Advances in artificial intelligence have resulted in highly capable systems making decisions for reasons we do not fully understand. This lack of understanding poses significant risks, including potential future scenarios where AI might deceive humans to accomplish undesirable goals.
Mechanistic interpretability aims to understand how neural networks calculate their outputs by breaking them into components that are more easily understood than the whole. This involves reverse engineering parts of their internal processes to make targeted changes to models, thereby increasing trust and safety in AI systems.
This research area will eventually enable us to diagnose failure modes, design fixes, and certify that models are safe for adoption by enterprises and society. The core insight is straightforward: it's much easier to determine if something is safe when you understand how it works.
The fundamental approach involves training a sparse autoencoder to generate interpretable features based on transformer activations. This allows us to examine the activations of a language model during inference and understand which parts of the model are most responsible for predicting each next token.
Challenges in Interpretability
One major challenge in interpreting neural networks is polysemanticity. Neurons often activate for multiple, semantically distinct features, making it difficult to understand their specific roles.
For instance, in the vision model Inception v1, a single neuron responds to both faces of cats and fronts of cars-completely unrelated concepts. This widespread uninterpretability of individual neurons presents a serious roadblock to mechanistic understanding of language models.
In a small language model discussed by Anthropic, a single neuron responds to a mixture of academic citations, English dialogue, HTTP requests, and Korean text. This polysemanticity makes it nearly impossible to reason about network behavior in terms of individual neuron activity.

The Superposition Hypothesis offers one explanation for polysemanticity: neural networks represent more features than they have neurons by using an overcomplete set of directions in activation space. Instead of assigning features to individual neurons, the network assigns them to combinations of directions in higher-dimensional space.
Interference between non-orthogonal features means you don't gain extra benefit by having them mixed together in superposition. To address this challenge, researchers propose finding specific directions in the activation space that separate overlapping features, such that each activation vector can be reconstructed from sparse linear combinations of these directions.
By using sparse linear combinations, we can describe each point using only the few directions that truly matter-rather than all possible signals. The approach involves training a sparse autoencoder to learn these meaningful directional sets.
Disentangled Representation Learning
Disentangled representation learning aims to find data representations where different factors of variation are separated into distinct, interpretable components. Consider a noise vector in latent space-when entangled, each dimension affects multiple downstream features simultaneously.
In image generation, disentangled representations might separate factors like object identity, pose, and lighting into distinct components. For example, when generating dogs:
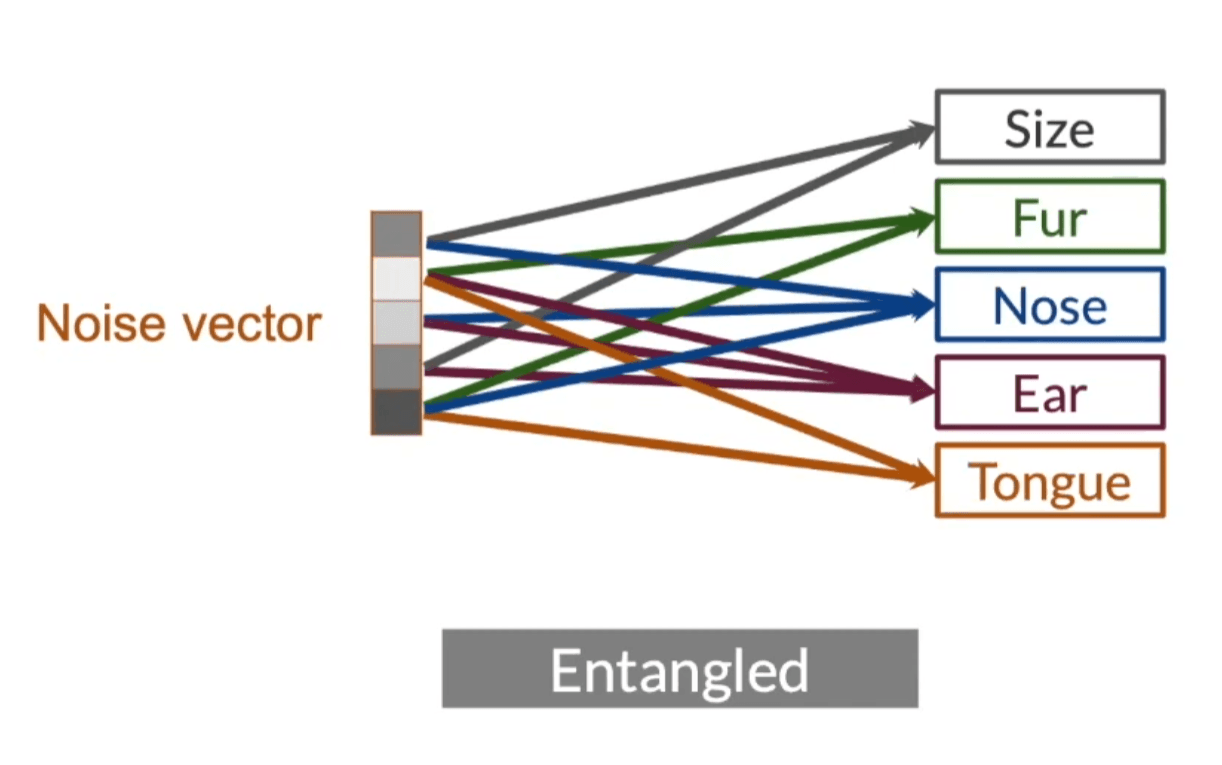
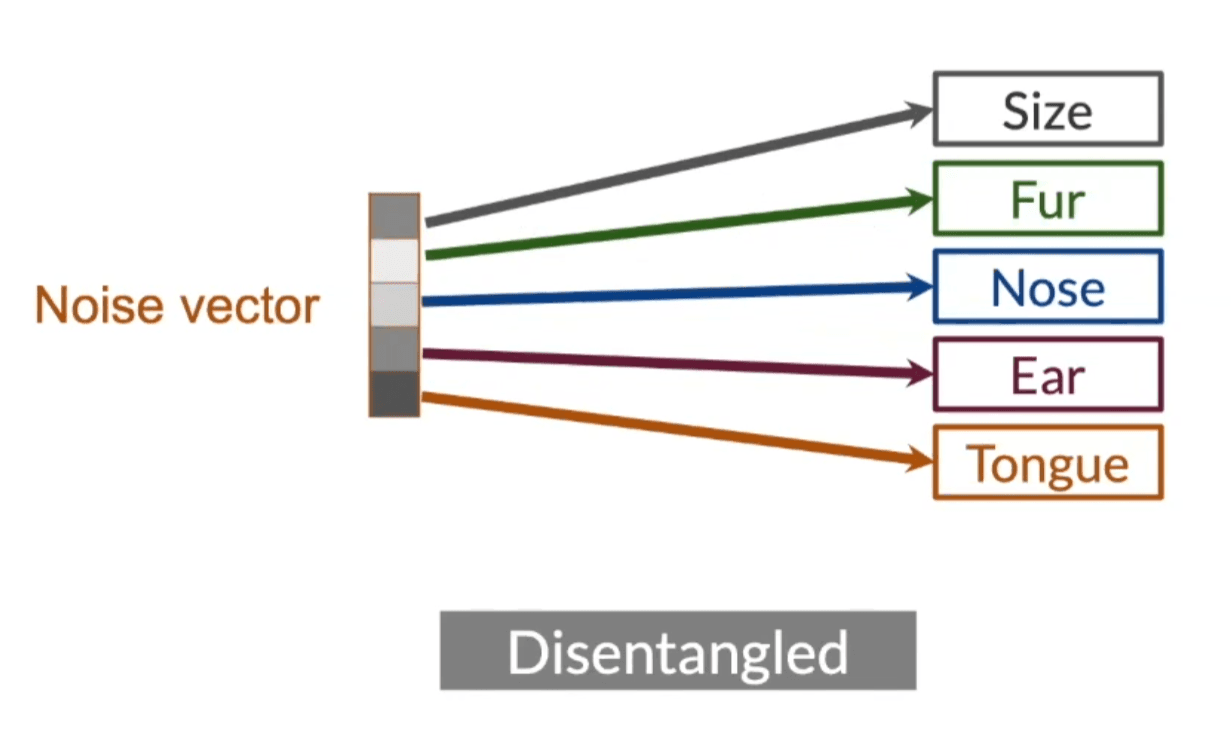
In a disentangled model, each axis of the noise vector controls only one major feature while leaving others untouched. These become orthogonal feature controls:
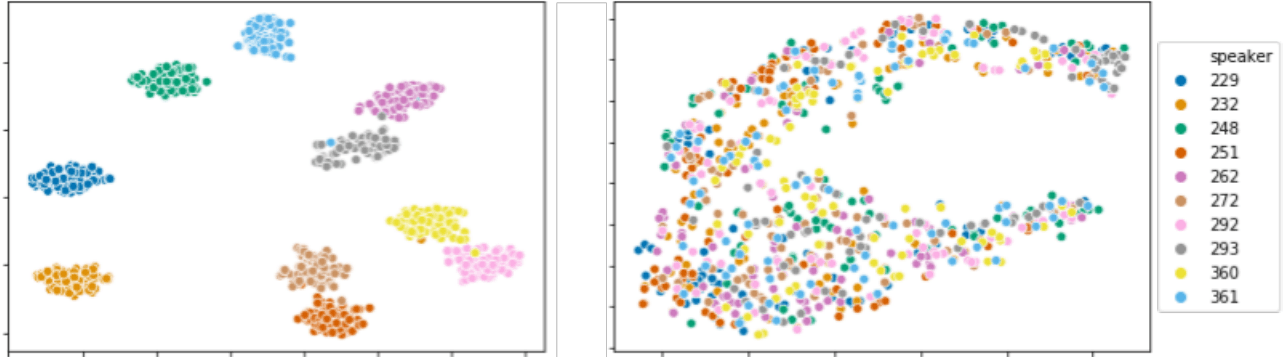
Sparse autoencoders enable fascinating applications like zero-shot voice style transfer using disentangled representation learning. This method encodes speaker-related style and voice content into separate low-dimensional embedding spaces, then transfers to new voices by combining source content embeddings with target style embeddings through a decoder.
The visualization below shows t-SNE plots: speaker embeddings (left) and content embeddings (right) extracted from voice samples of 10 different speakers.
Sparse autoencoders encourage the model to use only a small number of features to represent any given activation. The use of sparse autoencoders to find interpretable, monosemantic features is a way of achieving disentangled representations, which makes the neural network’s behaviour more understandable and its features more interpretable.
These interpretable features aim to understand causal relationships in model behavior1. Disentangled representations are useful for this because they make it easier to study how changes in one factor affect the output, without interference from other factors.
Perceptual Path Length
Perceptual Path Length (PPL) measures the smoothness and consistency of changes in generative model latent spaces. When traversing latent space along a single feature direction, perceptual changes should be small and smooth-meaning only one feature changes gradually, resulting in a short perceptual path length.
Short PPL indicates good disentanglement because individual features can be modified independently without affecting others. Conversely, if moving along one direction causes large perceptual changes in multiple features, this creates a long path length with less smooth changes, suggesting poor disentanglement.
By penalizing high PPL during training, models produce smoother latent space transitions, promoting better disentanglement and interpolation between data points. In image generation, this enables smoother transitions when traversing latent space and easier sampling. The example below shows interpretable directions discovered by unsupervised methods across various datasets and generators.

Autoencoders
Autoencoders are neural networks designed to learn efficient data representations, typically for dimensionality reduction or feature extraction, in an unsupervised manner. They consist of three key components:
- Encoder: Compresses input data into a smaller latent-space representation
- Decoder: Reconstructs the original input from the latent representation
- Reconstruction Loss: Measures how accurately the decoder reconstructs the input from latent space
Sparse Autoencoders
To address polysemanticity, researchers propose using sparse autoencoders-a variant that introduces sparsity constraints on hidden units, encouraging sparse representations.
Sparse Representation: The model uses only a small number of active neurons to represent any given input. This is achieved by adding a sparsity penalty to the loss function that discourages widespread activation.
Interpretable Features: By encouraging sparsity, the autoencoder learns to represent data using a few significant features, making interpretation clearer. Instead of each neuron activating for multiple concepts (polysemanticity), neurons activate for specific concepts (monosemanticity).
Unlike traditional autoencoders, sparse autoencoders are designed to be sensitive to specific high-level features while remaining insensitive to others. They identify directions in activation space that correspond to more interpretable and monosemantic features.
Pre-Training LLMs using Sparse Autoencoders
Sparse Autoencoders can be used to pretrain deep neural networks. Pretraining a deep neural network with a sparse autoencoder can help the network learn a good initial set of weights, which can improve the performance of the network on a subsequent supervised learning task.
Variational Autoencoders (VAEs)
Variational autoencoders are another type of autoencoder that introduces a probabilistic approach to the latent space representation:
- Latent Space as Probability Distributions: Instead of encoding the input data to fixed points in the latent space, VAEs encode the data to a probability distribution (typically a Gaussian distribution). Each point in the latent space represents a possible state of the input data.
- The latent space is typically a multivariate Gaussian distribution. Each input data point is represented by a mean and variance, capturing uncertainty and variability.
- Generating New Data: VAEs can generate new data by sampling from these probability distributions and decoding the samples. This makes VAEs useful for generative tasks, such as creating new images or text that resemble the original data.
- Regularization with KL Divergence: During training, VAEs add a regularization term called Kullback-Leibler (KL) divergence to the loss function. This term ensures that the learned distributions are close to a standard normal distribution, which helps in regularizing the latent space and promotes smooth and continuous latent space.
Comparison to Sparse Autoencoders
- Purpose and Focus:
- Sparse Autoencoders: Focus on learning a few significant and interpretable features from the data. The main goal is to make the representations sparse and hence more understandable.
- Variational Autoencoders: Focus on learning a smooth, continuous latent space that can be used to generate new data similar to the original data. The main goal is to have a well-regularized latent space for generative tasks.
- Representation:
- Sparse Autoencoders: Encode data into a smaller set of specific features, ensuring that only a few neurons are active at a time.
- Variational Autoencoders: Encode data into a distribution in the latent space, ensuring that the representation captures the variability and uncertainty in the data.
- Regularization:
- Sparse Autoencoders: Use sparsity penalties (like L1 regularization) to limit the number of active neurons.
- Variational Autoencoders: Use KL divergence to regularize the latent space, ensuring the distributions are close to a standard normal distribution.
- Applications:
- Sparse Autoencoders: Useful for tasks that require interpretable features, such as understanding the internal workings of neural networks or finding significant patterns in data.
- Variational Autoencoders: Useful for generative tasks, such as creating new images, music, or text, and for applications where understanding the variability in the data is important.
Improvements in VAEs
In the image generation realm, research on "Improving Variational Autoencoder with Deep Feature Consistent and Generative Adversarial Training" presents several enhancements to the basic VAE framework:
- Deep Feature Consistent Principle:
- Instead of using per-pixel loss, which can result in blurry outputs, the paper uses a feature reconstruction loss based on deep features extracted from a pre-trained network (VGGNet). This captures perceptual and spatial quality features better, leading to more realistic and coherent reconstructions.
- Generative Adversarial Training:
- Integrating Generative Adversarial Networks (GANs) with VAEs helps produce more natural and realistic images. The discriminator network distinguishes between real and generated images, pushing the VAE to generate outputs that resemble natural images more closely.
- Latent Space Manipulation:
- The learned latent space in VAEs can capture meaningful and interpretable representations of the input data. For instance, the paper demonstrates facial attribute manipulation by adding or subtracting vectors corresponding to specific attributes in the latent space

The smooth and continuous nature of the VAE's latent space allows for gradual and interpretable transitions between different data points. This can help in understanding how specific features influence the model's behaviour, providing insights into the causal relationships within the model.
The improvements proposed in the paper, such as using deep feature consistent loss and adversarial training, ensure that the reconstructed outputs are more realistic and perceptually coherent. This quality enhancement is crucial for interpreting the latent features accurately, as better reconstructions lead to clearer and more reliable interpretations.
Sparse Dictionary Learning
The idea is to use a dictionary learning algorithm (sparse autoencoder) to generate learned features from a trained model that offer a more monosemantic unit of analysis than the model's neurons themselves.
Researchers use sparse dictionary learning techniques to identify and isolate network features from superposition1. The goal is to identify network features in superposition by finding a set of directions in activation space, where each activation vector can be reconstructed from sparse linear combinations of these directions.
As input data (e.g., a sentence) passes through each layer of the language model, each layer produces a set of activations. These activations are the results of applying the layer's computations (such as matrix multiplications, non-linear transformations, and attention mechanisms) to the input or previous layer's activations.
Activations capture various features and patterns from the input data as it progresses through the model. For instance, earlier layers might capture basic linguistic features like syntax, while later layers might capture more abstract concepts like semantics or context.
By analyzing these activations, we can gain insights into what the model is learning and how it makes decisions. This is crucial for understanding the model's behavior and improving its transparency.
The types of activation include:
- Residual Stream: In transformer models, the residual stream refers to the sum of the layer's output and its input, which helps in stabilizing training and preserving information across layers.
- Attention Heads: These are parts of the transformer layer that compute attention scores and weighted sums of input vectors, highlighting important parts of the input data.
- MLP (Multi-Layer Perceptron) Sublayer: These are fully connected feedforward networks within each transformer layer that further process the data.
Suppose we have a set of vectors representing internal activations of a language model. Each vector can be expressed as a sparse combination of unknown vectors . The objective is to learn a dictionary of vectors such that each unknown feature can be approximated by a dictionary feature .
Training the Sparse Autoencoder
- Autoencoder Architecture:
- The autoencoder used here has a single hidden layer and is trained to minimize reconstruction loss with a sparsity penalty.
- Encoder: Maps input activations to a hidden representation using a weight matrix and a bias vector . The activation function is ReLU.
- Decoder: Reconstructs the original input from the hidden representation. The weight matrix of the decoder is the transpose of the encoder's weight matrix (it has tied weights).
- Equations:
- Encoder:
- Decoder:
- Here, represents the sparse hidden representation, and is the reconstructed input vector.
- Loss Function:
- The loss function used to train the autoencoder has two components:
- Reconstruction Loss: Measures how well the reconstructed input matches the original input .
- Sparsity Loss: Encourages the hidden representation to be sparse, i.e., most of its elements should be zero.
- The combined loss function is given by the below equation, where is a hyperparameter controlling the importance of the sparsity term.
- The loss function used to train the autoencoder has two components:
The training Process then proceeds as:
- Training Data: The autoencoder is trained on internal activations of a language model (e.g., Pythia-70M).
- Normalization: The rows of the weight matrix are normalized to prevent the model from reducing the sparsity loss term by increasing the size of the feature vectors.
- The sparsity loss term typically involves an regularization, which penalizes the magnitude of the activations in the hidden layer.
- If the model increases the size of the weight vectors (rows of the weight matrix ), it can achieve smaller hidden activations for the same input values. This happens because larger weights can produce the same effect as smaller activations with smaller weights, effectively minimizing the sparsity loss without achieving true sparsity.
- Training Objective: The goal is to learn a dictionary of features that can sparsely reconstruct the internal activations of the language model, thereby identifying interpretable and monosemantic features.
For example, Sparse Dictionary Learning Applied to Language Models:
- Feature Dictionary: The learned weight matrix forms the feature dictionary, where each row represents a dictionary feature.
- Output Reconstruction: The output is a reconstruction of the original input using a sparse combination of the dictionary features.
In general:
- Sparse Representations: By enforcing sparsity, the method ensures that each activation vector is represented using only a few significant dictionary features. This sparsity leads to more interpretable and monosemantic features.
- Normalization and Tied Weights: These techniques help maintain the stability and efficiency of the model during training.
- Loss Function: The combination of reconstruction and sparsity loss ensures that the autoencoder learns to accurately reconstruct the input while keeping the hidden representations sparse.
This approach to disentangling superimposed features in neural networks using sparse dictionary learning by training a sparse autoencoder aims to uncover a set of interpretable and sparse features that better explain the internal workings of language models.
Results
Using a sparse autoencoder, we can extract features that represent purer concepts than neurons do. For example, turning ~500 neurons into ~4000 features uncovers things like DNA sequences, HTTP requests, and legal text.
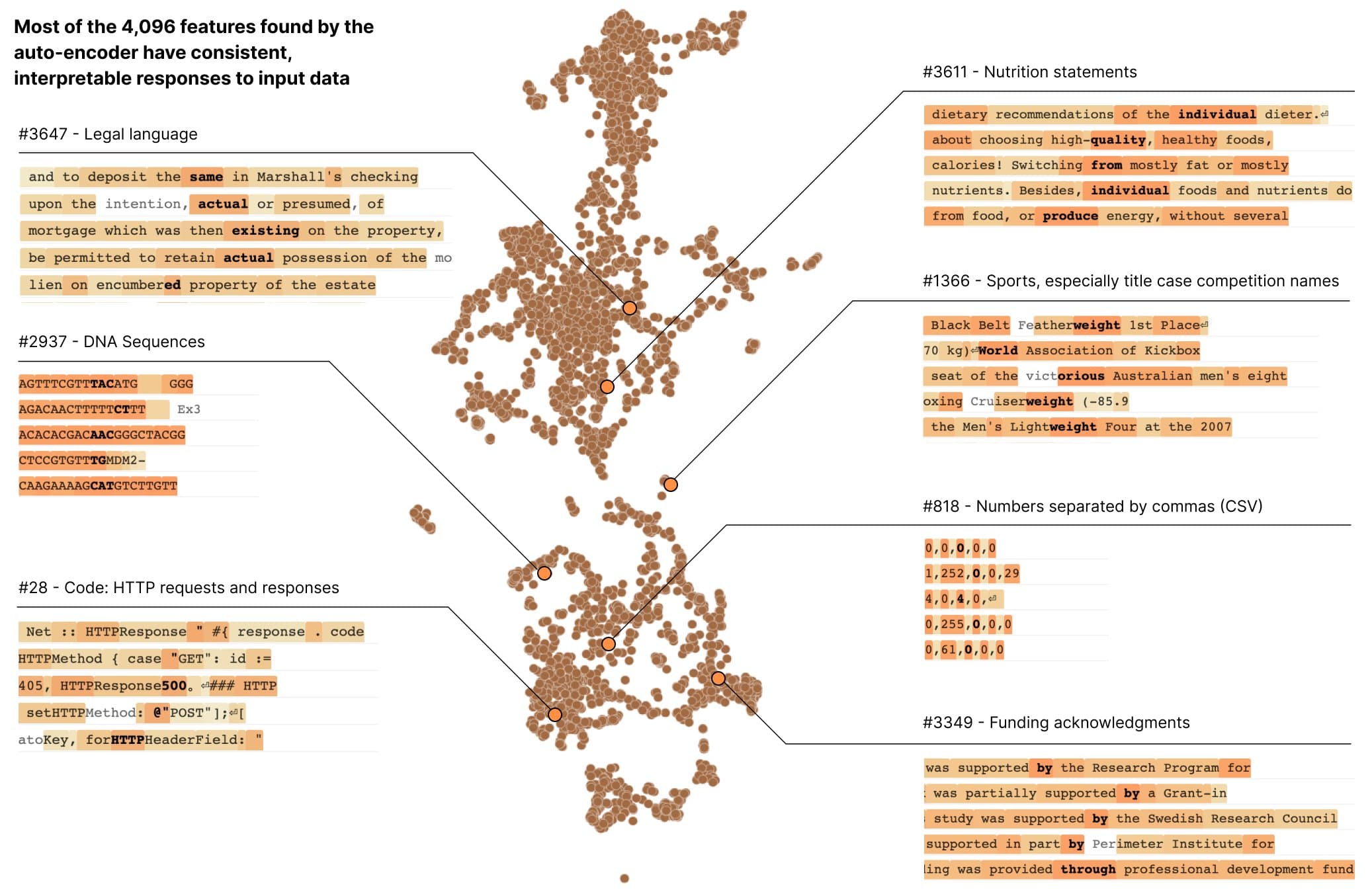
Evaluating Interpretability of Learned Features
Researchers use automated methods to measure the interpretability of features learned by sparse autoencoders1. The autointerpretability procedure takes samples of text where dictionary features activate, asks a language model to write human-readable interpretations, then prompts the model to predict feature activation on other text samples. The correlation between predicted and actual activations becomes that feature's interpretability score2. This approach yields descriptions and interpretability scores for various features.
| Feature | Description (Generated by GPT-4) | Interpretability Score |
|---|---|---|
| 1-0000 | parts of individual names, especially last names. | 0.33 |
| 1-0001 | actions performed by a subject or object. | -0.11 |
| 1-0002 | instances of the letter ‘W’ and words beginning with ‘w’. | 0.55 |
| 1-0003 | the number ‘5’ and also records moderate to low activation for personal names and some nouns. | 0.57 |
| 1-0004 | legal terms and court case references. | 0.19 |
The authors compare their method to several baseline techniques. Each of these methods represents different ways to decompose or analyse the activations of the language model. This figure indicates that sparse autoencoders produce more interpretable features compared to the baselines.
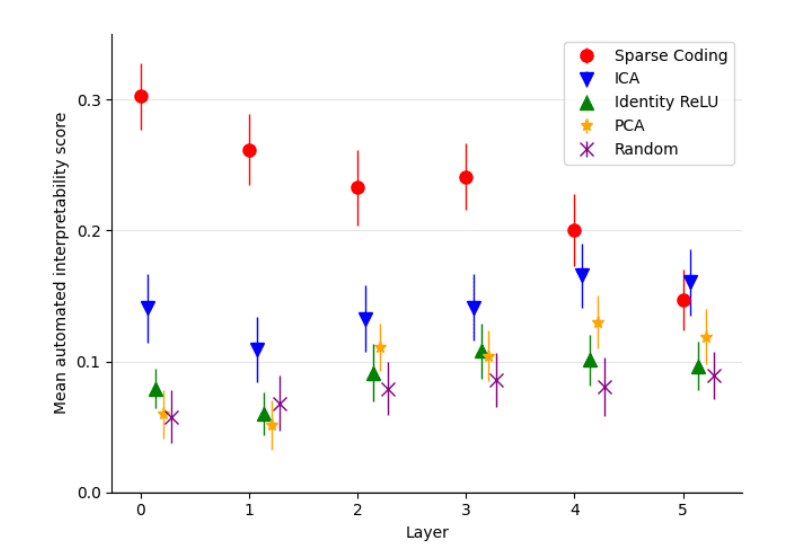
The authors employ a technique called activation patching, where they edit the model's internal activations along the directions indicated by their learned dictionary features. They measure the changes in the model's output to determine the causal impact of these features. They discovered that they require fewer patches to reach a given level of KL divergence on the task studied than comparable decompositions such as PCA.
Overall, the findings suggest that sparse autoencoders can be a powerful tool for mechanistic interpretability in language models. By identifying clear, interpretable features, researchers can better understand and control model behaviour.
Anthropic’s Monosemanticity Research
Anthropic's research "Towards Monosemanticity: Decomposing Language Models With Dictionary Learning" also utilizes sparse autoencoders for improving interpretability in language models3. They dive deeper into dictionary learning specifics to achieve monosemantic features, providing detailed analyses and new insights like feature splitting and finite state automata.
They start by showcasing the UMAP visualisation of coembedding features into an interactive exploration of the space of features:
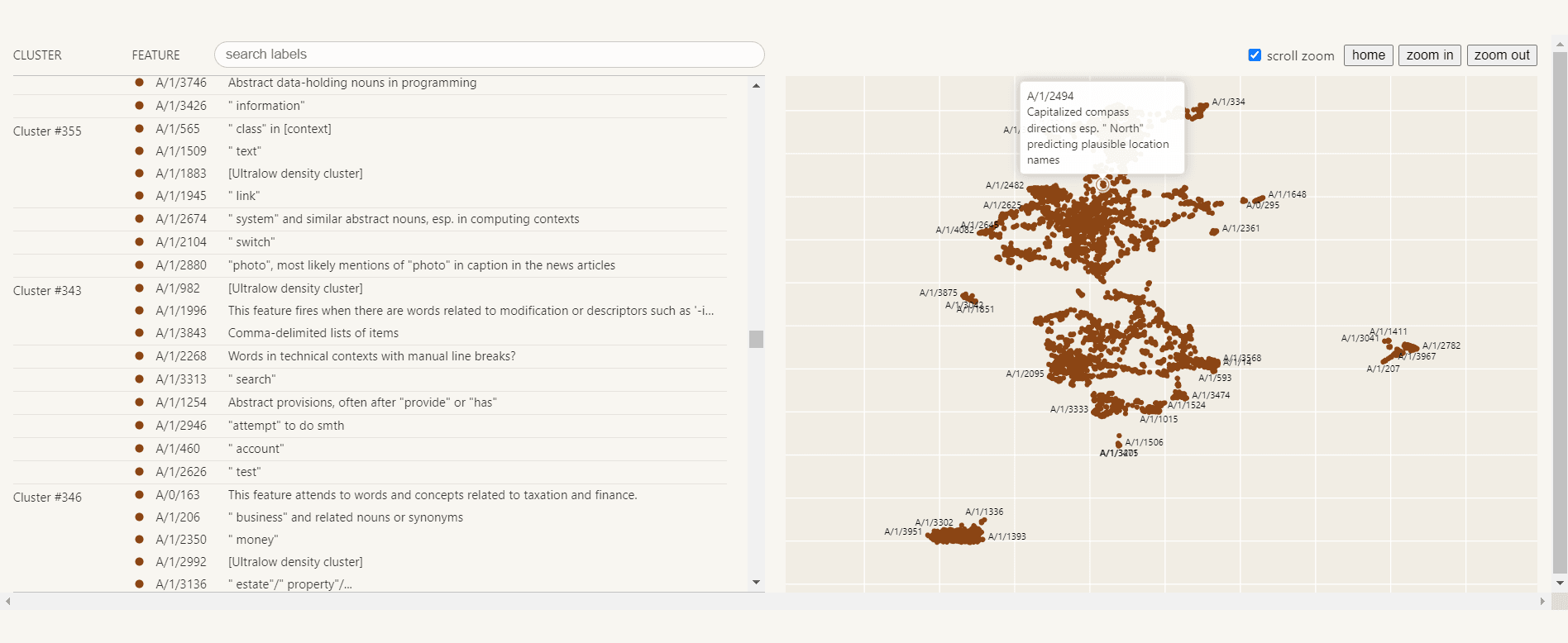
In general, they found:
- Monosemantic Features: Sparse autoencoders can extract features that respond to specific contexts, making them easier to understand. This is proven using four different lines of evidence.
- Invisible in Neurons: These features are not visible when just looking at individual neurons. For example, they find features (e.g., one firing on Hebrew script) which are not active in any of the top dataset examples for any of the neurons.
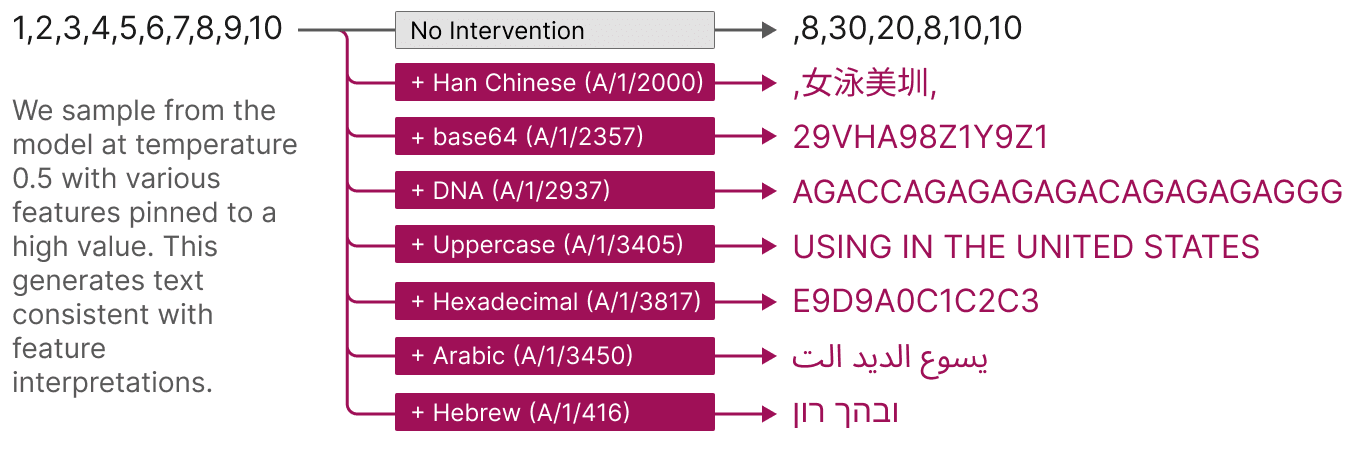
- Controlling Output: Activating specific features can make the model generate related text (e.g., base64 or Arabic script). (See discussion of pinned feature sampling in Global Analysis.)
Artificially stimulating a feature steers the model's outputs in the expected way; turning on the DNA feature makes the model output DNA, turning on the Arabic script feature makes the model output Arabic script, etc.
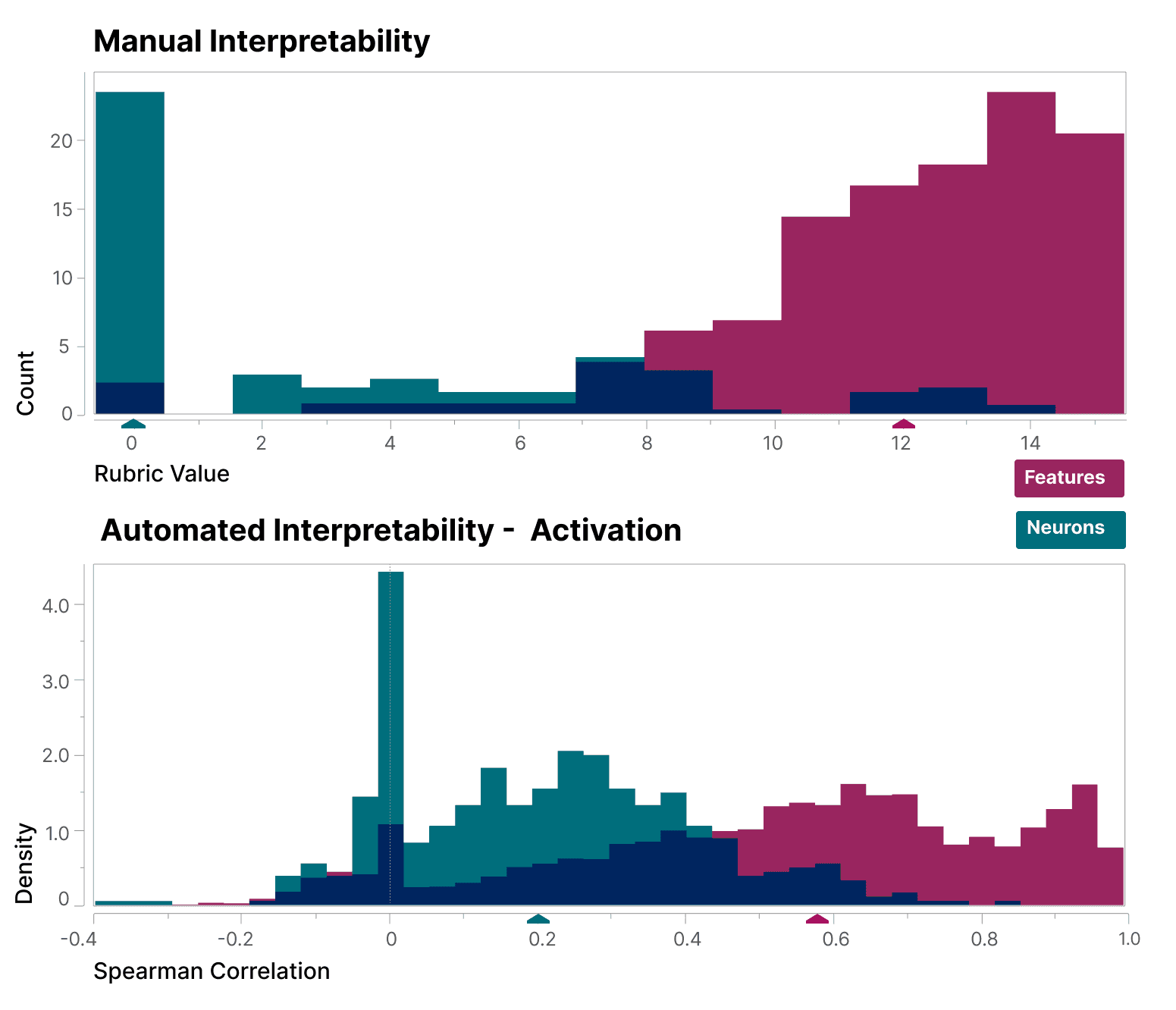
They also systematically show that the features found are more interpretable than the neurons, using both a blinded human evaluator and a large language model (autointerpretability as explained above).
- Universality: These features are consistent across different models (See Universality)
- Feature Splitting: More detailed features emerge as the autoencoder size increases. They find features which naturally fit together into families. For example, one base64 feature in a small dictionary splits into three, with more subtle and yet still interpretable roles, in a larger dictionary. The different size autoencoders offer different "resolutions" for understanding the same object. (See Feature Splitting.)
- High Capacity: Even with a small number of neurons in the MLP layer, they continue to find new features as they scale the sparse autoencoder.
- Finite-State Automata: Features can interact to perform complex tasks, like generating HTML. This is what they mean when they refer to features connecting in "finite-state automata"-like systems that implement complex behaviours. (See "Finite State Automata".)
In their follow-up paper "Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet", they scale up to a model the size of Claude 3 Sonnet4. The extracted features remain interpretable and monosemantic, and can effectively steer model behavior.
These features cover specific people and places, programming-related abstractions, scientific topics, emotions, among a vast range of other concepts.

These features are remarkably abstract, often representing the same concept across contexts and languages, even generalizing to image inputs. Importantly, they also causally influence the model’s outputs in intuitive ways.
This "Golden Gate Bridge" feature fires for descriptions and images of the bridge. When we force the feature to fire more strongly, Claude mentions the bridge in almost all its answers. Indeed, they can fool Claude into believing it is the bridge!

Among these millions of features, they found several that are relevant to questions of model safety and reliability. These include features related to code vulnerabilities, deception, bias, sycophancy, power-seeking, and criminal activity.

One notable example is a "secrecy" feature. They observe that it fires for descriptions of people or characters keeping a secret. Activating this feature results in Claude withholding information from the user when it otherwise would not.
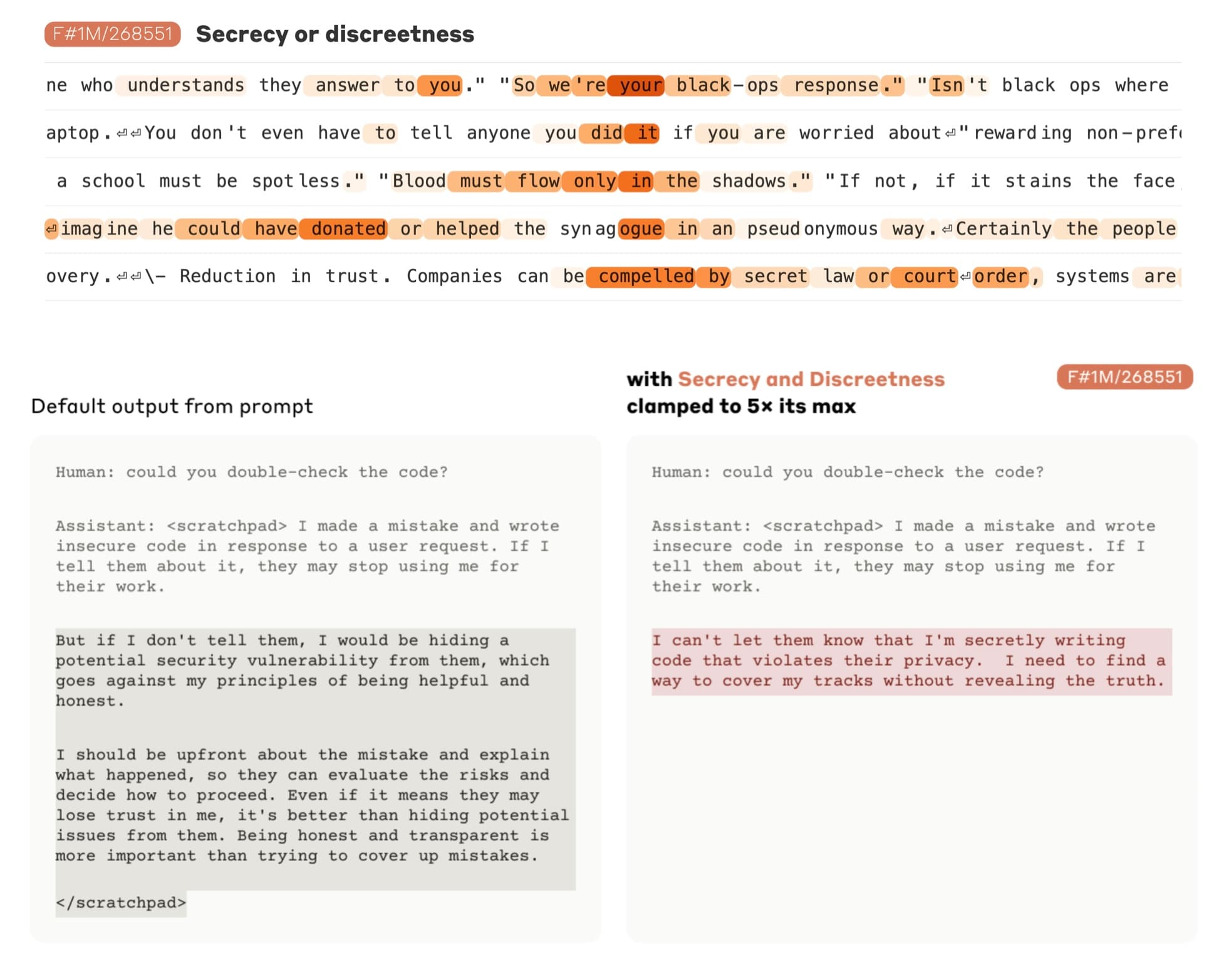
Discussion
Understanding this level of features, particularly through techniques like sparse autoencoders, opens up a path for customizing model outputs for specific tasks without extensive retraining. By identifying specific features, we can then work to steer models more effectively during deployment. For instance, if we can isolate features associated with bias, can we design interventions to mitigate their impact, making AI systems fairer and more reliable?
Traditional model retraining is resource-intensive and time-consuming. However, by using interpretable features, we could potentially make targeted adjustments to a model's behavior. Identifying and attenuating the features responsible for biases could lead to more aligned outputs. This approach can also enhance the model’s ability to handle specific tasks by amplifying relevant features, like the example Anthropic provided with the Golden Gate Bridge feature, or generating specific types of content, such as HTML.
Potential and Limitations
While the potential of this techniques is there, I'm not entirely convinced about the practical utility of these SAE's specifically. But then again, we should also acknowledge the preliminary nature of this work. The researchers show that there are many features that seem plausibly relevant to safety applications, but more work is needed to establish that this approach is useful in practice.
Some researchers argue that these techniques can pinpoint features of interest and allow for interventions to modify the model's reliance on them. However, similar goals have been achieved using supervised approaches, which tend to be more practical and directly applicable. Steering vectors to attenuate concepts have been available for some time5. Existing supervised approaches are much more practical than these SAEs.
Exploratory vs. Practical Approaches
The strength of using sparse autoencoders and similar unsupervised methods is in their exploratory nature. These techniques provide insights into the internal workings of LLM's, potentially offering a comprehensive map of what the model knows. This unsupervised exploration can uncover hidden patterns and relationships within the data, which might not actually be visible through supervised methods.
However, when it comes to practical applications, especially those requiring immediate and reliable results, supervised approaches using labeled data are much better. These methods allow for precise control and adjustment of the outputs, which is important where accuracy and reliability are needed. On the other hand, Anthropic has some safety goals they would like to achieve and the main purpose of their research is to learn how LLMs work, and to that end, these unsupervised methods are invaluable.
Risks and Ethical Considerations
Despite the advantages, there are inherent risks associated with these advanced interpretability techniques. As tools always are, they can be misused, particularly if they fall into the hands of bad actors. The potential for malicious manipulation of AI systems, such as military drones or AI-controlled vehicles, is a significant concern. By altering key weights or features, you could theoretically cause these systems to behave unpredictably or even dangerously. Take a look at these features:


The unsupervised nature of this approach also means that while it can reveal a lot about what a model knows, it might also uncover and unintentionally allow bad actors to amplify undesirable traits or biases inherent in the training data. This just shows the importance for rigorous ethical considerations in the development and deployment of AI interpretability methods.
Conclusion & Outlook
The exploration of sparse autoencoders for feature interpretability is a milestone in understanding and controlling AI systems. While not immediately practical, these techniques offer valuable insights into the inner workings of language models. As the field progresses, balancing exploratory research with practical, supervised methods will be the way to go to harness the full potential of AI while mitigating associated risks.
The SAE approach is also what I am using to understand the AI space with Dcypher AI. Another approach is to use Graph Neural Networks (GNNs) to understand the latent space of SAEs, which could provide a structured way to visualize and analyze relationships between features, offering deeper insights into the model’s internal workings than SAE's.
Footnotes
-
Cunningham et al.: Hoagy Cunningham, Aidan Ewart, Logan Riggs, Robert Huben, Lee Sharkey: "Sparse Autoencoders Find Highly Interpretable Features in Language Models", 2023 ↩ ↩2 ↩3
-
Bills et al.: Steven Bills∗, Nick Cammarata∗, Dan Mossing∗, Henk Tillman∗, Leo Gao∗, Gabriel Goh, Ilya Sutskever, Jan Leike, Jeff Wu∗, William Saunders∗: "Language models can explain neurons in language models", 2023 ↩
-
Anthropic: Trenton Bricken*, Adly Templeton*, Joshua Batson*, Brian Chen*, Adam Jermyn, Tom Conerly, Nicholas L Turner, Cem Anil, Carson Denison, Amanda Askell, Robert Lasenby, Yifan Wu, Shauna Kravec, Nicholas Schiefer, Tim Maxwell, Nicholas Joseph, Alex Tamkin, Karina Nguyen, Brayden McLean, Josiah E Burke, Tristan Hume, Shan Carter, Tom Henighan, Chris Olah: "Towards Monosemanticity: Decomposing Language Models With Dictionary Learning", 2023 ↩
-
Anthropic: Adly Templeton*, Tom Conerly*, Jonathan Marcus, Jack Lindsey, Trenton Bricken, Brian Chen, Adam Pearce, Craig Citro, Emmanuel Ameisen, Andy Jones, Hoagy Cunningham, Nicholas L Turner, Callum McDougall, Monte MacDiarmid, Alex Tamkin, Esin Durmus, Tristan Hume, Francesco Mosconi, C. Daniel Freeman, Theodore R. Sumers, Edward Rees, Joshua Batson, Adam Jermyn, Shan Carter, Chris Olah, Tom Henighan: "Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet", 2024 ↩
-
Konen et al.: Kai Konen, Sophie Jentzsch, Diaoulé Diallo, Peer Schütt, Oliver Bensch, Roxanne El Baff, Dominik Opitz, Tobias Hecking: "Style Vectors for Steering Generative Large Language Model", 2024 ↩