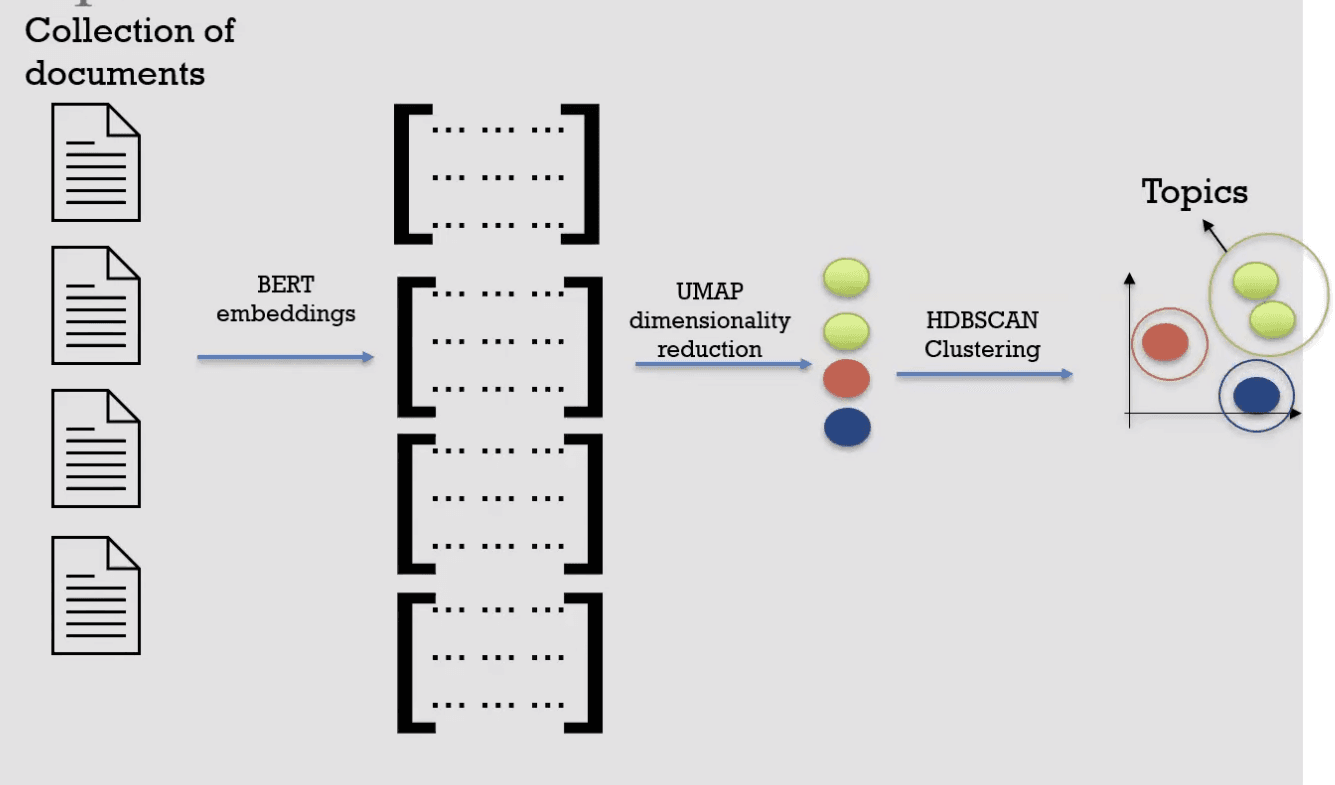
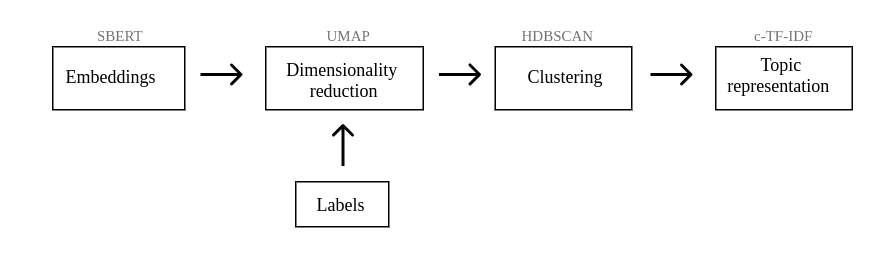
We reference the BERTopic package, which approaches topic modelling as a clustering task and attempts to cluster semantically similar documents to extract common topics.
- Group Documents into Topics:
- Embed Documents for Contextual Vector Representations: Embeddings are contextually rich, capturing the nuances of language. We have embedded the documents using OpenAI's
text-embedding-3-large, resulting in embeddings of size 3072. The immediate problem is that they are large and dense - Use UMAP for Dimensionality Reduction: UMAP (Uniform Manifold Approximation and Projection) reduces dimensionality while preserving the local and global structure necessary for clustering. Cluster models typically have difficulty handling high dimensional data due to the curse of dimensionality. There are great approaches that can reduce dimensionality, such as PCA, but UMAP keeps local and global structure when reducing dimensionality, which is important to keep as it contains the information necessary to create clusters of semantically similar documents.
- Perform HDBSCAN Clustering: HDBSCAN (Hierarchical Density-Based Spatial Clustering of Applications with Noise) is a density-based clustering technique. It can find clusters of different shapes and has the nice feature of identifying outliers where possible. As a result, we do not force documents into a cluster where they might not belong. This will improve the resulting topic representation as there is less noise to draw from.
- HDBSCAN performs
DBSCANover varying epsilon values and integrates the result to find a clustering that gives the best stability over epsilon. This allows HDBSCAN to find clusters of varying densities (unlikeDBSCAN), and be more robust to parameter selection. - Simply put, we don’t need to specify the number of clusters. It determines the optimal number of clusters
- HDBSCAN performs
- Embed Documents for Contextual Vector Representations: Embeddings are contextually rich, capturing the nuances of language. We have embedded the documents using OpenAI's
- Map Clusters to Understandable Topics: Now we need to obtain the Mapping of these clusters back to understandable Topics i.e. obtaining word representations for each topic.
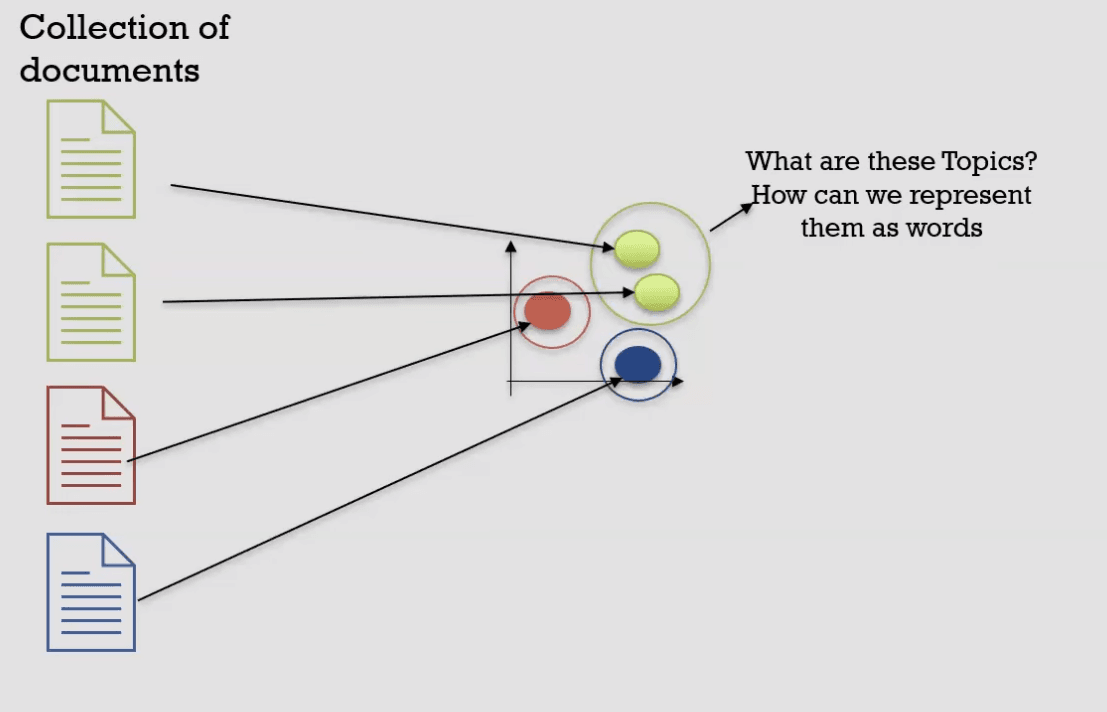
- Word Gathering and Vectorization: We vectorise (not embed) the words form the documents in each cluster. We then use TF-IDF like methods to find the most frequent words associated with the topic cluster.
- Class Based Term Frequency Inverse Document Frequency (c-TF-IDF): Calculate the relevance of a word to a text within a corpus. This adjusted TF-IDF takes into account what makes the documents in one cluster different from documents in another cluster. Words that appear frequently in this topic/cluster and not in others are important for this cluster. If they are also frequent in all clusters, they are not important for the meaning of this cluster in particular. This representation is then L1-normalized to account for the differences in topic sizes. For a term within class :
Where:
-
is the frequency of word in class
-
is the frequency of word across all classes
-
is the average number of words per class
-
Improvements: Use CountVectorizer to convert text documents into a matrix of token counts, utilizing n-grams and stop words to refine the process. Here, a built in stop word list for English is used. There are several known issues with ‘english’ and you should consider an alternative (see Using stop words). In the list, all of the detected stop words will be removed from the resulting tokens.
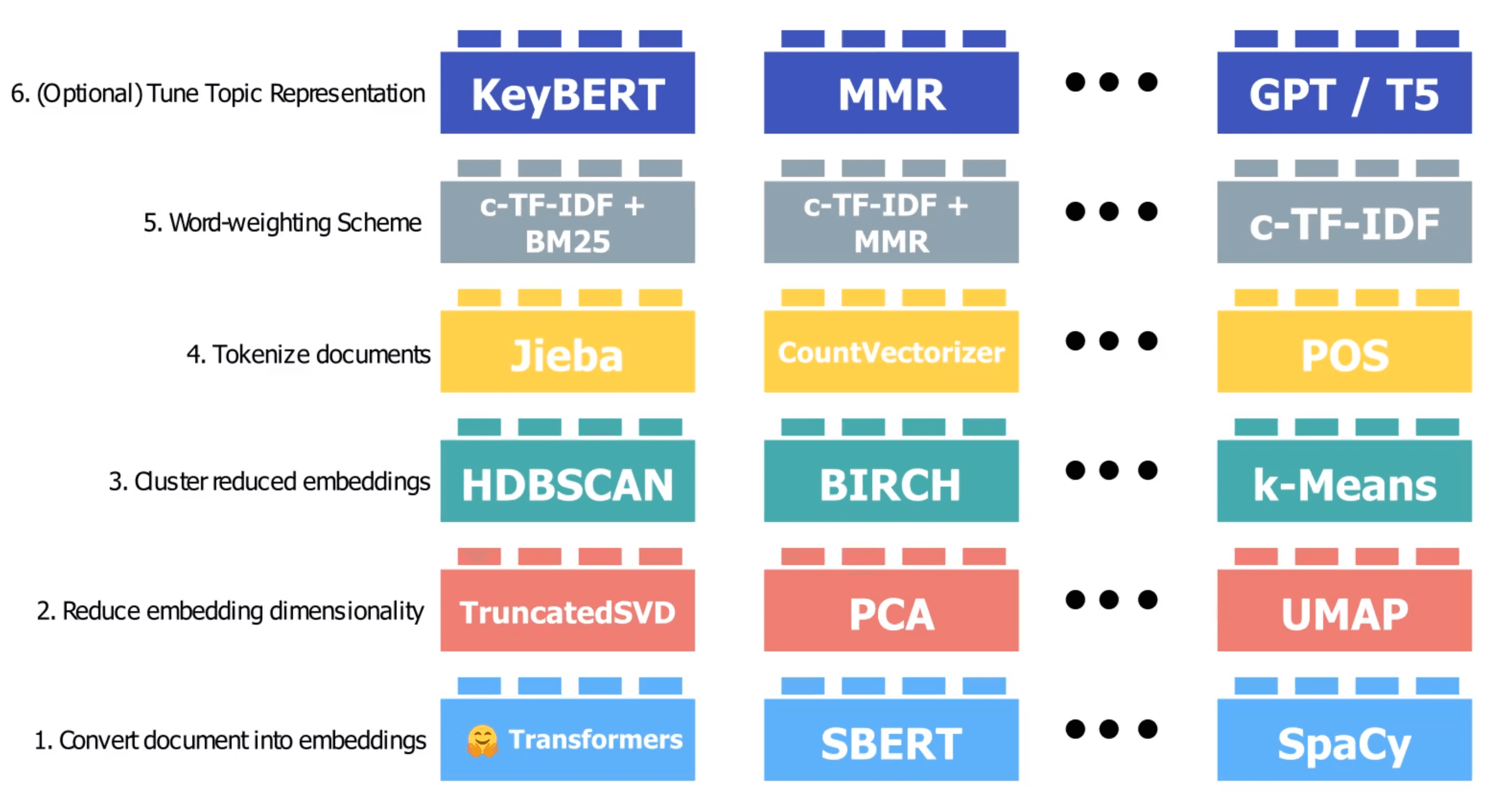
Fine-Tuning Representations
We can refine topic representations using methods like KeyBERT for similarity optimization, Maximum Marginal Relevance (MMR) to eliminate redundant words, and Zero-Shot Classification with LLMs to assign topics without examples.
- KeyBERT: This method refines results by selecting representative documents for a cluster, like the centroid of a cluster, and choosing frequent words. The selected documents are then run through another embedding step to optimize for similarity.
- Maximum Marginal Relevance (MMR): This method eliminates redundant or repetitive words, ensuring diverse and relevant keywords for each topic. For example, given the words
["going", "outdoors", "outside"], MMR might remove"outdoors"to provide more relevant and diverse terms like["going", "outside", "exercise"]. - Zero-Shot Classification: This uses LLMs to assign topics without any examples, by just providing topic names. This approach helps generate more representative keywords.
Improvements
The main steps for topic modeling with BERTopic include sentence-transformers, UMAP, HDBSCAN, and c-TF-IDF, run in sequence. However, BERTopic's modular nature allows for independence between these steps, allowing us to do customization and exploration of various topic modeling techniques.
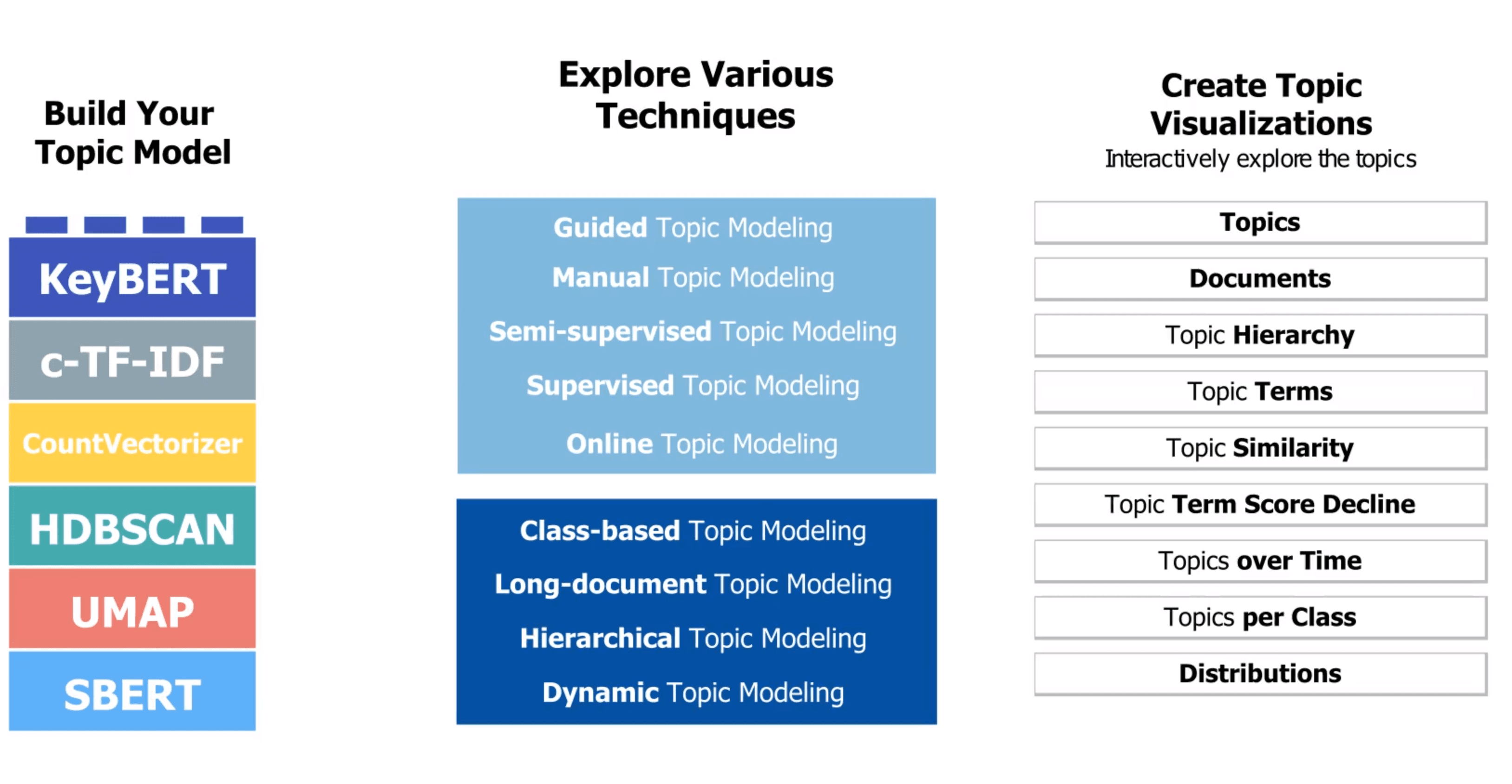
Assumptions and Considerations
Models like HDBSCAN assume that clusters can have different shapes and forms. Therefore, using a centroid-based technique to model the topic representations might not be beneficial since the centroid is not always representative of these clusters. We aim for a topic representation technique that makes minimal assumptions about the expected structure of the clusters.
Also, using a bag-of-words representation ensures no assumptions concerning cluster structure. Additionally, the bag-of-words representation is L1-normalized to account for clusters of different sizes.
Semi-Supervised Topic Modeling
If data is partially labeled or some topics are identified, we can use Semi-Supervised Topic Modeling. This approach allows us to input pre-determined labels during the dimensionality reduction step, nudging topic creation towards specific pre-specified topics. Semi-supervised modeling steers the dimensionality reduction of embeddings into a space closely following any labels you already have.
Hierarchical Topic Modeling
When tweaking your topic model, the number of generated topics significantly affects the quality of topic representations. Some topics could be merged, and understanding their relationships helps determine which should be merged. Hierarchical Topic Modeling models the hierarchical nature of the topics to understand their similarities and sub-topics.
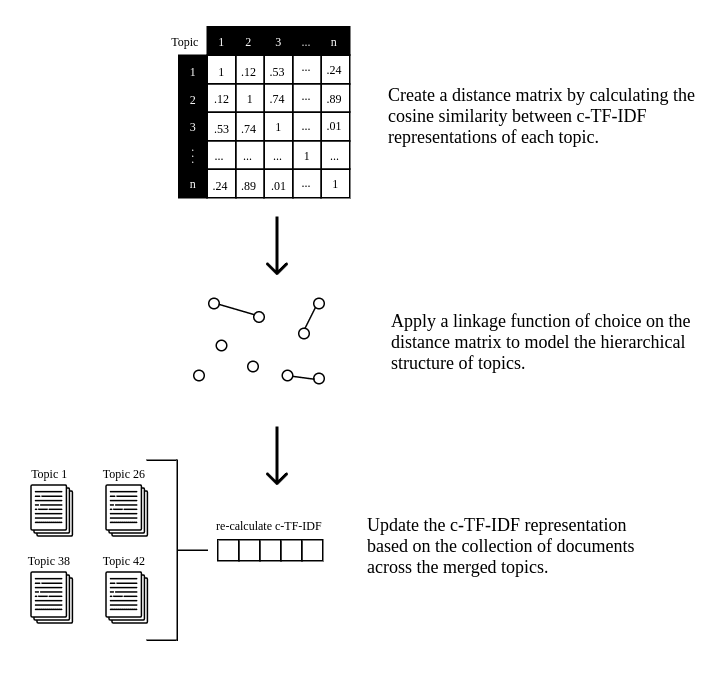
With our data:
Topics per Class
Sometimes, you might be interested in how certain topics are represented across different categories or user groups. Topics per Class allows us to create a topic model and extract each topic's representation per class, showing how topics are represented for certain subgroups.
Dynamic Topic Modeling
Dynamic Topic Modeling (DTM) analyzes the evolution of topics over time. For example, LLM security discussions in 2022 may differ significantly from those in 2023. BERTopic allows for DTM by calculating topic representation at each timestep without rerunning the entire model. We first fit BERTopic as if there were no temporal aspect, creating a general topic model. Then, we calculate the c-TF-IDF representation for each topic and timestep, resulting in specific topic representations at each timestep.
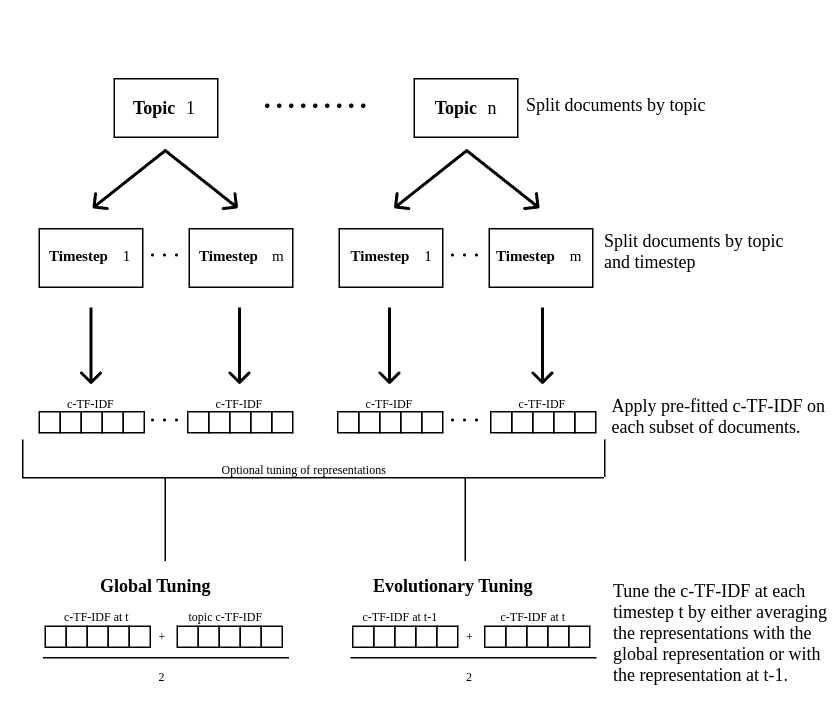
For example, with our data:
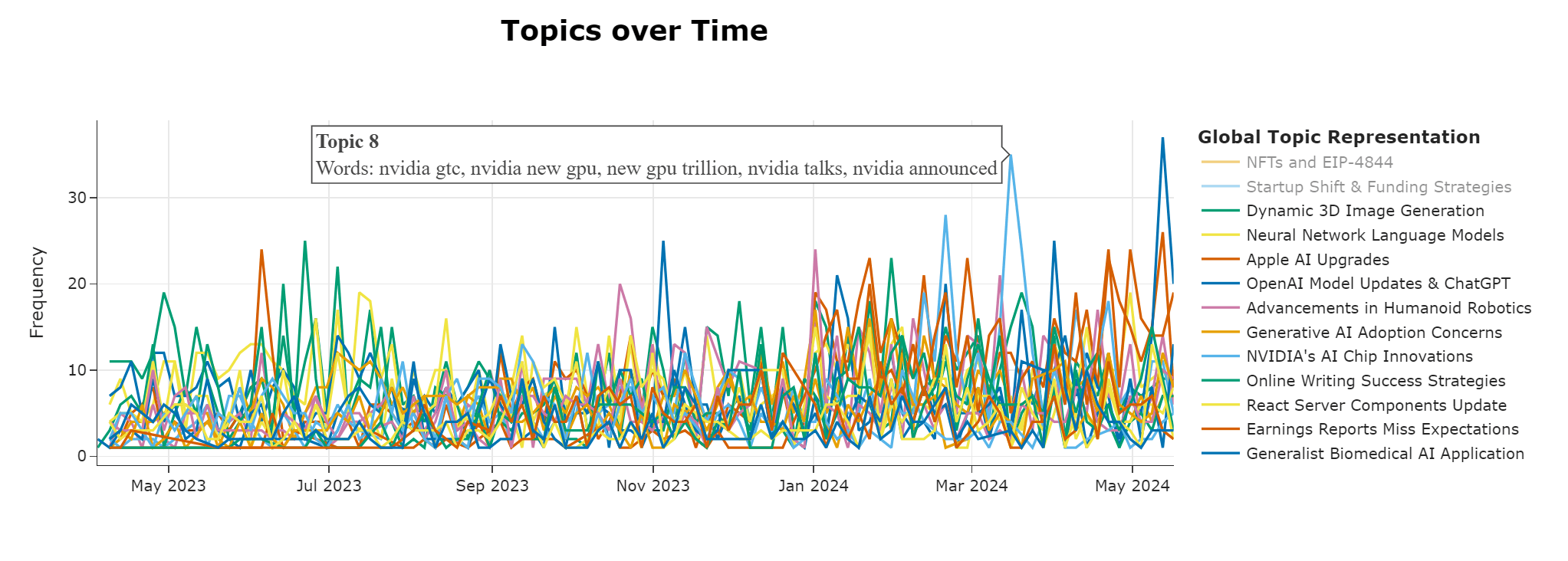
Online Topic Modeling
Online Topic Modeling, or incremental topic modeling, enables learning incrementally from mini-batches of instances, updating your topic model with new data.
Merge Multiple Fitted Models
After training a new BERTopic model on your data, new data might still come in. While you can use online BERTopic, you might prefer default HDBSCAN and UMAP models since they do not support incremental learning out of the box. Instead, train a new BERTopic on incoming data and merge it with your base model to detect new topics in unseen documents. This approach also allows for a degree of federated learning, where each node trains a topic model aggregated in a central server.
Fine Tuning Topics
Multi-Aspect Representations
Multiple Representations. During BERTopic development, various types of representations can be created, from keywords and phrases to summaries and custom labels. This variety allows for creative ways to summarize topics. Therefore, multi-aspect topic modeling is introduced. During the .fit or .fit_transform stages, you can get multiple representations of a single topic, generating and storing different topic representations.
GenAI Topic
The topics generated from BERTopic can be fine-tuned using text generation Large Language Models like ChatGPT GPT-4o, and open-source solutions. These techniques help generate labels, summaries, and even poems for topics. First, we generate a set of keywords and documents describing a topic best using BERTopic's c-TF-IDF calculation. Then, these candidate keywords and documents are passed to the language model and it is prompted to generate an output that fits the topic best. A significant benefit here is describing a topic with only a few documents.
Future Goals
It'd be ideal to use graph-based navigation to help users understand the context and connections between different pieces of content, allowing discovery and reducing information overload. Graphs are also the most intuitive way to represent relationships between objects. Aiming for this data format will let us use neural networks that operate on graph data (called graph neural networks, or GNNs). Recent developments have increased their capabilities and expressive power. We are starting to see practical applications in areas such as antibacterial discovery 1, physics simulations 2, fake news detection 3, traffic prediction 4 and recommendation systems 5.
Additionally, we plan to develop a forecasting model to predict emerging trends and hot topics in the AI industry using historical data and current market analysis. This model will help users stay ahead by providing early insights into potentially impactful technologies or research. With the time series data we have, we can also track the evolution of trends, transforming our platform into an AI Trend Prediction and Market Analysis Tool. Predictive analytics can then suggest actions or deeper reads on topics expected to gain traction, aiding decision-making for professionals and researchers
But before we get there, simple topic modelling like this is the first step to making the AI landscape more navigable!
Footnotes
-
Jonathan M. Stokes, Kevin Yang, Kyle Swanson, Wengong Jin, Andres Cubillos-Ruiz, Nina M. Donghia, Craig R. MacNair, Shawn French, Lindsey A. Carfrae, Zohar Bloom-Ackermann, Victoria M. Tran, Anush Chiappino-Pepe, Ahmed H. Badran, Ian W. Andrews, Emma J. Chory, George M. Church, Eric D. Brown, Tommi S. Jaakkola, Regina Barzilay, James J. Collins: "A Deep Learning Approach to Antibiotic Discovery", Cell, Volume 180, Issue 4, 2020, Pages 688-702.e13 ↩
-
Alvaro Sanchez-Gonzalez, Jonathan Godwin, Tobias Pfaff, Rex Ying, Jure Leskovec, Peter W. Battaglia: “Learning to Simulate Complex Physics with Graph Networks”, 2020 ↩
-
Federico Monti, Fabrizio Frasca, Davide Eynard, Damon Mannion, Michael M. Bronstein: “Fake News Detection on Social Media using Geometric Deep Learning”, 2019 ↩
-
Oliver Lange, Luis Perez: "Traffic prediction with advanced Graph Neural Networks", 2020 ↩
-
Chantat Eksombatchai, Pranav Jindal, Jerry Zitao Liu, Yuchen Liu, Rahul Sharma, Charles Sugnet, Mark Ulrich, Jure Leskovec: “Pixie: A System for Recommending 3+ Billion Items to 200+ Million Users in Real-Time”, 2017 ↩