Every SaaS platform I've worked on has the same problem: customer-facing documentation rots the moment the product ships at a decent pace. A product team pushes a feature, the UI shifts, and suddenly half the help articles describe buttons that no longer exist. Those step-by-step walkthroughs with annotated screenshots? Outdated within a sprint. Support tickets pile up asking how to do things that are already documented - just documented wrong.
So we built DORA - a fleet of AI agents that treat your web application like a game of Go, coordinate through a shared graph database, and race to map every reachable state before writing up what they find.
The Exploration Problem
Traditional crawlers follow hyperlinks - fetch HTML, extract <a> tags, move on. That works for static sites, but modern SPAs render content client-side via JavaScript, so a traditional crawler sees an empty container where the application should be. Dropdowns, modals, multi-step forms, dynamically loaded panels - all invisible to anything that doesn't execute JavaScript and interact with the DOM1.
Crawljax was one of the first tools to address this. It fires events in a headless browser, watches the DOM change, and builds a state-flow graph where nodes are unique DOM states and edges are user events2. That was a breakthrough for automated testing. But Crawljax uses a fixed strategy - typically depth-first or breadth-first with pruning rules. It runs a single sweep, produces a graph, and stops.
After 12 years of crawler research, a USENIX Security 2024 study reviewed 7,840 papers and found something striking: proposed and commonly used crawling algorithms offer lower coverage than randomized ones1. No single best configuration exists. Deterministic strategies keep losing to randomness because web applications are too dynamic, too stateful, and too varied for any fixed heuristic to dominate.
DORA fills this gap. Instead of a fixed crawling strategy, it uses Monte Carlo Tree Search to decide where to explore next - the same family of algorithms that powered AlphaGo. Instead of a single sweep, it builds persistent memory across sessions. And instead of one agent, it runs many in parallel, all sharing the same graph.
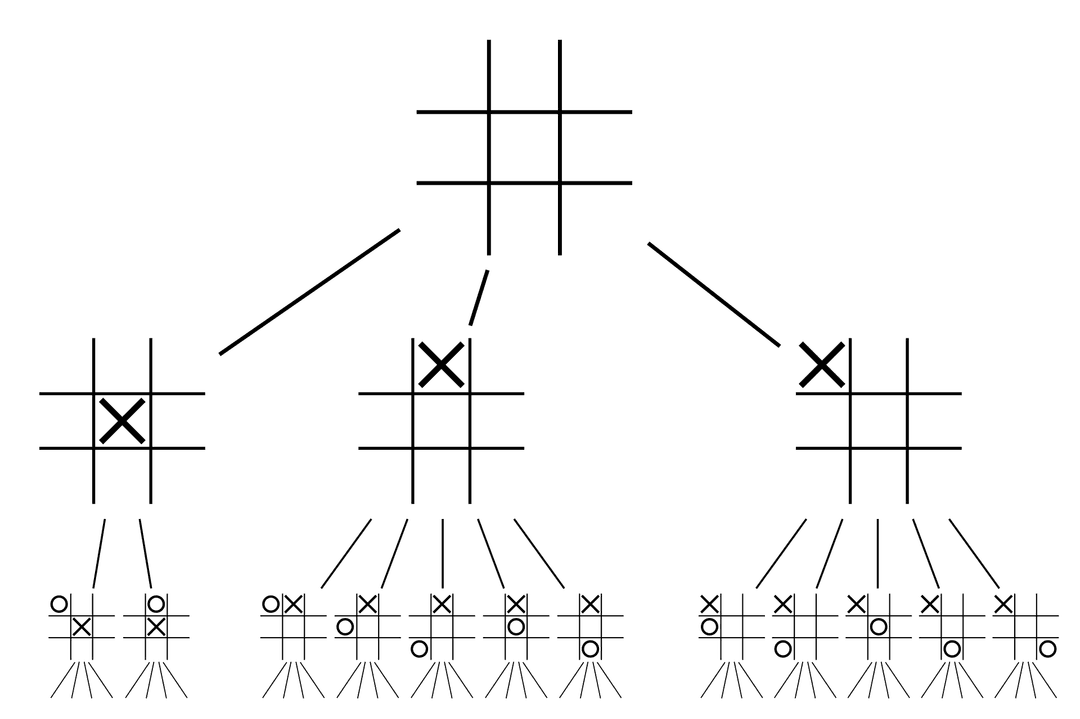
Website as Game
A web application is a game board. Each page is a position. Each click is a move. The full set of possible user paths forms a game tree - the same structure that chess engines and Go programs navigate. A typical SaaS dashboard has 30 clickable elements per page. After three clicks, that's 27,000 possible paths. After five, 24 million. Every button, form field, and dropdown branches into new states, and exhaustive exploration is impossible.
Game theory frames this as an optimization problem: maximize information gained per step. MCTS gives us the algorithm to do it.
Every Element Is a Node
Most web crawlers model pages as nodes. DORA goes finer: every interactable UI element becomes a node in the graph, and interactions between them become edges. This captures state transitions that page-level graphs miss.
Consider a settings page with three tabs. At the page level, that's one node. At the element level, it's three distinct entry points, each leading to different states. A modal dialog that appears when you click "Delete Account" is invisible in a page-level graph - same URL, same page. In an element-level graph, the delete button is a node, and the confirmation modal is a reachable state connected by an edge.
Two states can also share the same URL but differ in content - a form before and after filling, or a page showing different data for different users. Multiple nodes per URL are allowed when content differs.
Every element node carries a composite key: tenantId:elementHash:url. Stable attributes - tag name, text content, DOM path - feed the hash. Multiple agents identifying the same button across sessions converge on the same node without collision.
Synthetic action nodes handle interactions not tied to DOM elements - scrolling, keyboard input, drag-and-drop. Virtual nodes with a standardized key format (interaction_type : url : step_number:action_index), they exist only as edge targets, keeping non-element interactions in the graph without polluting the node space.
Macro-actions go the other direction, grouping multiple low-level steps into a single logical node. A multi-step form fill - entering a name, email, role, and clicking submit - can be abstracted into one "Submit Invite Form" action in the graph. This collapses the branching factor dramatically: instead of treating each field as a separate MCTS decision point, the agent handles the entire form as one move. Common sub-flows become reusable chunks, similar to how RPA tools let you package steps into a single workflow block.
Every node tracks three metrics that drive exploration:
seenCount- how many times the element has been observed in the DOMvisits- how many times it's been interacted withtotalValue- accumulated MCTS reward
High seenCount but zero visits marks a prime target: agents keep seeing it but nobody has clicked it yet.
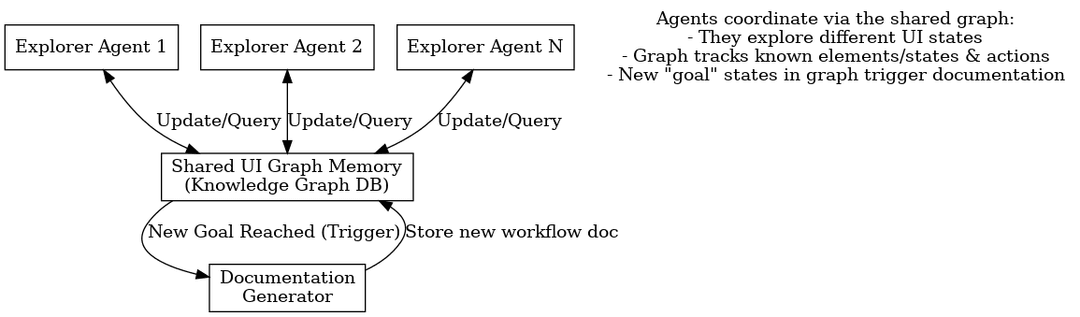
Agents coordinate through a shared graph database, with goal states feeding into a documentation pipeline.
Shared Memory
One agent building this graph is useful. Multiple agents sharing it is where things get interesting.
Every agent reads from and writes to the same graph database in real time - no messaging protocol, no coordination service, no direct communication at all. They talk through the graph. One agent discovers a modal behind a settings gear icon, writes the node and edges, and every other agent immediately sees that path exists. This is a blackboard architecture3, and recent work applying it to LLM multi-agent systems found 13-57% improvement in end-to-end task success4.
The evidence for sharing over isolation is strong. MARG ran five cooperative agents sharing a Q-table against five independent agents and saw 36% more unique states explored5. A 2025 study of 180 controlled experiments confirmed the pattern: decentralized coordination outperformed centralized on web navigation tasks by 9.2%6. Agents that share knowledge outperform the same number working alone - parallelism without coordination is just expensive duplication.
Coordination in DORA happens implicitly through graph coverage gaps. Agents query for unexplored regions and gravitate toward elements with low visit counts. No central dispatcher assigns tasks - the graph's own structure naturally distributes work.
An orchestrator manages lifecycle concerns: spawning agents, assigning coverage goals, monitoring progress. On startup, each agent loads the existing graph and validates key nodes are still reachable, so exploration resumes across sessions rather than starting from scratch.
Agents also specialize. Navigators do breadth-first sweeps across top-level navigation. FormFillers go deep into multi-step forms. Scanners re-verify known pages for changes. Because they share the same graph, a Navigator might discover a form that a FormFiller picks up later.
Exploration temperature varies by role - Navigators run hot (high exploration), FormFillers run cold (focused exploitation).
Shared state cuts both ways though. When I first set off the fleet, the agents shared a browser context with the same cookies and session. One agent decided the most interesting unexplored element on the page was the "Log Out" button. It clicked it. Since they shared cookies, every agent instantly lost its session. I woke up to a hundred agents, all staring at a login screen, all dutifully documenting "How to Log In" from slightly different angles... Agents now get isolated browser contexts.
Concurrency is optimistic: first-write-wins. If two agents discover the same element simultaneously, the first to write the node succeeds, and the second detects the existing record. The graph database enforces a unique constraint on the composite key. In Cypher, this is a MERGE operation:
MERGE (e:Element {compositeKey: $compositeKey})
ON CREATE SET e = $props
ON MATCH SET
e += $non_additive_props,
e.visits = CASE WHEN e.visits IS NULL
THEN 1 ELSE e.visits + 1 END,
e.seenCount = CASE WHEN e.seenCount IS NULL
THEN 1 ELSE e.seenCount + 1 END,
e.totalValue = CASE WHEN e.totalValue IS NULL
THEN $props.totalValue
ELSE e.totalValue + $props.totalValue END,
e.lastSeenAtTimestamp = CASE
WHEN e.lastSeenAtTimestamp IS NULL
OR e.lastSeenAtTimestamp < $props.lastSeenAtTimestamp
THEN $props.lastSeenAtTimestamp
ELSE e.lastSeenAtTimestamp END
RETURN e {.*} AS node_propsAdditive properties - visits, seenCount, and totalValue - increment on match rather than overwrite. Multiple agents can update the same node without losing each other's contributions. MERGE handles the race condition at the database level, no application-level locking required.
Agents query only their local graph neighborhood rather than the full graph, keeping reads fast even as the graph grows. If an agent crashes mid-exploration, everything it already wrote persists for others to build on.
For higher-throughput scenarios, shared transposition tables synchronize value estimates across agents - two agents evaluating the same state converge on the same canonical node rather than maintaining separate estimates.
When strict consistency isn't critical, agents can operate under eventual consistency using conflict-free replicated data types (CRDTs). visits, seenCount, and totalValue are natural CRDTs - increment-only counters that merge correctly regardless of update order.
Edges between elements use the same pattern:
MATCH (source:Element {compositeKey: $source_key})
MATCH (target:Element {compositeKey: $target_key})
MERGE (source)-[r:ACTION {
actionType: $action_type,
organisationId: $org_id
}]->(target)
ON CREATE SET r = $properties
ON MATCH SET
r.timesTried = CASE WHEN r.timesTried IS NULL
THEN 1 ELSE r.timesTried + 1 END,
r.successCount = CASE WHEN r.successCount IS NULL
THEN 1 ELSE r.successCount + 1 END,
r.lastAttempt = $now_tsEvery edge tracks timesTried, successCount, and failureCount, plus the agent's reasoning history, memories, and goals at the time of traversal. Over time, the graph accumulates not just a map of the application, but a statistical model of what works and what doesn't - and why agents made the decisions they did.
Structural knowledge (the graph database) stays deliberately separate from content knowledge (the documentation store). Graphs excel at relationships and traversal - "which states are reachable from here?" Relational stores excel at detailed content and flexible queries - "show me all documentation for the Reports module."
This split mirrors a cognitive science distinction. Semantic memory lives in the graph - structured facts about how the UI connects. Episodic memory lives in recorded flows - specific experiences agents had. Interaction patterns gradually form procedural memory - skills like "how to fill any date-picker widget." Separating these concerns makes each component independently queryable and maintainable.
MAGMA formalized this intuition, representing each memory item across orthogonal semantic, temporal, causal, and entity graphs with policy-guided traversal: 45.5% higher reasoning accuracy while reducing token consumption by over 95%7.
With the shared map in place, one question remains before agents start clicking: how do simulations use all this accumulated knowledge?
Informed Rollouts
Standard MCTS rollouts are random walks - pick an action uniformly, observe the result, repeat. That works when the search space is small. In a web application with thousands of reachable states, random walks waste most of their time on dead ends that previous agents already hit. DORA's rollouts are biased by institutional memory: the annotations agents leave on graph edges as they explore.
During simulation, transition probabilities shift based on edge metadata. Edges whose memory annotations contain goal-relevant terms - action verbs matching the current exploration objective - get higher selection probability. Already-visited states are discounted proportionally to their visit count, nudging simulations toward frontiers. Terminal states whose recorded text contains success indicators ("saved," "created," "confirmed") receive bonus rewards, pulling simulations toward productive outcomes.
The effect is that simulations reflect collective experience rather than blind chance. "What happened when another agent clicked this button?" is encoded in the edge's memory field, and the rollout policy reads it. No direct agent-to-agent communication exists - memory flows through the graph. A navigator's failed attempt at a form submission biases a form-filler's future rollout away from the same mistake, without the two ever exchanging a message.
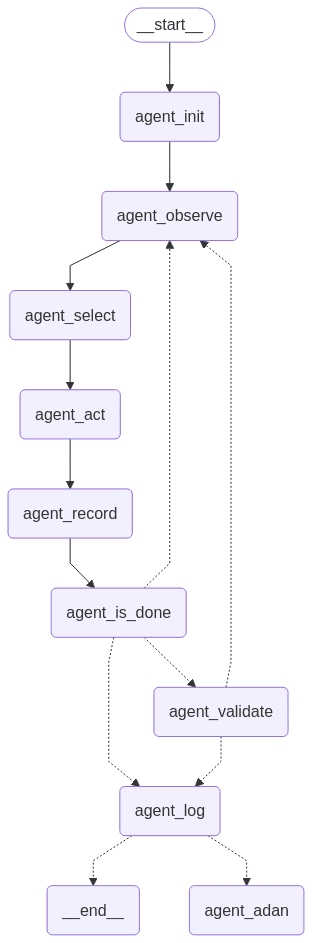
The Agent Loop
Each agent runs an eight-node state machine: Init, Observe, Select, Act, Record, Is_Done, Validate, and Log. To see how these fit together, follow a single agent as it discovers an invoice creation flow.
Init is mostly bookkeeping: navigate to the start URL, build the conversation context - system prompt, tool-call example, task prompt.
Then comes the interesting part. Observe pulls the current DOM, converts every interactable element into a local node, and batch-upserts them to the graph database. (Where DOM access isn't available, vision-based parsers like OmniParser extract structured element descriptions from screenshots at 0.6 seconds per frame8.) If this isn't the first step, edges get created from the previously interacted element to newly discovered ones. Observe builds a frontier - the set of possible next moves - by annotating each element with its exploration priority:
UNEXPLORED - no graph data at all (highest priority)
HIGH - seenCount > 0, visits = 0 (seen but never clicked)
HIGH - visits = 0 (never visited)
MEDIUM - seenCount > visits * 3 (rarely clicked relative to exposure)
MEDIUM - visits < 3 (few interactions)
LOW - visits >= 3 (frequently visited)What the LLM sees, inline with each element:
14[:]<button>Create Invoice</button> [Graph Data: seenCount=5, visits=0 | HIGH PRIORITY - Seen but never visited]
15[:]<button>Cancel</button> [Graph Data: seenCount=5, visits=4 | LOW PRIORITY - Frequently visited]
16[:]<a>Reports</a> [Graph Data: UNEXPLORED | HIGHEST PRIORITY - No data]Not just the page - the page overlaid with exploration history.
With this annotated view, Select calls the LLM to decide what to do next. It receives the element list, a screenshot, and a strategy prompt that prioritizes unexplored elements and breadth-first exploration. In our invoice example, "Create Invoice" has been seen five times but never clicked - high priority. So the LLM picks it.
Act clicks the button, waits for DOM stability, and takes a screenshot. Record captures everything - LLM output, browser state, action outcome - as a history item that feeds into future decisions and documentation generation.
After each action, Is_Done checks: did I signal completion? Did I hit the step limit? Or should I loop back and observe the new page? Most of the time, it loops. Clicking, recording, and observing until the agent either finishes a workflow or runs out of steps.
On completion, Validate evaluates what was found against six criteria. Workflow completion checks whether the agent finished an end-to-end process, not just a single click. Feature discovery asks if a significant capability was uncovered that isn't already documented. UI navigation scores non-obvious paths - reaching a settings panel through a keyboard shortcut rather than the menu, for instance.
Form requirements captures validation rules and field constraints triggered. Error handling evaluates whether meaningful error states were encountered and how the agent recovered. Novelty assessment checks the graph: if similar flows already exist in the knowledge base, the discovery isn't worth a new document. Only discoveries meeting multiple criteria pass.
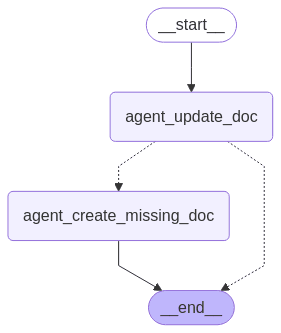
If validated, Log triggers a documentation subagent. It queries the documentation store for existing articles covering similar workflows, using semantic similarity against the exploration history. Above a confidence threshold, it updates the existing document - adding steps the original missed, correcting outdated instructions, noting alternative paths. Below the threshold, it creates a new workflow document from scratch.
Ten agents discovering the same "Create Invoice" flow produce one comprehensive article, not ten redundant ones. Without validation, the run gets marked incomplete with partial data recorded for debugging.
Below is the full agent loop - an eight-node cycle from Init through Log, with the branch to the documentation subagent on successful validation. Most runs cycle through Observe-Select-Act-Record until completion or the step limit.
Its documentation subagent has its own two-node state machine: first attempt to update an existing document, then create a new one if no match is found.
The Fleet
The loop above describes one agent. In practice, a fleet of specialized agents divides the work.
An authentication agent handles login and session persistence. It holds credentials, manages tokens, and exposes a circuit breaker: when authentication fails, all agents halt until the session is restored. This prevents a fleet of explorers from hammering a login screen after an expired token.
A quality gate runs checks before documentation publishes - broken links, readability scoring, tone consistency, content completeness. A decomposition agent breaks published guides into atomic step-by-step walkthroughs. A consolidation agent merges them back into comprehensive guides. This split-merge cycle matters: atomic walkthroughs can be independently validated, updated, and re-explored without touching the parent guide. When individual walkthroughs improve, the consolidation agent weaves updates back into the comprehensive version - a map-reduce pattern for documentation maintenance. A diff agent scores proposed changes on four axes: clarity, accuracy, completeness, and relevance.
A reactive documentation agent monitors incoming customer questions. Each question is matched against the existing knowledge base via vector similarity. High-confidence matches trigger updates to the relevant document - adding a missing step, clarifying ambiguous language. Low-confidence misses create gap records that explorers pick up on their next cycle. The feedback loop is tight: a support question today becomes a documentation improvement tomorrow and a reduced ticket volume next week.
Three distinct capability tiers handle different workloads. A vision-capable reasoning model makes real-time exploration decisions - what to click, when to stop, how to interpret a screenshot. A fast classifier handles binary checks: loop detection, duplicate state identification, "is this element interactive?" A prose model generates and refines documentation text. The circuit breaker pattern propagates across all tiers - when the authentication agent trips it, every agent in the fleet parks until the session resets.
Exploration Strategy
The Select node is where each agent decides what to click next - and that decision is driven by MCTS.
MCTS works by running simulated explorations. It picks a path through the tree, follows it to see what happens, and updates its scores. Paths that discover new pages get higher scores. Over time, the search converges on the most productive actions without trying every combination.
Think of the difference between randomly clicking everything on a page and strategically clicking the "Create Invoice" button because simulations showed it leads to five undiscovered screens.
Four phases, all adapted for web exploration. First, selection: from the current state, pick an action using UCT (Upper Confidence Bound for Trees). Each unexplored element is a slot machine with unknown payoff - the multi-armed bandit problem - and the agent must decide which to pull next.
UCT balances exploitation of known-good actions with exploration of untried ones: . Actions with high average reward and actions that haven't been tried much both score well.
Execution follows. If the resulting state is new, it enters the graph. From there, the agent estimates future reward - either through a random rollout or a biased one using heuristics like "fill all required fields, then submit." Finally, backpropagation: updating the values of every node along the path so actions leading to new discoveries accumulate higher scores.
A critical constraint keeps search tractable: agents only consider elements visible in the current DOM. You can only click what you see. This prunes the action space from thousands of known graph nodes down to the few dozen on the current page, dramatically reducing the branching factor.
Several refinements make this work for web exploration specifically.
Temperature scaling controls the exploration/exploitation balance per agent. Instead of always picking the UCT-max action, agents sample probabilistically: probability of selecting action at state is proportional to . High spreads probability across actions (more exploration). Low concentrates on the best-known action (more exploitation). Different temperatures create diversity - one agent always exploring, one always exploiting, others in between. The selection pipeline section below covers how temperature interacts with other scoring signals.
Pages with dozens of clickable elements would overwhelm a naive search. Progressive widening addresses this: on first visit, only a few actions get considered. Each subsequent visit "unlocks" more, following the rule: expand when . Early computation focuses on the most promising actions before gradually widening.
Semantic understanding biases search too. Reading element labels, predicting function - "Cancel" versus "Save," "Delete" versus "Create" - and grouping related form fields into single logical actions (filling "First Name" and "Last Name" together rather than treating them as separate MCTS branches). Predictions become prior probabilities that guide which actions get expanded first9.
Reward shaping adds intermediate signals beyond "found a new page." Depth-based shaping gives +0.1 for each new depth level, encouraging agents to drill into menus rather than cycling on shallow links. Revisiting already-known states gets penalized. If exploration stalls, the system temporarily boosts novelty rewards to push agents into unexplored territory10.
Reward schedules adapt over time. Early exploration rewards breadth - every unique page discovered gets a high reward. Late exploration shifts to thoroughness: completing forms end-to-end, covering edge cases, testing validation rules.
Form exploration deserves special attention. A form with five fields isn't one action - it's thousands of possible submission paths depending on which fields are filled, what values are used, and what order they're submitted. Agents maintain a small library of synthetic test data for common field types (emails, names, phone numbers, dates, edge-case values like empty strings or SQL injection attempts).
Different inputs can trigger different validation rules, error states, or even entirely different subsequent pages. A shipping form submitted with a domestic address might lead to a different confirmation flow than one with an international address. By systematically varying inputs across runs, agents gradually map not just the form's happy path but its full behavior space - which fields are required, what formats are accepted, which combinations trigger errors.
Per-agent reward differentiation adds another axis. One agent gets higher intrinsic reward for uncovering new states (the explorer), while another gets higher reward for reaching known goal states quickly (the navigator). Unlike temperature, which controls how randomly an agent picks actions, reward differentiation controls what each agent optimizes for.
Beyond pure exploration, agents can exploit the graph as a navigation map. If an agent needs to reach a deep page it hasn't explored yet, it can replay a known login-and-navigate sequence to get there quickly rather than re-discovering the path from scratch. This goal-directed exploitation - using the graph as a GPS to reach unexplored branches - is one of the advantages of persistent memory.
Partial backpropagation addresses a multi-agent timing problem. In classical MCTS, rewards propagate only after a full simulation. With many agents running in parallel, that creates stale information. PPB-MCTS sends intermediate backpropagation messages during lengthy simulations, so parent nodes get updated sooner and other agents can immediately benefit11.
Learned value functions could replace or augment random rollouts. LATS (Language Agent Tree Search) demonstrated that LLMs themselves can serve as value functions, with self-reflection improving exploration over time12. A model trained on past exploration data predicts "likelihood this action leads to new pages" and feeds that directly into MCTS node evaluation - the same approach AlphaZero used for Go, applied to web exploration.
SWE-Search extended this with a hybrid value function combining numeric scores and qualitative LLM feedback13. Search provides training data, and the trained model makes search more directed - a self-reinforcing loop.
World models push this further. WebWorld, the first open-web simulator trained on over one million web interactions, supports 30+ step simulations and outperforms GPT-5 as a world model for inference-time search14. With a good world model, MCTS doesn't need live browser rollouts at all - it can simulate hundreds of action sequences offline and pick the most promising ones before touching the real page.
MC-DML showed that combining Monte Carlo planning with in-trial and cross-trial memory lets agents dynamically adjust value estimates from past failures, without iterative retraining15. This means DORA agents could start each session already biased toward productive strategies from previous runs.
Selection Pipeline
MCTS picks the branch. Within each branch, dozens of elements compete for the next click. A composite scoring pipeline ranks them.
Six components contribute to each element's score, ordered by weight. Novelty decays with step number - early steps reward discovery, later steps reward completion. Text relevance boosts action verbs ("Create," "Submit," "Configure") and penalizes retreat actions ("Cancel," "Back," "Close"). Element type matters: buttons and links outrank static text. CSS prominence - size, position, contrast - acts as a proxy for importance. Q-values from past exploration runs get sigmoid-squashed to prevent any single historical signal from dominating the score. A vision-capable model provides the highest-weighted signal: it sees the element list, past memories from the same page region, and a screenshot, then ranks candidates directly.
The vision model also acts as a veto. It can assign negative scores to elements it judges regressive - a "Back" button when the agent should be drilling deeper, or a "Cancel" link mid-form. Negative scores get amplified: they halve any positive heuristic score on the same element. This lets the model override pure statistics when the visual context tells a different story. If the model is unavailable, the system degrades gracefully - heuristic scores still produce reasonable rankings, just without the contextual override.
A navigation curriculum shapes scoring across steps. Step one forces top-level navigation: non-navigation elements receive heavy penalties, pushing agents to pick a section before diving deep. Step two is deliberately the hottest temperature in the sequence - maximum diversity immediately after committing to a section, so parallel agents scatter across different subsections. Subsequent steps cool progressively toward exploitation. The vision model's ranking prompt changes per step to match: "which top-level section is least explored?" on step one becomes "which element advances the current workflow?" on later steps.
Per-agent strategy diversification adds implicit task division. Each agent derives a deterministic strategy seed from its identity - one agent might weight novelty higher, another might weight content relevance. No explicit coordination needed. The fleet naturally partitions the exploration space because agents with different scoring biases gravitate toward different parts of the application.
Goal Detection
MCTS drives exploration. Knowing when to stop and document is a separate problem. Four signals mark meaningful end states:
- Confirmation messages like "Success!" or "Your changes have been saved" after an action sequence
- Redirects to summary pages, dashboards, or receipt screens
- Terminal states with no meaningful outgoing actions, just "Close" or "Back" buttons16
- Data changes: new items appearing in a list after creation, updated values after editing, deleted records disappearing
Say the agent takes these raw actions:
- Click "Team" menu
- Click "Add Member" button
- Fill "Name" with "Alice"
- Fill "Email" with "alice@example.com"
- Click "Invite"
When the goal detector sees "Member invited successfully," it flags a completed workflow. An LLM then transforms the raw action sequence into documentation:
Flow: Invite a New Team Member
- Navigate to the Team section from the main menu.
- Click the Add Member button to open the invite form.
- Enter the member's name and email address in the form fields.
- Click Invite to send the invitation.
- You should see a confirmation message "Member invited successfully."
Documentation is stored at the workflow level, not per page. Each document covers a user objective - "Invite a Team Member" is one flow spanning multiple pages. In the graph, workflow nodes are first-class entities linked to their start and end states, essentially labeled paths that have been identified as meaningful. If any page in the flow changes, the system knows which documentation might be affected.
Graph-based documentation is modular. Each node stores documentation snippets, so updating a single element's description cascades to every walkthrough that passes through it. If "Invite" changes to "Send Invitation," every guide referencing it updates in one place.
Documented sequences also double as interactive walkthroughs. A recorded exploration can be replayed step by step as an in-app guided tour - the system highlights each element in turn, prompting the user to perform the same action. If a support agent records a troubleshooting procedure, that exact click-path becomes a reusable tutorial for any user facing the same issue. Unlike screen recordings that break the moment a button moves, graph-based walkthroughs adapt automatically when the underlying UI changes.
Progress tracking per user - which tours they've completed, which are in progress, which haven't been started - lets the system skip ahead when prerequisite steps are already done, like a GPS recalculating after you've already made the first three turns.
Analytics come for free: measuring edge frequency reveals which paths users take most often, where they hesitate, and where they drop off.
Goal hierarchies can get complex. "Complete Onboarding" might involve "Fill Profile Info" and "Upload Documents" as sub-tasks. Dependencies are representable in the graph, though the initial implementation treats each goal independently and lets the documentation agent handle grouping.
Multiple agents might discover different paths to the same end state - one creates an invoice through the dashboard, another through the quick-action menu. Rather than storing these as separate workflows, the system detects the shared goal state and records variants as alternate paths. Documentation presents users with the shortest or most common route while acknowledging alternatives exist.
Redundant work gets actively avoided - before taking an action, agents check whether the exact state-action pair has been performed before, and graph-based loop detection prevents cycles by refusing to traverse an edge back to a state already in the current path.
Visit-count thresholds mark elements as "fully explored" after N interactions that always led to the same result, while periodic re-checks verify key flows still work and memory cleanup prunes stale nodes to keep the graph from bloating as the application evolves.
But agents exploring the same application inevitably reach the same pages through different paths. The homepage from the navigation menu and the homepage from a "Back to Dashboard" link are the same state. Without deduplication, the graph bloats with redundant nodes and agents waste time re-exploring known territory.
Deduplication
DORA uses several layers to detect and merge duplicate states:
Fingerprinting comes first. SimHash computes a hash of each state's DOM content. If the Hamming distance between two hashes falls below a threshold, they're treated as near-identical17 - catching trivial variations like timestamps or user-specific greetings.
Transposition tables from game MCTS map these hashes to canonical graph nodes. Different paths converge on a single node, collapsing the search tree into a directed acyclic graph. Tree size shrinks to unique state classes where 11.
Graph embeddings go deeper. Node2Vec or graph neural networks encode structural position, so two states with the same outgoing actions and predecessors - even with different URLs - land close in vector space. A login page reached from the homepage and one reached from a deep link are structurally identical; embeddings catch that.
Clustering-based methods like DBSCAN group state feature vectors, merging nearby states into equivalence classes. I can imagine here that some ML technique to compare screenshots and output similarity scores, catching cases where DOM differs but rendered pages look identical, would also be useful here. Two pages using different CSS frameworks that render the same UI need this visual layer.
Judge (ACM TOSEM 2025) showed the most promising approach for web GUI testing: a "merge-and-classify" strategy that iterates through the DOM tree, merging sibling elements with identical subtree structure, then embeds simplified DOMs via contrastive learning18. Pages that are logically identical (same form, different data) get pulled together; pages that look similar but serve different functions get pushed apart. This handles the hardest cases - dynamic content causing raw DOM differences between pages in the same logical state.
Per-site tuning happens automatically through temporal DOM analysis. Every interaction saves the DOM state, so over time the system learns which parts of each site's DOM are stable and which are volatile. If an element's id attribute stays consistent across dozens of visits, it gets weighted heavily in the identity hash. Class names that change on every page load (common with CSS-in-JS frameworks) get downweighted.
Stable modal render order becomes a reliable signal; inconsistent render order gets deprioritized in favor of other attributes. No manual configuration - the system watches what stays the same and what doesn't, then adjusts its identity function accordingly.
At the element level, each node generates a signature from tag name, id, classes, text content, and XPath. Crawljax pioneered this2. DORA extends it with the composite key (tenantId:elementHash:url). If a button moves from a sidebar to a modal but keeps its id and text, the system updates the existing node rather than creating a duplicate.
Deduplication keeps the graph clean, but not every action succeeds in the first place.
Failure Handling
When an action fails - no state change, an error message, a 404, a disabled button - the agent marks that edge with a failure flag. Future agents see the annotation and deprioritize that action.
Consider a "Submit" button that triggers a validation error - "Email is required" - that the agent can't resolve because it never filled the email field. The edge gets marked as failed with the error message attached, and the next agent encountering that form sees the annotation and fills required fields before attempting submission.
Different failure types get different treatments: a 404 link gets a staleness timestamp so no agent follows it again until the next graph refresh, while a greyed-out "Export" button gets flagged as disabled - agents skip it until some other exploration path (like completing a prerequisite workflow) enables it, at which point the changed state triggers re-evaluation.
None of these failures are wasted. If a step sequence consistently fails, an agent tries a different order or skips a step entirely. Over time, the graph accumulates a statistical picture of what works and what doesn't at each point in the application19.
Graph-based cycle detection catches structural loops - don't traverse an edge back to a state already in the current path. But semantic loops are subtler: an agent clicking different buttons that all lead to the same outcome, or filling a form three different ways that all trigger the same validation error. After a configurable number of steps, a fast classifier receives the full action history and makes a binary judgment: is this agent stuck? It catches patterns that graph traversal misses because the states are technically distinct but functionally identical. When a loop is confirmed, the system still salvages partial documentation from whatever the agent discovered before getting stuck.
Between successful explorations, failed attempts, and deduplicated states, the graph gradually forms a comprehensive map. It also reveals exactly where that map has gaps.
Knowledge Gaps
What's missing shows up as clearly as what's been found.
This is where the graph's ontology pays off. Because every element, edge, and workflow is a structured node with visit counts, timestamps, and success rates, gap detection isn't a separate system - it's actually about querying the graph. A page in the graph with no documentation entry is an undocumented feature, and a documented page whose DOM hash has changed since the last crawl has potentially stale documentation.
The same ontology enables questions we didn't originally build for. Which features have the lowest visit-to-documentation ratio? Which workflows do agents consistently abandon halfway through - suggesting the UI is confusing enough that even automated exploration gets lost? Which sections of the app have high edge failure rates, hinting at flaky UI or unclear affordances?
Gap detection runs after each exploration cycle in six steps:
- Detect new or changed pages
- Flag undocumented states and generate initial drafts using LLM summarization
- Update existing documentation where content has changed
- Write back incrementally to the documentation store
- Review flagged drafts (human or secondary validation agent)
- Monitor continuously - the pipeline repeats as the application evolves
Every documentation entry stores references to source DOM selectors and text, maintaining traceability back to the actual UI. Stakeholders can query for reports like "10 pages have auto-generated drafts pending review" or "5 pages have potentially outdated documentation."
Coverage analysis goes beyond pages. Menu items serve as a natural checklist - if top navigation has sections A, B, and C, and the graph shows extensive coverage of A and B but barely touches C, that's a clear gap. Coverage isn't just "which pages have we visited" but "which goals have we achieved."
Quantitative stopping criteria prevent agents from thrashing once coverage plateaus: explore until a target percentage of unique states are discovered, or halt when no new states appear within the last N actions.
Gaps tell you what's missing. Staleness tells you what's wrong - a workflow that no longer matches the live UI actively misleads.
Staleness Detection
A recorded walkthrough says "click the blue Save button in the top-right corner." If the button moved to a toolbar or disappeared entirely, that walkthrough is now harmful documentation. A validation agent replays walkthroughs against the live application step by step to catch exactly this.
For each step, the agent locates the original element in the current DOM using stable semantic attributes: test IDs, ARIA labels, roles, names, hrefs. Volatile attributes - class names, generated IDs, inline styles - are explicitly ignored. The matching uses a composite score: tag name gates entry (a <button> never matches a <div>), then stable attribute overlap, text similarity at both the substring and word level, and exact matches on key identifiers each contribute weighted signals.
Elements that moved proceed. A button relocated from a sidebar to a toolbar has the same identity in a different position - that's a layout change, not an invalidation. Elements that disappeared are genuine failures. This distinction matters: flagging every CSS change as staleness would drown the signal in noise. Only semantic changes - missing elements, altered labels, broken interaction chains - mark a walkthrough as stale.
Before investing browser resources in replay, a text validation layer screens walkthrough prose for placeholder content and quality issues. Drafts containing template markers, incomplete sentences, or placeholder screenshots get caught early, keeping the replay pipeline focused on substantive validation.
Use Cases
Everything above produces one automated resource: the validated click-paths. Three concrete outputs fall out of it.
Auto-Generated Tutorial Videos
Every click-path an agent records is already a storyboard. The action sequence is the script outline, the screenshots are the frames, the highlight annotations mark where attention should land. Its a natural next step to add narration, voice over (we have instructions already from the walkthroughs), smooth camera movement - and the recorded exploration becomes a tutorial video without anyone touching a video editor.
Here's one we generated for Clay's product, auto-narrated from a single recorded click-path:
For each step in the recorded path, a prose agent writes narration from the action context: what to click, what to expect next, why the step matters. A text-to-speech service voices it. Each screenshot is held for the length of its audio, then the system composites the lot - narration, frames, optional background music - into a final MP4.
Camera moves come from the screenshots themselves: computer vision finds the highlight annotation in each frame. When consecutive highlights sit close together, the video uses a smooth pan. When the highlight jumps from a sidebar to a distant panel - or from one page to another entirely - the system triggers a zoom-out, hold, zoom-in sequence so viewers don't lose their place. No action metadata required; the pipeline reads everything from the annotated screenshots.
That decoupling is what makes the whole thing cheap. Exploration agents don't know videos exist - they click, record, and move on. Any validated walkthrough in the graph can be re-rendered into a tutorial without touching the agent loop. Swap the voice, drop in new background music, recolour the highlight for a customer's brand - all downstream concerns. The click-path is the source of truth.
Live Walkthroughs
That source of truth isn't only good for video. Every recorded click-path can also run live inside the customer's own product - the same highlights, the same popovers, the same step sequence, but overlaid on their real UI rather than a rendered MP4. We packaged the runtime as an NPM module, @sammy-labs/walkthroughs, so any team on React or Next.js could drop a provider into their app and trigger a recorded walkthrough on demand.
Users see a guided tour through the live application: the page dims, a highlight ring lands on the next element, a popover explains what to click and why. Click through, advance to the next step. Underneath, the library handles the awkward bits - SPA route changes, reliable element matching, lazy-loaded modals that mount after the page settles, elements that moved between record and replay, auth tokens that expire mid-walkthrough.
The walkthrough can also listen, not just instruct. At any step, the popover can offer an input field for a typed question, surface relevant FAQ content, or hand the user off to support without dropping them out of the overlay.
Same data, different output. The click-path behind the Clay tutorial video above can also drive a live walkthrough in Clay's own product, with no second recording. When the product team ships a new screen, the agents go back, walk the new flow, and every embedded walkthrough that touches it updates from the same graph.
Living Documentation
The opening of this post was about documentation rot - features ship, the UI shifts, the help centre lags. Running this fleet against a customer's product closes that loop.
A product team ships a new screen on Tuesday; by Wednesday morning, the exploration fleet has walked the new flow, drafted the article updates, and queued it for publish to the CMS. No one filed a "please update the help centre" ticket - the new state showed up in the graph as an undocumented node, and the documentation agent picked it up on the next pass. Auto-publish, which some customers opted for, means they never have to write product documentation again. No more sitting and taking screenshots of a UI that changes constantly for the sake of docs.
None of these use cases - tutorial videos, in-app walkthroughs, self-updating docs - rest on entirely new techniques. DORA assembles ideas from several fields, each shaping a different part of the architecture.
Prior Art
Crawljax introduced the element-level graph - DOM states as nodes, user events as edges2 - and DORA extends it with MCTS instead of fixed depth-first/breadth-first, multi-agent parallelism, and persistent memory across sessions. Where Crawljax runs a single sweep and stops, DORA keeps learning. RPA tools like UiPath contributed a related idea: the centralized element repository, a shared Object Repository where all selectors live and get referenced by name. DORA's graph serves the same purpose, but where RPA flows are built manually, DORA discovers them autonomously.
LLM-based web agents tackle a different problem entirely. Agent Q, Mind2Web, ReAct, WebGPT - they navigate toward specific goals ("book a flight ticket"), and Agent Q combined MCTS with self-critique to push success rates from 18.6% to 81.7%20. But these agents are exploitative, optimizing for a single task. DORA is exhaustive - exploring everything reachable and outputting a knowledge repository rather than an answer.
Computer-use agents shipped in 2025 show how fast this space moves. OpenAI's CUA reaches 58.1% on WebArena and 87% on WebVoyager21, Google's Project Mariner scores 83.5% with parallel task execution22, and IBM's CUGA holds the single-agent WebArena record at 61.7%23. None build persistent knowledge, but their grounding capabilities - identifying elements from screenshots, filling forms, navigating multi-step flows - represent the atomic skills DORA's agents need.
LATS bridged MCTS and language agents, showing LLMs can serve as value functions with self-reflection12. Adapting tree search to language agents requires substantial novel design on nodes, prompts, and search algorithms - not a straightforward port. Explorer (ACL 2025) generated 94,000 successful web trajectories spanning 49,000 unique URLs at $0.28 per trajectory24, the kind of systematic trajectory generation DORA produces as a side effect.
What distinguishes DORA is knowledge retention. Testing tools log errors but don't build persistent models. Crawlers map pages; documentation isn't their job. LLM agents accomplish tasks but don't retain structured knowledge. DORA builds and maintains a persistent graph and documentation that survives long after the exploration run.
What's Hard
DORA works, but it doesn't solve everything.
State explosion is the most persistent challenge. Dynamic content - infinite scroll, WebSocket updates, time-specific data - produces an endless stream of "new" states that aren't meaningfully distinct.
Every additional axis compounds it. A multi-step form with five fields creates thousands of possible submission paths. Different user roles see different UI - an admin gets "Delete All Users" while a regular user doesn't. MCTS helps manage the explosion but doesn't eliminate it1. Synthetic test data, state-count limits, and action whitelists help, but covering every validation rule on a large platform remains impractical.
Identity is subtler. A label rename, a button moving to a different menu - is this a new state or a modified version of a known one? Too strict and the system creates duplicates. Too loose and it misses real changes.
Safety is a real concern when agents can click anything. An admin-credentialed agent that finds a "Delete All Users" button will, by default, want to click it - it's unexplored, high priority. Action whitelists and blacklists prevent catastrophic interactions, and running agents against a staging environment rather than production is strongly recommended. Even with safeguards, the agents need awareness of destructive actions: buttons labeled "Delete," "Remove," "Revoke," or "Reset" get flagged for cautious handling rather than eager exploration.
Context is the deepest limitation, and it's not one more code can solve. DORA can document that a two-factor authentication toggle exists on the Settings page, but it can't explain why a user would enable it or what the security implications are. Regulatory requirements, compliance context, security policies - none of that comes from clicking buttons.
Scale demands patience too. Large enterprise applications with hundreds of screens take hours or days to explore - rendering pages, waiting for DOM stability, processing screenshots - all orders of magnitude slower than traditional crawling. Coverage and structure are the system's strengths; contextual accuracy needs human input. Several of these limitations point directly to research directions.
What's Next
Hierarchical search tackles state explosion most directly - treating high-level site sections as sub-games. First decide which main menu section to explore, then run focused MCTS within that section. No more comparing actions across entirely different parts of the application.
Learned value functions could replace random rollouts entirely. A model trained on past exploration data predicts information gain per action, making simulations faster and more accurate. Empirical-MCTS demonstrated this in February 2026, transforming MCTS from a stateless inference technique into a continuous learning agent through a dual-loop framework25. DORA's graph memory already accumulates the training data these models need.
Documentation has room to grow too. An LLM reading the full knowledge base could normalize terminology, spot gaps between sections, and generate contextual explanations beyond what UI text provides26. Real-time dashboards visualizing graph growth - with alerts for broken links and coverage milestones - would turn DORA from a batch process into a continuous quality monitor.
Currently browser-only, the core algorithm transfers to mobile GUIs, desktop applications, and canvas elements. Only the automation layer changes. M2-Miner already demonstrated this for mobile - a multi-agent MCTS framework achieving a 64x efficiency boost over vanilla MCTS at task length 9, using an intent recycling strategy where discovered navigation patterns feed back into search27.
Human-in-the-loop feedback addresses the context gap most directly. CowPilot showed that human-agent collaboration achieves 95% success with humans performing only 15% of steps28. Agents explore, humans validate and guide - a division of labor that could close the remaining quality gap.
A broader trend supports all of this. Inference-time scaling, which started with reasoning models in 2024, applies directly to web exploration. Rather than training a specialized model, DORA uses MCTS to make existing models explore more intelligently at test time. As tree search techniques improve - AB-MCTS showed heterogeneous models cooperating via search outperform any single model29 - exploration gets better without retraining anything.
Footnotes
-
Stafeev et al., "SoK: State of the Krawlers - Evaluating the Effectiveness of Crawling Algorithms for Web Scanning," USENIX Security 2024 - 12 years of research, deterministic crawlers don't beat randomized ones. ↩ ↩2 ↩3
-
Mesbah et al., "Crawling AJAX by Inferring User Interface State Changes" - Crawljax state-flow graph approach and element signature deduplication. ↩ ↩2 ↩3
-
Hypermode, "How Knowledge Graphs Underpin AI Agent Applications" - Blackboard architecture and knowledge graph as communication medium. ↩
-
Salemi et al., "LLM-Based Multi-Agent Blackboard System for Information Discovery," October 2025 - 13-57% improvement in end-to-end task success using blackboard architecture for LLM multi-agent systems. ↩
-
Liu et al., "Can Cooperative Multi-Agent Reinforcement Learning Boost Automatic Web Testing?," ASE 2024 - MARG: 5 cooperative agents explore 36.42% more unique states than 5 independent agents. ↩
-
Kim et al., "Towards a Science of Scaling Agent Systems," December 2025 - 180 experiments: decentralized coordination outperforms centralized by 9.2% on web navigation tasks. ↩
-
Jiang et al., "MAGMA: A Multi-Graph based Agentic Memory Architecture," January 2026 - Orthogonal semantic, temporal, causal, and entity graphs with 45.5% higher reasoning accuracy and 95% token reduction. ↩
-
Microsoft Research, "OmniParser V2," February 2025 - Vision-based UI screen parsing at 0.6s/frame, enabling LLM agents to interact with any GUI from screenshots alone. ↩
-
Xu et al., "WebPilot: A Versatile and Autonomous Multi-Agent System for Web Task Execution" - LLM-guided MCTS for web navigation, 93% relative improvement over concurrent methods, published AAAI 2025. ↩
-
Gibberblot, "Reward Shaping - Mastering Reinforcement Learning" - Intermediate rewards without altering the ultimate goal. ↩
-
Mirsoleimani et al., "PPB-MCTS: Parallel Partial-Backpropagation Monte Carlo Tree Search" - Shared transposition tables, partial backpropagation for distributed MCTS. ↩ ↩2
-
Zhou et al., "Language Agent Tree Search Unifies Reasoning, Acting, and Planning," ICML 2024 - LATS: LLMs as value functions with self-reflection for MCTS-guided exploration. ↩ ↩2
-
Antoniades et al., "SWE-Search: Enhancing Software Agents with Monte Carlo Tree Search and Hindsight Feedback," ICLR 2025 - Hybrid value function combining numeric and qualitative LLM feedback, 23% improvement on SWE-bench. ↩
-
Gao et al., "WebWorld: A Large-Scale World Model for Web Agent Training," February 2026 - First open-web simulator trained on 1M+ interactions, outperforms GPT-5 as world model, +9.2% on WebArena. ↩
-
"MC-DML: Monte Carlo Planning with Dynamic Memory-Guided LLM," ICLR 2025 - Combines MCTS with in-trial and cross-trial memory for dynamic value estimation without iterative training. ↩
-
Zirak and Brecht, "Representing Web Applications As Knowledge Graphs" - Reward/penalty model, state deduplication, element-level graph representation. ↩
-
Manku et al., SimHash for near-duplicate detection. See also Algonotes documentation and practical application at fromkk. ↩
-
"Judge: Effective State Abstraction for Guiding Automated Web GUI Testing," ACM TOSEM 2025 - DOM tree merge-and-classify with contrastive learning for state deduplication. ↩
-
Pan et al., "ExACT: Teaching AI Agents to Explore with Reflective-MCTS and Exploratory Learning," ICLR 2025 - Contrastive reflection: learning from past execution feedback to steer future decisions. ↩
-
MultiOn, "Introducing Agent Q" - MCTS + self-critique improved Llama-3's web task success rate from 18.6% to 81.7%. ↩
-
OpenAI, "Computer-Using Agent," January 2025 - 58.1% WebArena, 87% WebVoyager, 38.1% OSWorld via vision-based screenshot interaction. ↩
-
Google DeepMind, "Project Mariner," 2025 - 83.5% WebVoyager, parallel task execution on cloud VMs, teach-and-repeat capability. ↩
-
IBM Research, "CUGA: Computer Using Generalist Agent," March 2025 - 61.7% WebArena (single-agent SOTA), hierarchical planner-executor with persistent task ledger. ↩
-
Zhang et al., "Explorer: Scaling Exploration-driven Web Trajectory Synthesis," ACL 2025 - Multi-agent pipeline generating 94K web trajectories spanning 49K URLs at $0.28 per trajectory. ↩
-
Empirical-MCTS, "Empirical Monte Carlo Tree Search," February 2026 - Transforms MCTS from stateless inference into continuous learning through a dual-loop framework with memory optimization. ↩
-
Ronanki et al., "Free and Customizable Code Documentation with LLMs" - LLM-driven documentation generation from structured source material. ↩
-
"M2-Miner: Multi-Agent Enhanced MCTS for Mobile GUI Agent Data Mining," February 2026 - 64x efficiency boost over vanilla MCTS with intent recycling strategy for mobile GUI exploration. ↩
-
CowPilot, "A Human-Agent Collaborative Web Navigation Framework," NAACL 2025 - 95% success rate with humans performing only 15.2% of total steps. ↩
-
Sakana AI, "AB-MCTS: Adaptive Branching Monte Carlo Tree Search," 2025 - Heterogeneous models cooperating via tree search achieve over 30% on ARC-AGI-2, up from 23% with single-model sampling. ↩