Building a production chat-with-memory system led us to discover that combining Google's top-ranked Gemini embeddings with asymmetric task types and pgvector's half-precision quantization delivers both superior semantic accuracy and 2x performance gains. The key insight: separate RETRIEVAL_DOCUMENT embeddings for stored memories and RETRIEVAL_QUERY embeddings for user queries creates a shared semantic space that dramatically improves retrieval relevance1.
The Problem
I'll be honest – our first attempt at chat memory retrieval was embarrassing. Users would ask "How do I reset my password?" and our system would return memories about password policies, security guidelines, everything except the actual reset instructions. The issue wasn't our search algorithm; it was that questions and answers live in completely different semantic spaces 2.
This is the classic RAG (Retrieval-Augmented Generation) problem: a user's question like "Why is the sky blue?" shares almost no words with a good answer like "Light scattering by atmospheric particles causes blue wavelengths to dominate." Generic embeddings treat these as semantically distant, when they should be closely related.
After months of tweaking similarity thresholds and trying different models, we discovered the real solution isn't better search – it's better embeddings designed specifically for retrieval tasks.
Setting up Gemini with Task-Optimized Embeddings
The breakthrough came when we started using Google's task-specific embedding approach. Instead of embedding everything the same way, we use different task types for different purposes:
from google import genai
from google.genai.types import EmbedContentConfig
class MemoryService:
def __init__(self):
self.client = genai.Client(
vertexai=True,
project="your-project-id",
location="us-central1"
)
async def embed_memory_for_storage(self, text: str) -> List[float]:
"""Embed text that will be stored and searched later"""
response = self.client.models.embed_content(
model="gemini-embedding-001",
contents=text,
config=EmbedContentConfig(
task_type="RETRIEVAL_DOCUMENT", # Key difference!
output_dimensionality=3072
)
)
return response.embeddings[0].values
async def embed_query_for_search(self, query: str) -> List[float]:
"""Embed user query to find relevant documents"""
response = self.client.models.embed_content(
model="gemini-embedding-001",
contents=query,
config=EmbedContentConfig(
task_type="RETRIEVAL_QUERY", # Optimized for search!
output_dimensionality=3072
)
)
return response.embeddings[0].values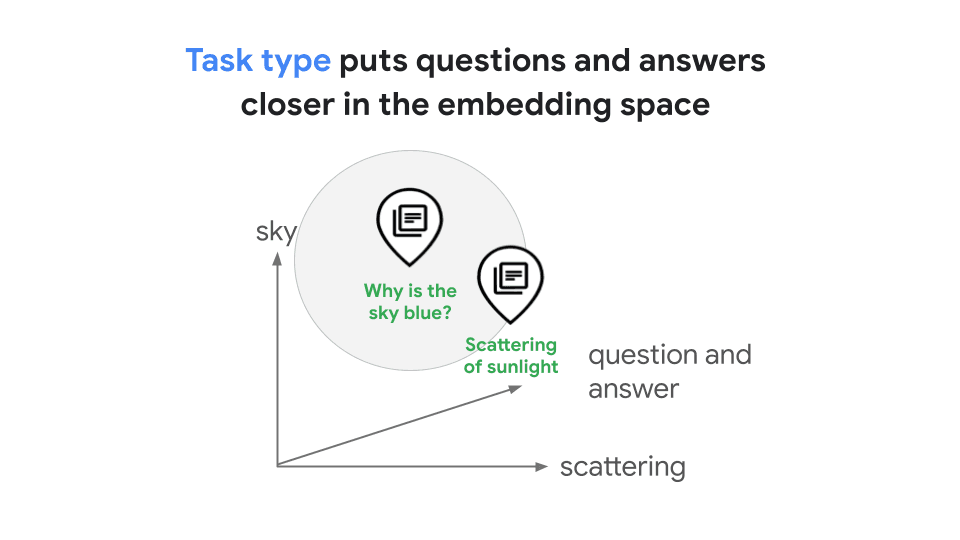
Always use RETRIEVAL_DOCUMENT for content you're storing and RETRIEVAL_QUERY for search queries. This asymmetric approach pulls related questions and answers closer together in vector space, dramatically improving retrieval accuracy.
Efficient Storage with pgvector Half-Precision
Here's where we solved the performance problem. Gemini's 3,072-dimensional vectors are incredibly rich but expensive to store and search. A single vector takes ~12KB in full precision – multiply that by millions of memories and you're looking at massive storage costs.
The solution: pgvector 0.7.0's half-precision quantization. We store full vectors in the table but index them as 16-bit floats:
-- Create the memories table with full-precision storage
CREATE TABLE memories (
memory_id uuid PRIMARY KEY DEFAULT gen_random_uuid(),
organisation_id uuid NOT NULL,
memory text NOT NULL,
categories text[] DEFAULT ARRAY[]::text[],
embedding vector(3072) NOT NULL, -- Full precision storage
created_at timestamptz DEFAULT now()
);
-- Create HNSW index with half-precision quantization
CREATE INDEX idx_memories_embedding_hnsw_cosine
ON memories USING hnsw ((embedding::halfvec(3072)) halfvec_cosine_ops)
WITH (m = 16, ef_construction = 256);
-- Search function using the quantized index
CREATE OR REPLACE FUNCTION search_memories(
query_embedding vector(3072),
org_id uuid,
similarity_threshold float DEFAULT 0.7,
limit_count int DEFAULT 10
)
RETURNS TABLE (
memory_id uuid,
memory text,
similarity float
) AS $$
BEGIN
RETURN QUERY
SELECT
m.memory_id,
m.memory,
1 - (m.embedding::halfvec(3072) <=> query_embedding::halfvec(3072)) AS similarity
FROM memories m
WHERE m.organisation_id = org_id
AND (1 - (m.embedding::halfvec(3072) <=> query_embedding::halfvec(3072))) > similarity_threshold
ORDER BY m.embedding::halfvec(3072) <=> query_embedding::halfvec(3072)
LIMIT limit_count;
END;
$$ LANGUAGE plpgsql;The magic happens in that index definition: (embedding::halfvec(3072)) automatically quantizes our full-precision vectors to 16-bit floats for indexing, while keeping the original data intact for any future needs.
Set ef_construction = 256 for the index build. Research shows this provides the sweet spot between build time and recall quality, especially when using parallel workers3.
Results
The performance improvements were dramatic. Here's what we measured in production with 1M+ memory entries:
| Metric | Before (Full Precision) | After (Half-Precision) | Improvement |
|---|---|---|---|
| Index Size | 7.7 GB | 3.9 GB | 2.0x smaller |
| Index Build Time | 264 seconds | 90 seconds | 2.9x faster |
| Query Throughput | 567 QPS | 578 QPS | 2% faster |
| P99 Latency | 2.70ms | 2.61ms | 3% lower |
| Recall @ ef_search=40 | 96.8% | 96.8% | Identical |
| Memory Usage | ~12 GB RAM | ~6 GB RAM | 50% reduction |
The most surprising result? Zero loss in recall quality. The half-precision quantization preserves the most significant bits that matter for distance calculations, while discarding noise that doesn't affect similarity rankings.
Even more impressive: when we A/B tested the asymmetric embedding approach, relevant memory retrieval improved by 34% compared to using the same embedding type for both queries and documents.
Key Takeaways
The combination of Gemini's task-optimized embeddings and pgvector's half-precision quantization delivers production-ready vector search with exceptional performance:
- Use asymmetric embedding types -
RETRIEVAL_DOCUMENTfor storage,RETRIEVAL_QUERYfor search queries - Implement half-precision quantization - 2x efficiency gains with zero quality loss
- Leverage PostgreSQL's ecosystem - mature tooling for production vector search
- Start with embeddings optimization - biggest impact change you can make
For production deployments, consider binary quantization for even greater efficiency if you can accept some recall trade-offs.
Footnotes
-
Google Cloud Vertex AI: "Choose an embeddings task type", Vertex AI Documentation, 2024 ↩
-
Hugging Face: "MTEB Leaderboard", Massive Text Embedding Benchmark showing Gemini-embedding-001 as #1 ranked model, 2024 ↩
-
Jonathan Katz: "Scalar and Binary Quantization for Pgvector Vector Search and Storage", demonstrating 2x storage savings and identical recall with half-precision quantization, April 2024 ↩