GraphRAG (Graphs + Retrieval Augmented Generation) is a technique for richly understanding text datasets by combining text extraction, network analysis, and LLM prompting and summarization into a single end-to-end system.
Motivation: the Limitations of Vector Similarity Search
The idea behind the retrieval-augmented (RAG) approach is to reference external data at question time and feed it to an LLM to enhance its ability to generate accurate and relevant answers. It is pretty much ubiquitous right now to imply vector similarity search as the method used to naively identify which chunks of text might contain relevant data to answer the user’s question accurately.
This approach works fairly well when vector search can produce relevant chunks of text. However, there are many scenarios when it cannot. Simple vector similarity search isn't sufficient when we need:
-
Multi-hop question answering: RAG falls apart when the LLM needs information from multiple documents or even just multiple chunks to generate an answer.
- This happens when answering a question requires traversing disparate pieces of information through their shared attributes to provide new synthesized insights.
- For example, consider: "Describe what the CEOs of the top 3 AI companies like to eat for lunch."
- The question needs breaking down into sub-questions: "Who are the CEOs of the top 3 AI companies?" and "What does each CEO like to eat for lunch?"
- Simply chunking and embedding documents in a database, then using plain vector similarity search won't yield relevant information to answer the question.
-
Unknown answer scenarios: We're dealing with questions where we may not know the answer. Naively embedding the question doesn't ensure that the vector lands in the same space as the answer.
- For example, in a long VC deal document, one single word "Pre-" or "Post-" money changes the entire deal structure. Simply embedding "What is the deal about" won't land us near the information, unless someone has explicitly written what the deal is about in the dataset.
- There are workarounds like the HyDE approach that creates a "Hypothetical" answer with LLM help, then searches embeddings for a match.
-
Global corpus questions: RAG fails on questions directed at an entire text corpus, such as "What are the main themes in the dataset?"
- It struggles to holistically understand summarized semantic concepts over large data collections or singular large documents.
- This is inherently a query-focused summarization (QFS) task, rather than an explicit retrieval task.
- Questions like "What are the top 5 themes in the data?" perform terribly because baseline RAG relies on vector search of semantically similar text content. There's nothing in the query to direct it to the correct information.
- GraphRAG performs much better because we can use semantic and thematic agglomerative approaches built on graph machine learning.
-
Cosine similarity limitations: Analytical derivations show how cosine-similarity can yield arbitrary and meaningless 'similarities'1, with researchers cautioning against blindly using cosine-similarity.
These shortcomings with vector similarity for RAG have garnered significant attention recently, including on X. This is where GraphRAG comes in.
Combining Graphs with RAG
Graphs are everywhere; real-world objects are often defined by their connections to other things. A set of objects and their connections are naturally expressed as a graph. The information extraction pipeline - the process of extracting structured information as entities and relationships from unstructured text - was a key bottleneck for using knowledge graphs with LLMs. Knowledge graph construction has traditionally been complex and resource-intensive2, limiting adoption. GraphRAG simplifies this process.
The beauty is that we can process each document individually, and information from different records gets connected when the knowledge graph is constructed or enriched. We're pre-processing data before ingestion, instead of performing operations at query-time, like the contextual summarization techniques people usually use to get around this.
Having access to structured information allows LLM applications to perform various analytics workflows where aggregation, filtering, or sorting is required. For example:
- "Who are the top 5 companies in the AI space by Valuation?"
- "Which CEO has previously founded the most companies?"
Plain vector similarity search struggles with analytical questions since it searches through unstructured text data, making it difficult to sort or aggregate information.
As I mentioned in the topic modelling post, there are entire toolkits available for graph-represented data. Being able to express data that intuitively can be represented as a graph opens up many possibilities. Researchers have developed graph neural networks (GNNs) that operate on graph data for over a decade, with recent developments increasing their capabilities and expressive power. We're seeing practical applications in antibacterial discovery3, physics simulations4, fake news detection5, traffic prediction6, and recommendation systems7.
For this post's purposes, let's focus on retrieval. The information extraction pipeline can be performed using LLMs or custom text domain models. Then, instead of vector similarity as normally done in RAG, we can retrieve relevant information from a knowledge graph.
GraphRAG
The method I'll follow here is heavily inspired by Microsoft's GraphRAG approach8, which uses an LLM to build a graph-based text index in two stages:
- Derive an entity knowledge graph from the source documents
- Pre-generate community summaries for all groups of closely-related entities
This methodology focuses on graphs' inherent modularity and community detection algorithms' ability to partition graphs into modular communities of closely-related nodes. LLM-generated summaries of these community descriptions provide complete coverage of the underlying graph index and the input documents it represents. Query-focused summarization of an entire corpus becomes possible using a map-reduce approach: first using each community summary to answer the query independently and in parallel, then summarizing all relevant partial answers into a final global answer.
The Information Extraction Pipeline
-
Source Documents → Text Chunks
- Split input texts from source documents into text chunks for processing
- Use LLM prompts to extract elements of a graph index from each chunk
- Balance chunk size to optimize the number of LLM calls and recall of entity references
-
Text Chunks → Element Instances
- Identify and extract instances of graph nodes and edges from text chunks using multipart LLM prompts
- Include entities' names, types, descriptions, and relationships in the extraction
- Tailor prompts to specific domains with few-shot examples
- Perform multiple rounds of gleanings to detect additional entities and ensure extraction quality
-
Element Instances → Element Summaries
- Use LLMs to create descriptions of entities, relationships, and claims, performing abstractive summarization
- Convert instance-level summaries into single blocks of descriptive text for each graph element
- Address potential inconsistencies in entity extraction to avoid duplicates and ensure connectedness in the graph
-
Element Summaries → Graph Communities
- Model the index as a homogeneous undirected weighted graph with nodes and relationship edges
- Edge weights represent the normalized counts of detected relationship instances
- Use community detection algorithms, like Leiden, to partition the graph into hierarchical communities
- Create hierarchical community structures for efficient global summarization
-
Graph Communities → Community Summaries
- Generate report-like summaries for each community in the Leiden hierarchy
- Prioritize and add element summaries to the LLM context window until the token limit is reached
- Priority ("overall prominence") follows decreasing order of combined source and target node degree
- Summarize higher-level communities by ranking and substituting sub-community summaries if needed
- These summaries help you understand the overall structure and meaning of the dataset, even without specific questions
-
Community Summaries → Community Answers → Global Answer
- Randomly shuffle and divide community summaries into chunks
- Generate intermediate answers for each chunk in parallel
- Filter out unhelpful answers and sort the rest by helpfulness score
- Iteratively add the most helpful intermediate answers into the context window to generate the final global answer
GraphRAG connects information across large volumes of data and uses these connections to answer questions that are difficult or impossible to answer using keyword and vector-based search mechanisms.
Exploring the Graph
I've indexed a subset of the dataset I scraped for Dcypher AI, which contains news updates related to the AI space. The graph we're able to generate looks like this:
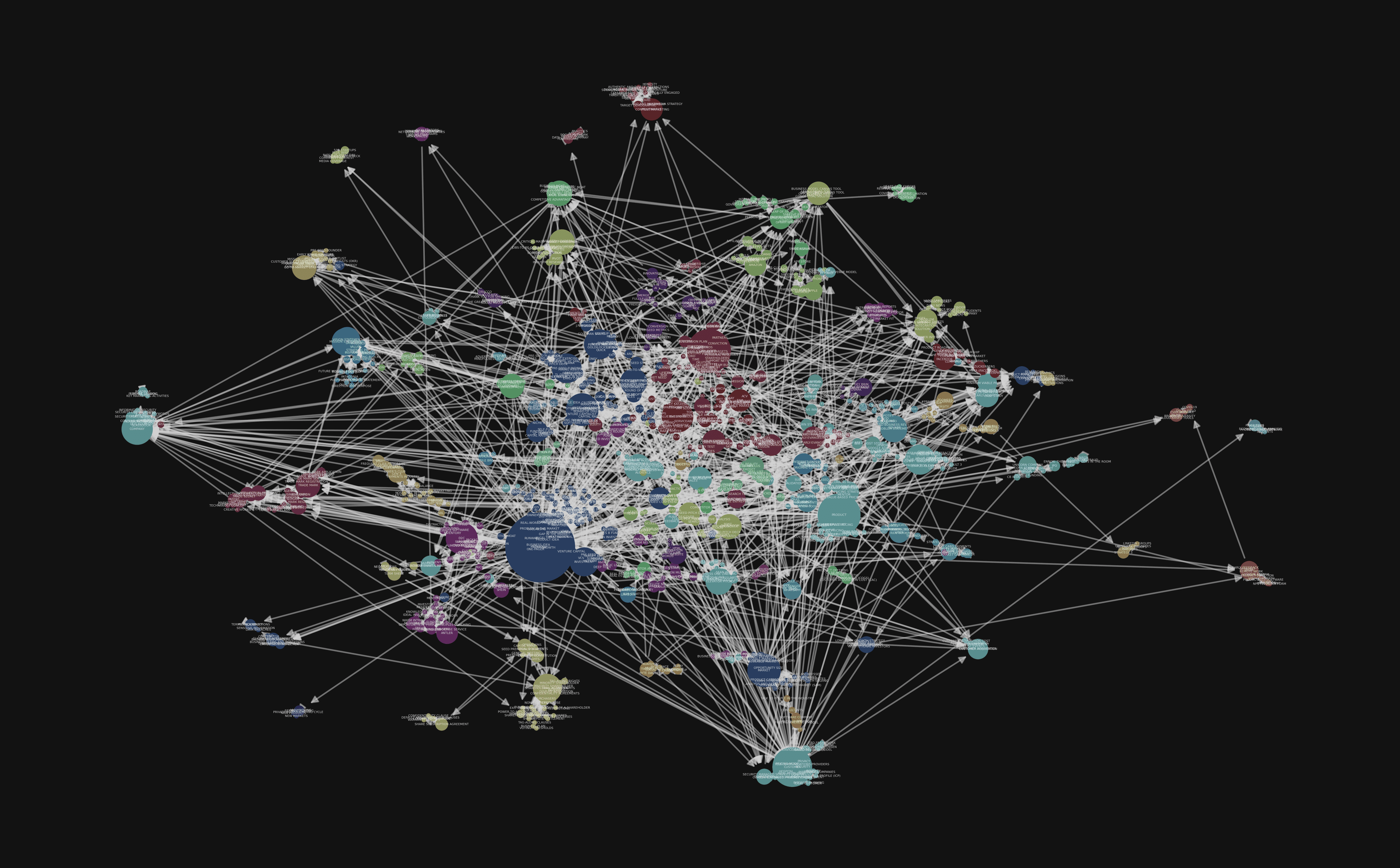
We can also use a UMAP technique, similar to the approach I used in the topic modelling post, to visualize the graph in 2D space. This provides a great sense of the graph's structure, with semantically similar nodes grouped and clustered near each other.
Querying the graph with questions like "What are the top 5 companies in the AI space?" returns detailed, structured answers. This is a simple example, but the graph can handle much more complex queries.
#### 1. OpenAI
OpenAI is a leading artificial intelligence research and deployment company based in San Francisco. It is renowned for creating the AI-powered chatbot platform ChatGPT and is acti
vely targeting the emerging market of text-to-video software. OpenAI has released advanced models like GPT-4O-2024-08-06 and is currently testing SearchGPT, positioning itself as a leader in AI innovation [Data: Reports (11, 4, 13)].
#### 2. Microsoft
Microsoft has made a significant investment in artificial intelligence through its multi-billion dollar partnership with OpenAI. This collaboration aims to enhance Microsoft's AI capabilities and maintain its competitive edge in the tech industry. The partnership underscores Microsoft's commitment to advancing AI technology [Data: Reports (17, 11)].
#### 3. NVIDIA
NVIDIA is well-known for its graphics processing units (GPUs) and contributions to artificial intelligence research. The company has developed NVIDIA Edify, a multimodal architecture for visual generative AI, which highlights its significant role in the AI and GPU markets [Data: Reports (17)].
#### 4. Google
Google continues to be a major player in the tech industry with its innovative advancements in AI technology. The company has developed a series of Gemma models, including Gemma 2, Gemma 2 2B, Gemma Scope, and ShieldGemma, showcasing its commitment to AI research and development [Data: Reports (18)].
#### 5. ByteDance
ByteDance, a prominent Chinese tech firm, has made strides in the AI space by expanding its text-to-video software, Jimeng AI, to the Apple App Store for Chinese users. This move signifies ByteDance's intent to capture a larger share of the emerging text-to-video market [Data: Reports (0)].GraphRAG handles more complex queries, such as "Which CEO has been the most controversial in the AI space?" Here's an example response:
Both Sam Altman and Elon Musk have been highly controversial figures in the AI space, each playing significant roles in the ongoing legal and operational challenges facing OpenAI. Altman's leadership and the internal power conflicts within OpenAI have drawn considerable scrutiny, while Musk's legal actions against the organization have further fueled the controversy. These events highlight the complex and often contentious nature of leadership in the rapidly evolving field of artificial intelligence.
This represents a considerable improvement over baseline RAG outputs.
Use Cases
GraphRAG opens up a wide range of applications, especially in handling unstructured data. Its ability to draw connections between concepts and generate multilevel Leiden summaries makes it versatile across various fields:
- Graph Machine Learning: Provides the ability to analyze information using graph-based machine learning techniques
- Unstructured Data Analysis: Apply GraphRAG to podcast transcripts for deep insights from lengthy conversations, or make sense of narrative-driven datasets like laws, policies, and stories
- Multilevel Summaries: The multilevel Leiden summaries allow users to get different levels of data summaries, offering powerful tools for understanding and organizing information at various depths
- Fighting Disinformation: Structure knowledge from hundreds of interview transcripts involving experts discussing current events, making it easier to identify and counter false information
- Fraud Detection: Insurance companies can detect fraudulent activities by analyzing complex data relationships and patterns that traditional methods might miss
- Financial Analysis: Provide competitive intelligence on new technologies for financial statement trend analysis, helping businesses stay ahead
- Agentic Workflows: Create knowledge graphs with network-based recall to help agents remember the current state of important entities and their relationships
- LLM-Driven Ontology: An LLM-driven ontology with a QA triple store can facilitate CRUD operations for self-improvement, enabling systems to continuously evolve
- Decentralized Fact-Checking: A decentralized fact-checker powered by GraphRAG could transform how we verify information across various sources
- Codebase Analysis: Developers can create graphs of codebases, allowing LLMs to understand how different components interact with each other
- Research and Theory Formation: Research scientists can use GraphRAG to form new theories and narrow down their search space, accelerating scientific discoveries
GraphRAG's ability to understand and summarize complex relationships within vast amounts of data makes it valuable across multiple industries and applications.
Drawbacks and Improvements
The main drawback here is that it is computationally heavy to index the data. Multiple prompts are needed to extract entities and relationships from the text, and with multiple gleanings, this can easily get out of hand. This can be time-consuming and resource-intensive, especially for large datasets. Even when the graph is constructed, querying it is relatively more expensive, with more LLM calls being made (10x more) and an order of magnitude more tokens of context on average. These seem to be the cost for a much richer and correct answer.
There are alternatives that I want to investigate though, namely SciPhi/Triplex. This is an open source model that is fine tuned version of Phi3-3.8B for converting unstructured text into "semantic triples" (subject, predicate, object) reducing the generation cost of knowledge graphs tenfold.
SciPhi is the company that built R2R and Triplex, and they have prebuilt solutions for automatic knowledge graph construction during input file ingestion which are the next candidates for exploration on this topic.
Resources
- GraphRAG Github
- GraphRAG Blog Post
- GraphRAG Docs
- GraphRAG Paper
- Project GraphRAG
- GPT Researcher
- Plan-and-Solve
- RAG
- Knowledge Graphs are key to unlocking the power of AI
- How to Build Knowledge Graphs With LLMs (python tutorial)
- Exploring Large Language Models for Knowledge Graph Completion
- 4 Ways Unstructured Data Management Will Change in 2024
- Expert Reveals Key Data Management Trends for 2024 to Know
- Harnessing LLMs With Neo4j
- Fine-Tuning vs Retrieval-Augmented Generation
- Knowledge Graphs & LLMs: Multi-Hop Question Answering
- Knowledge Graphs & LLMs: Real-Time Graph Analytics
- Construct Knowledge Graphs From Unstructured Text
- Project NaLLM
- Constructing knowledge graphs from text using OpenAI functions
- LangChain Cypher Search: Tips & Tricks
- Extract knowledge from text: End-to-end information extraction pipeline with spaCy and Neo4j
- Text to Knowledge Graph Made Easy with Graph Maker
- How to Convert Any Text Into a Graph of Concepts
- Accelerating Scientific Discovery with Generative Knowledge Extraction, Graph-Based Representation, and Multimodal Intelligent Graph Reasoning
- GraphRAG: LLM-Derived Knowledge Graphs for RAG
- GraphRAG Ollama: 100% Local Setup, Keeping your Data Private
- Easy GraphRAG with Neo4j Visualisation Locally
- Sciphi Triplex
- R2R Knowledge Graphs
- GraphRAG: LLM-Derived Knowledge Graphs for RAG
Footnotes
-
Harald Steck, Chaitanya Ekanadham, Nathan Kallus: “Is Cosine-Similarity of Embeddings Really About Similarity?”, 2024, ACM Web Conference 2024 (WWW 2024 Companion) ↩
-
Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apurva Mody, Steven Truitt, Jonathan Larson: “From Local to Global: A Graph RAG Approach to Query-Focused Summarization”, 2024 ↩
-
Jonathan M. Stokes, Kevin Yang, Kyle Swanson, Wengong Jin, Andres Cubillos-Ruiz, Nina M. Donghia, Craig R. MacNair, Shawn French, Lindsey A. Carfrae, Zohar Bloom-Ackermann, Victoria M. Tran, Anush Chiappino-Pepe, Ahmed H. Badran, Ian W. Andrews, Emma J. Chory, George M. Church, Eric D. Brown, Tommi S. Jaakkola, Regina Barzilay, James J. Collins: "A Deep Learning Approach to Antibiotic Discovery", Cell, Volume 180, Issue 4, 2020, Pages 688-702.e13 ↩
-
Alvaro Sanchez-Gonzalez, Jonathan Godwin, Tobias Pfaff, Rex Ying, Jure Leskovec, Peter W. Battaglia: “Learning to Simulate Complex Physics with Graph Networks”, 2020 ↩
-
Federico Monti, Fabrizio Frasca, Davide Eynard, Damon Mannion, Michael M. Bronstein: “Fake News Detection on Social Media using Geometric Deep Learning”, 2019 ↩
-
Oliver Lange, Luis Perez: "Traffic prediction with advanced Graph Neural Networks", 2020 ↩
-
Chantat Eksombatchai, Pranav Jindal, Jerry Zitao Liu, Yuchen Liu, Rahul Sharma, Charles Sugnet, Mark Ulrich, Jure Leskovec: “Pixie: A System for Recommending 3+ Billion Items to 200+ Million Users in Real-Time”, 2017 ↩
-
Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apurva Mody, Steven Truitt, Jonathan Larson: “From Local to Global: A Graph RAG Approach to Query-Focused Summarization”, 2024 ↩