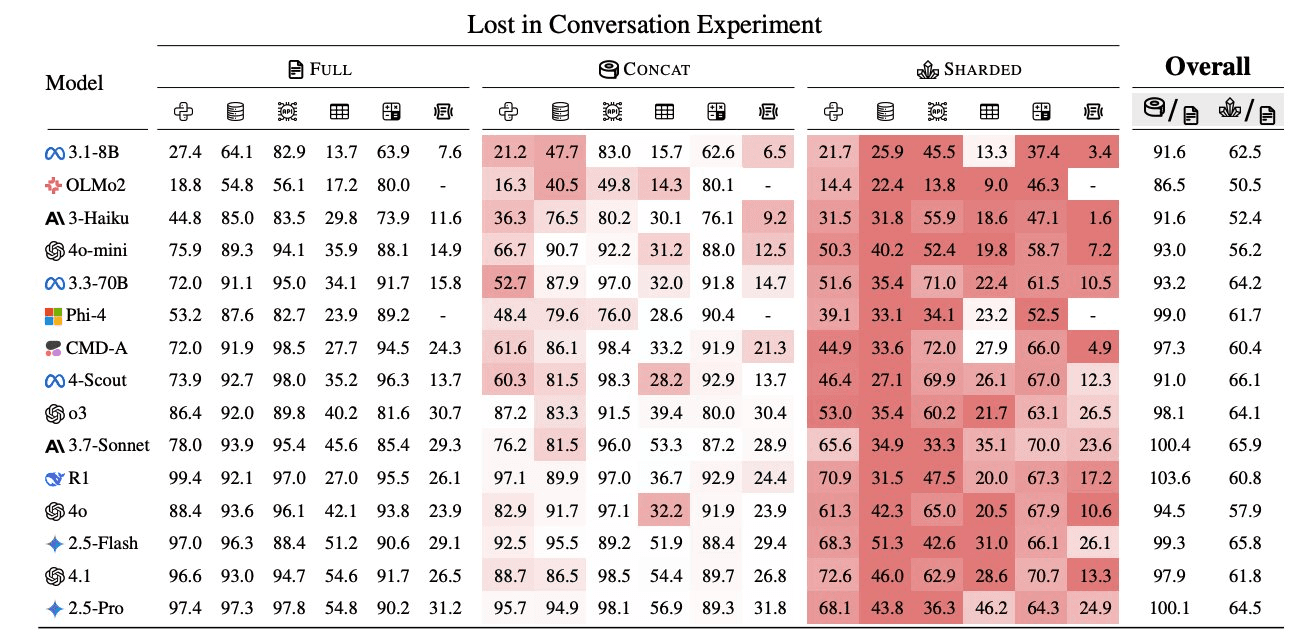
Every major LLM loses 39% of its performance the moment you start having a conversation with it instead of giving it one clean prompt. A 2025 study tested 15 models across 200,000 conversations. Not one was immune1.
That number should make you uncomfortable if you're building agents. Agents are nothing but multi-turn conversation with tools. If the underlying model degrades with every exchange, what does that mean for a system that might chain dozens of exchanges before producing a result?
Every pattern that follows is, in some form, a way to fight that degradation - constraining the agent, stabilising its state, closing the loop with external signals. I'm using LangGraph examples in places, but the concepts apply regardless of framework.
Agents and Workflows
Before getting into patterns, a quick distinction. An AI agent is an LLM given some form of agency to decide on and execute actions toward a goal - calling tools in a loop, adjusting its plan based on intermediate results, rather than just answering a single prompt. In this post I'll use "agentic system" to cover both structured workflows and dynamic agents. Anthropic draws a useful line between the two2:
On one side, workflows - LLMs orchestrated through predefined code where you decide the steps ahead of time. A RAG pipeline that always does "search then answer" is a workflow. On the other, agents - LLMs that dynamically control their own tool usage, deciding what to do next. An autonomous coding assistant that chooses when to search, when to write code, and when to ask for clarification is an agent. Even a retrieval-augmented QA bot that decides which documents to fetch before answering has a degree of agency - the LLM controls the retrieval step.
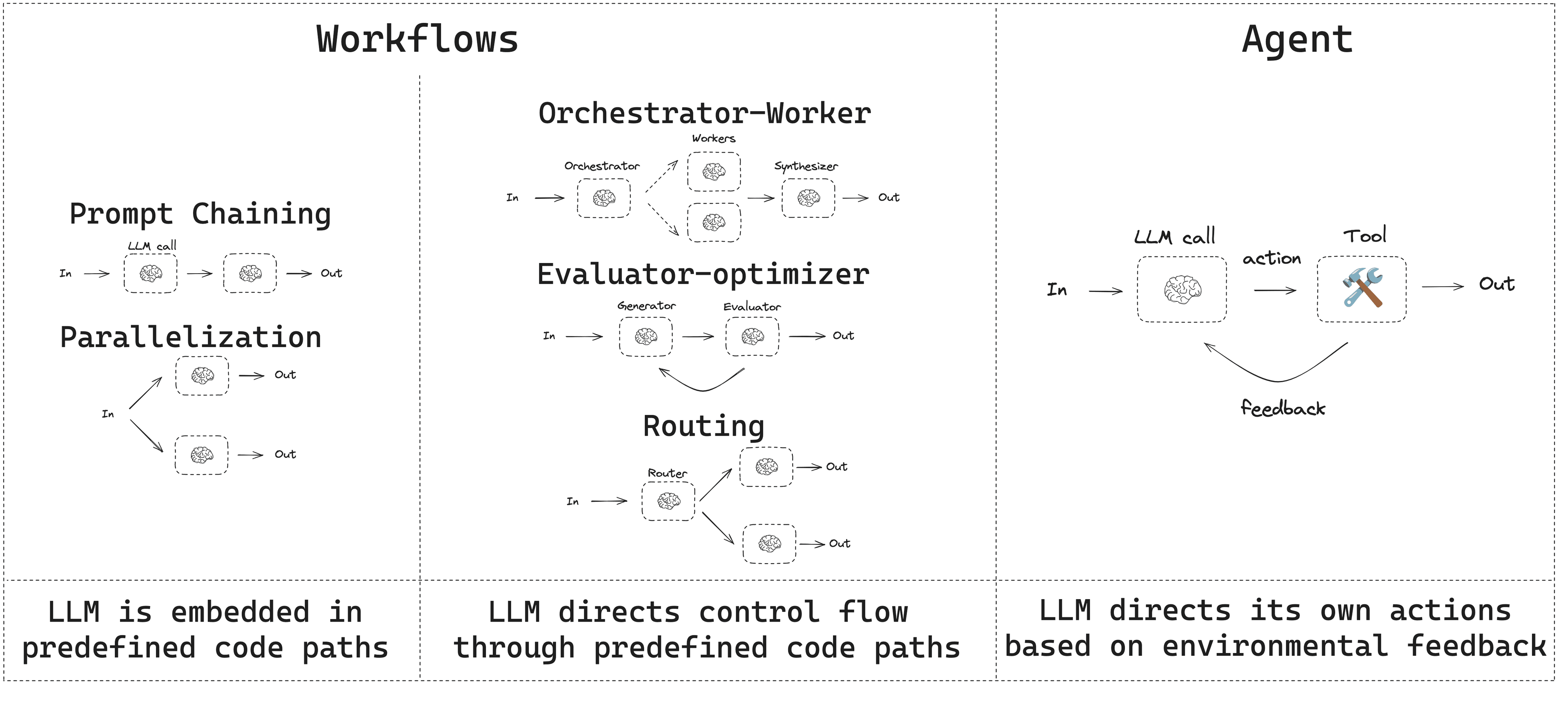
In practice there's a spectrum. Most production systems blur the line - giving the LLM some freedom within a constrained structure. An OpenAI engineer put it well3:
Single big LLM calls work best when the task's pieces are tightly coupled (interrelated info or steps), or you need immediate output without waiting on intermediate steps. Multiple smaller calls work better when the task can be cleanly decomposed into independent parts, or when you want branching logic (e.g. a decision tree of subtasks), or want certain processing done with guaranteed rules outside the LLM.
The monolithic-vs-multi-agent question comes down to context. A sufficiently large model with infinite context would be ideal, since dividing context throws away useful information4. In practice, limited context windows, cost, and the desire for modularity push toward splitting - but only when the pieces are truly independent. If a single model could solve it given all information, it usually should.
Anthropic's advice is worth taking seriously: if a task can be solved with a simple prompt or a straightforward script, that's more reliable than a complex agent. Only add agentic complexity when the problem genuinely requires it - typically open-ended problems where you can't predict the steps in advance2.
Why Agents Break
The multi-turn degradation I opened with is the foundation of why agents break. Models jump to conclusions before getting all the details, then get stuck defending wrong assumptions, and responses bloat by 20–300% with those assumptions piling up. Like humans, LLMs fixate on the beginning and end of conversations, missing crucial details shared in the middle - and the more verbose the AI gets, the more it confuses itself in subsequent turns, lost in its own words. Early mistakes compound as the conversation continues, with the model doubling down instead of course-correcting1.
Lower temperature doesn't help. Even advanced reasoning models suffer. Periodic recap strategies - repeating all previous instructions - recover only 15–20% of the lost performance1. Making AI interactions "natural" through conversation might actually make them less reliable. Sometimes the best UX isn't the most human-like one.
Then there's reliability at the system level. Stringing multiple steps together compounds the error rate. The Air Canada chatbot told a grieving customer he could book a full-price ticket and apply for a bereavement discount afterward - the actual policy said no retroactive discounts. In the subsequent lawsuit, Air Canada tried to argue the chatbot was "a separate legal entity." The tribunal ruled the company bore full responsibility for all information on its website, "whether it came from a static page or a chatbot"5.
Speed and cost compound the problem. Multi-agent runs can use 15x more tokens than single-agent chats6. Though the trend is favorable - GPT-4o pricing dropped from ~$36 to ~$4 per million tokens in 17 months, roughly 80% cost reduction per year7 - cost still gates what's practical.
And complexity itself is a failure mode. More moving parts means more surface area for bugs. Debugging a misbehaving agent - figuring out which prompt or tool caused an issue - requires the kind of logging and introspection tools that most teams don't have when they start building.
The pattern that runs through all these failures: the most reliable agents look more like state machines than autonomous reasoners. A few guiding principles follow from this.
- Prefer structured flows over autonomous loops. Deterministic or constrained flows with AI inside - think fancy API endpoints rather than open-ended agents - are more reliable than letting a model run wild.
- Get it working before optimising. Model API prices are dropping fast enough that premature cost optimisation is usually wasted effort7. An overly frugal design that fails to meet user needs is worse than a costly one that does. Ship the slow version, measure, then optimise.
- Keep tasks narrow and well-defined. Today's agents perform best on bounded domains with clear success criteria - coding assistants, customer support for a specific product, document extraction. "Jack of all trades" agents tend to be brittle.
- Stay flexible with tools and models. The landscape evolves quickly. Use abstractions that let you swap out the model, vector store, or API without rewriting the app. Don't tie yourself to one provider's quirks.
Memory Patterns
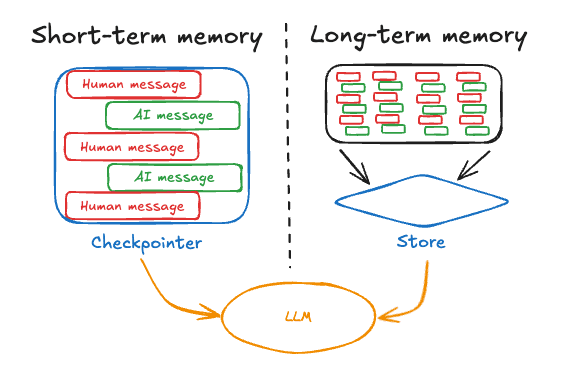
Memory is how agents fight the 39% degradation problem. Without it, every turn of conversation is the model working with less context, not more.
The architecture maps to how human memory works89. What fits in the current context window - recent conversation history, the current task state - is short-term memory, limited by the model's context length. Anything that needs to persist across sessions lives in an external store: a vector database, knowledge graph, or key-value store that the agent queries when relevant. And then there's the raw input layer - images, audio, recent observations encoded into embeddings for quick processing - roughly analogous to sensory memory.
The practical challenge is managing that short-term context as it grows. Naively appending the entire chat history eventually hits context limits. You need strategies: message filtering to drop irrelevant turns, trimming to summarize oldest turns when context fills up, or dynamic conversation summarization where the agent carries a compressed summary plus recent turns8. The schema-based approach is worth trying - instruct the model: "Before answering, recall if the user provided any preference earlier (yes/no) and what it was." Forcing a self-query of memory surfaces facts that would otherwise be buried in dialogue history.
For long-term storage, semantic search over a vector database is the most common approach. An agent might have a vector DB of company policies to consult when answering HR questions. Multi-vector indexing - storing both exact text and high-level summary vectors for the same content - improves recall by letting the agent match on different aspects of the data9. MemInsight (2025) took this further with an autonomous memory module that periodically summarizes new information and stores it, improving personalization on long-running tasks10.
Agents can also explicitly save what they learn. After a conversation, the agent might extract key facts about user preferences and call a SaveMemory tool to store them. Next time, it retrieves those facts to personalize responses. This is memory-conditioned behavior - the agent adapts its style based on what it remembers.
Stanford's Generative Agents research demonstrated something more ambitious: simulated characters that maintained both episodic memory (specific events they experienced) and semantic memory (general knowledge they accumulated), using those memories to guide future behavior11.
What to actually store depends on the application. Some agents store user preferences as semantic memory. Others store entire episodes of successful outcomes - "when the user asked X, the flow that worked was Y" - as episodic memory. Some even update their own instructions or prompts over time, treating those updates as procedural memory. The CoALA paper (2024) provides a formal framework mapping these human memory types to agent architectures, and many modern agents experiment with some combination of the three.
When to Update Memory
One nuance that matters in production is when the agent updates its long-term memory712:
The hot-path approach updates memory during the conversation flow - the agent calls a SaveMemory tool as one of its steps before responding. Memory stays immediately up-to-date, but you pay in latency and complexity. The agent is multitasking between solving the user's request and managing its own state.
The alternative is background updates: respond first, then have a separate process summarize the exchange and store key facts after the turn completes. If a new message arrives before the background update runs, the system cancels the pending update and schedules a new one after the latest turn. The user experience stays snappy, but memory lags slightly behind.
The tradeoff is sharp. Hot-path updates give you immediate consistency and let the agent consciously decide what to remember, which is good for fine control - but they add latency and intermingle memory logic with task logic. Background updates keep the UX snappy and decouple memory management, at the cost of memory lagging slightly behind reality and needing extra logic to trigger the job at the right time.
Most production systems default to background updates for things like conversation summarisation. Over time the agent builds a long-term profile without ever pausing the live conversation. Some systems combine both - detailed logs short-term, distilled facts long-term - effectively giving the agent working memory and archival memory at different granularities13.
Checkpointing State
State persistence is what lets agents survive crashes and enable debugging. If your agent is deployed as a service and the process restarts, you need the session state - conversation memory, variables, intermediate results - to survive.
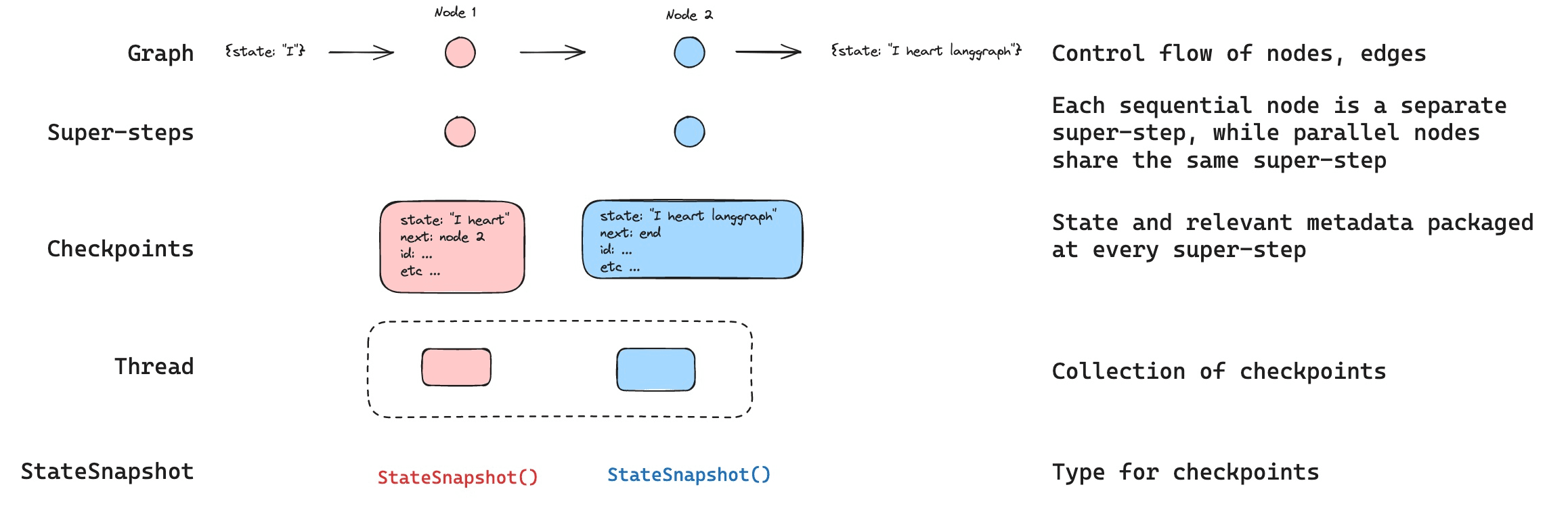
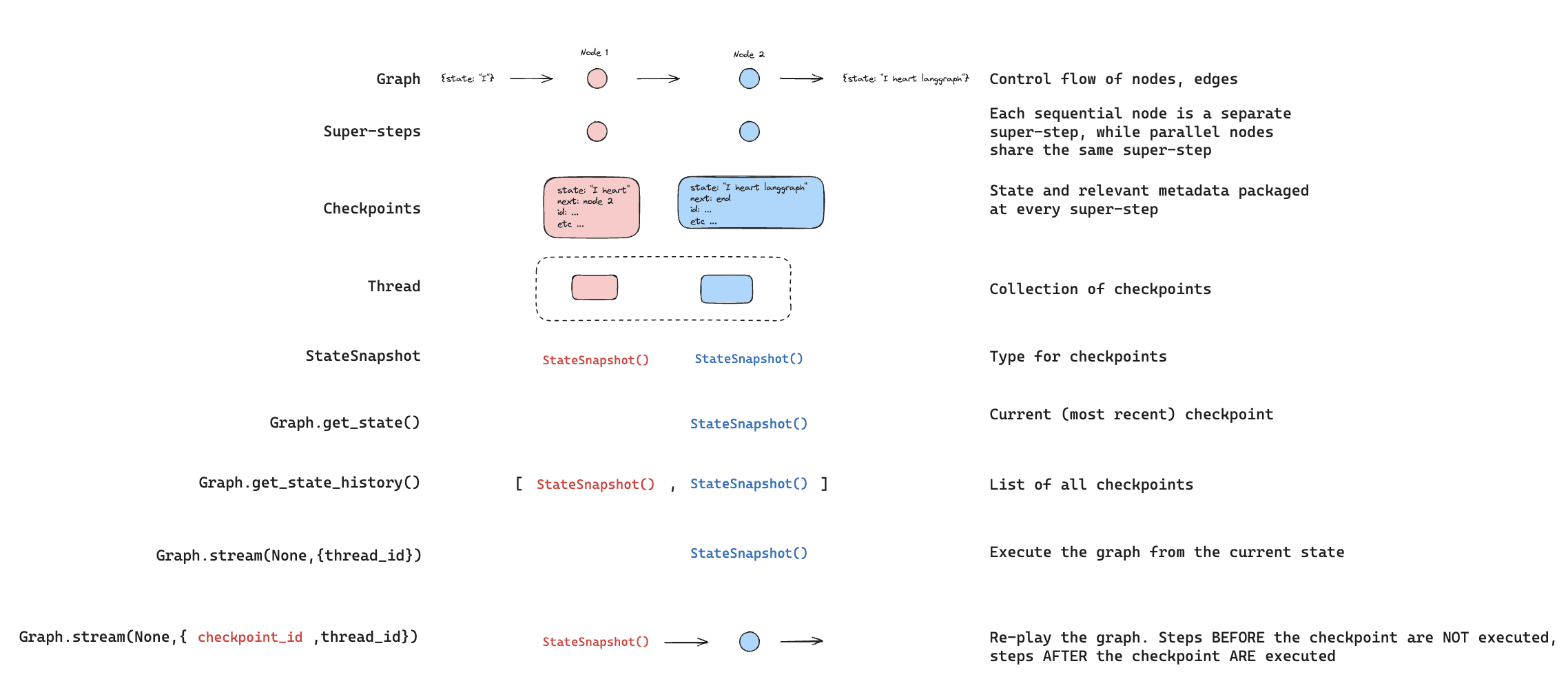
LangGraph's checkpoint system saves state after each agent action. This enables what they call "time travel" - replaying a past state deterministically or forking from a past state by altering something and continuing differently14. If an agent made a wrong decision at step 5 of a 10-step chain, you can roll back to step 4, adjust the prompt, and let it proceed differently. It's version control for agent reasoning.
Checkpoints also give you fault tolerance (restart from the last good state when an external API fails) and support for human-in-the-loop scenarios where you pause the agent, get input, and resume later with full state intact.
Cross-thread persistence takes this further - sharing data across different sessions or agents through a common memory store12. An agent can write to a knowledge base that outlives one conversation and is accessible to others. Useful for multi-user systems or global facts storage.
Imagine a coding agent that hits a compilation error on its first attempt. With checkpointing and time travel, a developer can rewind to the code generation step, tweak the prompt or give a hint, and let the agent proceed differently - diagnosing the failure without restarting the whole process14. This controlled replay makes debugging dramatically easier and improves reliability over time.
The challenge is deciding what to checkpoint and store. Everything verbatim is infeasible. High-level summaries only might omit crucial specifics. The field is still experimenting with the right granularity.
Memory and persistence fight the degradation problem, but they don't eliminate it. A few practical rules fall out of the Laban et al. study that every production team rediscovers1:
- Encourage complete upfront instructions. Nudge users to specify all requirements in one consolidated prompt rather than dribbling them out over multiple messages. A well-specified single turn beats a ten-turn negotiation every time.
- Reset when things go sideways. If a conversation starts going off-track, it's often better to start fresh with a summary of what the user actually wants than to keep patching a derailed thread.
- Use recap strategically, not reflexively. Periodically restating accumulated requirements recovers some ground. Even better, give the model an explicit schema for memory retrieval: "Before answering, recall if the user provided any preference earlier (yes/no) and what it was."
- Keep humans in the loop for anything high-stakes. Given unreliability in multi-turn settings, human review matters more, not less, for anything consequential.
- Design escape hatches. Detect when conversations are failing and either reset the context or escalate. The model won't notice it's stuck; the system has to.
Sometimes the best UX plays to the model's strengths rather than mimicking human conversation.
Control Flow
Memory handles what the agent remembers. Control flow handles how it moves through its reasoning. These patterns constrain the agent's decision-making path - preventing it from wandering when structure would serve better.
Prompt Chaining
The simplest multi-step pattern: break a task into a fixed sequence of LLM steps, each feeding its output to the next. No branching, no agent autonomy - just a pipeline.
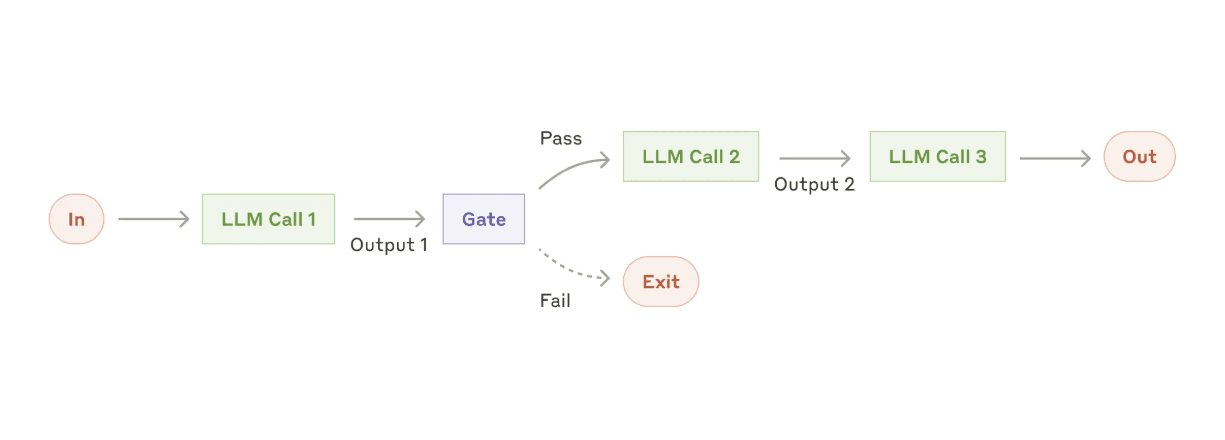
Write an outline for an essay, then expand each section. Generate a draft response to a customer email, then evaluate whether it adheres to company policy. Parse a user request, plan API calls, execute them, format results. These are all prompt chains - the sequence is predetermined, you sacrifice speed for accuracy by focusing the model on one sub-problem at a time2.
Adding gating functions between steps makes chains more robust - a small piece of code that checks the output (length, JSON validity, presence of required keywords) before passing it along. If the check fails, retry or ask the model to fix the format. This keeps the chain on track without needing the model to self-monitor.
Routing
Routing uses the LLM (or a classifier) to pick one of several handling paths for an input. Think of it as a switch statement where the LLM decides which case to execute.
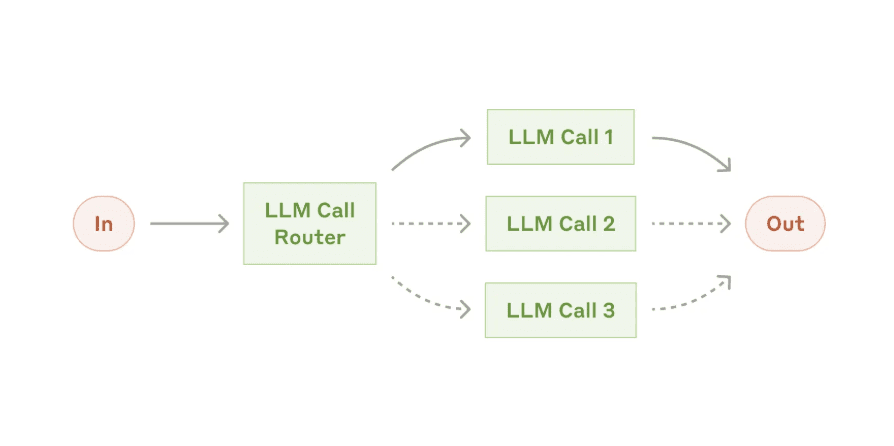
An AI assistant that handles both chit-chat and technical support might first classify the query - casual conversation, support issue, billing question - then route to a specialized prompt optimized for that category. A system might route simple questions to a cheap small model and complex ones to a more powerful model. A knowledge base system might route to a RAG pipeline when confidence is high and to generative answering when the KB lacks coverage2.
The key is ensuring structured output - the router LLM should return exactly the name of the route or a JSON with a route field, not free-text that requires parsing. Anthropic notes that separate, specialized prompts for each category outperform one-size-fits-all prompts, since each can be optimized for its domain2. A customer support agent might use routing to classify sentiment and urgency first - angry complaints go to a high-priority resolution path, simple FAQs go to a knowledge base lookup15.
Loops and State Machines
When you let an LLM-driven process iterate until a condition is met, you get a state machine. The classic example is the ReAct agent - Thought, Tool, Observation cycles repeating until the model decides it has enough information to answer16.
Loops are necessary for interactive or exploratory tasks. A research agent might search the web, read an article, realize it needs more info, search again, and only then formulate an answer. You can't know upfront how many search steps are needed.
But loops are also where agents get dangerous. A stuck agent can loop forever - misunderstanding, hitting errors, never resolving them. Always set a max iterations count. Add termination checks: after each iteration, evaluate whether the goal is achieved or progress has stalled. Consider timeout triggers or user-intervention hooks if loops run long.
Two named variants of structured termination are worth knowing. The search-until-found loop has the agent keep searching or generating until an LLM judge confirms the criterion has been met - useful when the goal is qualitative ("find me a flight that meets all these constraints") and you want the model itself to decide when it's done. The compile-test-fix loop for coding agents generates code, runs tests, feeds errors back, fixes, and repeats with a cap on retries. Both are more robust than either a one-shot attempt or an unbounded loop. Many coding agents (OpenAI Codex, Replit's Ghostwriter, Amazon CodeWhisperer, and similar products) implement the compile-test-fix pattern in their backends.
Parallelization
Running multiple steps concurrently saves time and can improve quality through redundancy2. There are two main flavors.
The first is fan-out/fan-in: split a task into independent parts, process them simultaneously, then aggregate. Summarize a long document by splitting it into chunks, summarizing each in parallel, then combining those summaries. Each chunk gets focused model attention without exceeding context limits.
The second is voting - run the same subtask multiple times, perhaps with different prompts or models, and pick the best result. Run code generation three times and use the version that passes tests. If one run hallucinates, maybe another won't.
You need a reducer function to combine results - concatenate lists, pick the maximum, merge content. Make sure the tasks are genuinely independent. And be mindful of rate limits: parallel calls multiply API usage in short bursts. Report mAIstro, an internal report-writing tool, uses parallelization heavily - spawning separate LLM calls to research and draft each section simultaneously, then compiling the final report in a separate step. A news summarizer agent can summarize five articles in parallel and deliver the digest 5x faster than sequential processing15.
Map-Reduce
A specific case of parallelization inspired by the classical programming model17. The map step processes each item in a list - generating a joke about each topic, retrieving relevant info for each question, extracting a field from each paragraph. These can run concurrently. The reduce step aggregates everything into a final output: compile all jokes, merge all Q&A pairs, build one structured report from all extracted pieces.

The powerful variant is dynamic map-reduce - the list of items for the map step is itself generated by an LLM. The agent decides at runtime how many and which subtasks to execute. A coding agent might determine it needs to edit three source files, spawning three worker tasks. A research agent might identify five facets of a question and search for each in parallel. LangGraph supports this by generating graph edges on the fly for each item17.
This pattern works well for multi-document Q&A (retrieve top N docs, answer from each, consolidate), brainstorming and filtering (generate 10 ideas, score each, pick top 3), and data extraction at scale (process each paragraph, merge into one structured output).
Some workflows go further and stack map-reduce hierarchically. First map over documents to get per-doc answers, then map over those answers to group and refine, then final reduce. It's map-reduce all the way up, and it's how you handle corpora that don't fit into any single aggregation step.
Multi-Agent Systems
I wanted multi-agent systems to be the obvious next step - more agents, more capability. The data is sobering. A 2025 study titled "Why Do Multi-Agent LLM Systems Fail?" analyzed 7 frameworks on 200+ tasks and found that current multi-agent setups often show minimal performance gains over single-agent approaches18.
They identified 14 distinct failure modes falling into three categories: specification issues (ambiguous roles causing agents to duplicate work or leave gaps), inter-agent misalignment (agents pursuing conflicting sub-goals), and task verification gaps (no single agent seeing the whole picture, so errors go unnoticed). Agents ping-ponging wrong answers, "leader" agents spawning excessive subagents for trivial tasks, and conversely failing to delegate when they should.
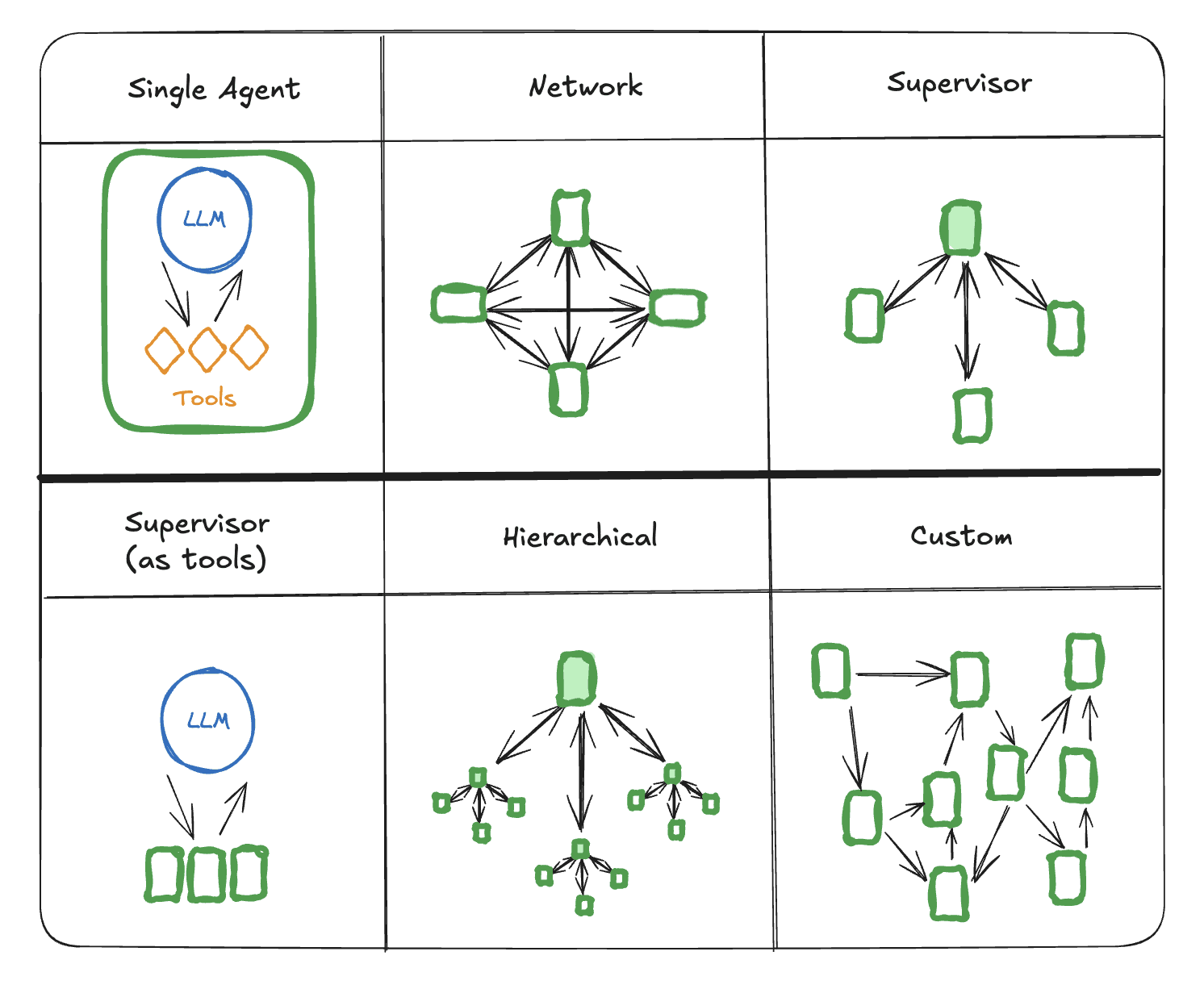
So why do people build them? Because when a task genuinely decomposes into independent pieces requiring different contexts, the overhead can be worth it. The architectures range from simple to elaborate2:
- Peer collaboration (network). Multiple agents talk to each other symmetrically and decide collectively. Useful for brainstorming or debate, harder to manage because no single agent owns the outcome.
- Supervisor or manager-agent. One agent is the boss, looks at the task, and delegates to specialist workers, then assembles the results. This is the most common production pattern because someone is always accountable for the final answer.
- Tool-based specialists. A variant of the supervisor pattern where the specialist agents are wrapped as callable tools. The main agent invokes
solve_math(problem)orgenerate_code(spec)without knowing there's another LLM behind the function. - Hierarchical teams. Layers of agents, where a top-level planner spawns mid-level agents that spawn their own sub-agents. The deepest layers do the actual work; upper layers coordinate and aggregate.
Orchestrator-Worker
The orchestrator-worker pattern is worth calling out separately because it handles dynamic task decomposition - you can't know ahead of time what subtasks are needed or how many2. One LLM (the orchestrator) breaks down the task, distributes pieces to worker LLMs, and synthesizes results.
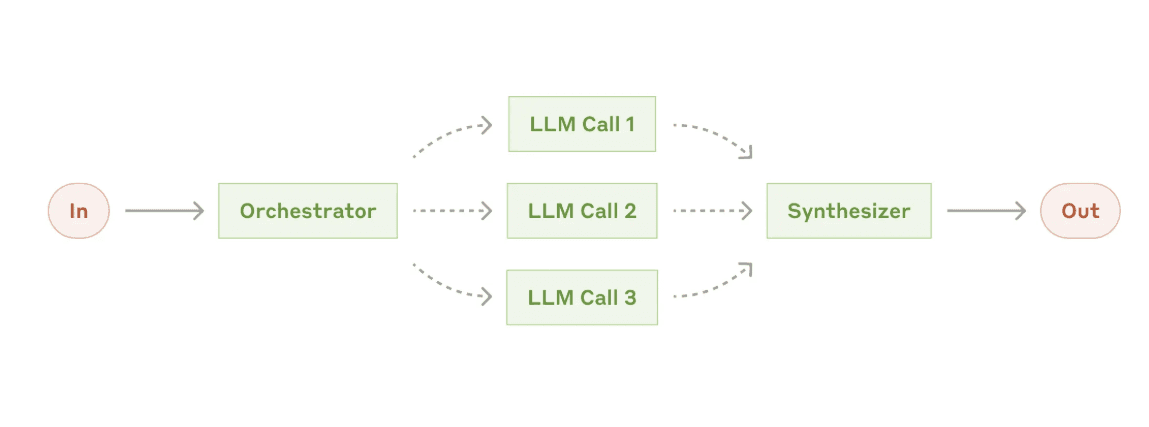
A related approach is the Mixture-of-Agents, where a router picks which expert agent handles each input - one for coding, one for math, one for general knowledge. Together AI demonstrated this with Groq hardware, routing queries to specialized 8B model agents and combining their answers19.
Multi-agent conversations are another emerging pattern. A "questioner" agent probes for missing information while an "answerer" tries to produce solutions. They chat until satisfied. This was explored to improve factual accuracy - the questioning agent forces justification and clarification. It's also used for evaluation: simulate a user-agent conversation with an AI user to test performance in realistic settings20.
Sharing State Between Agents
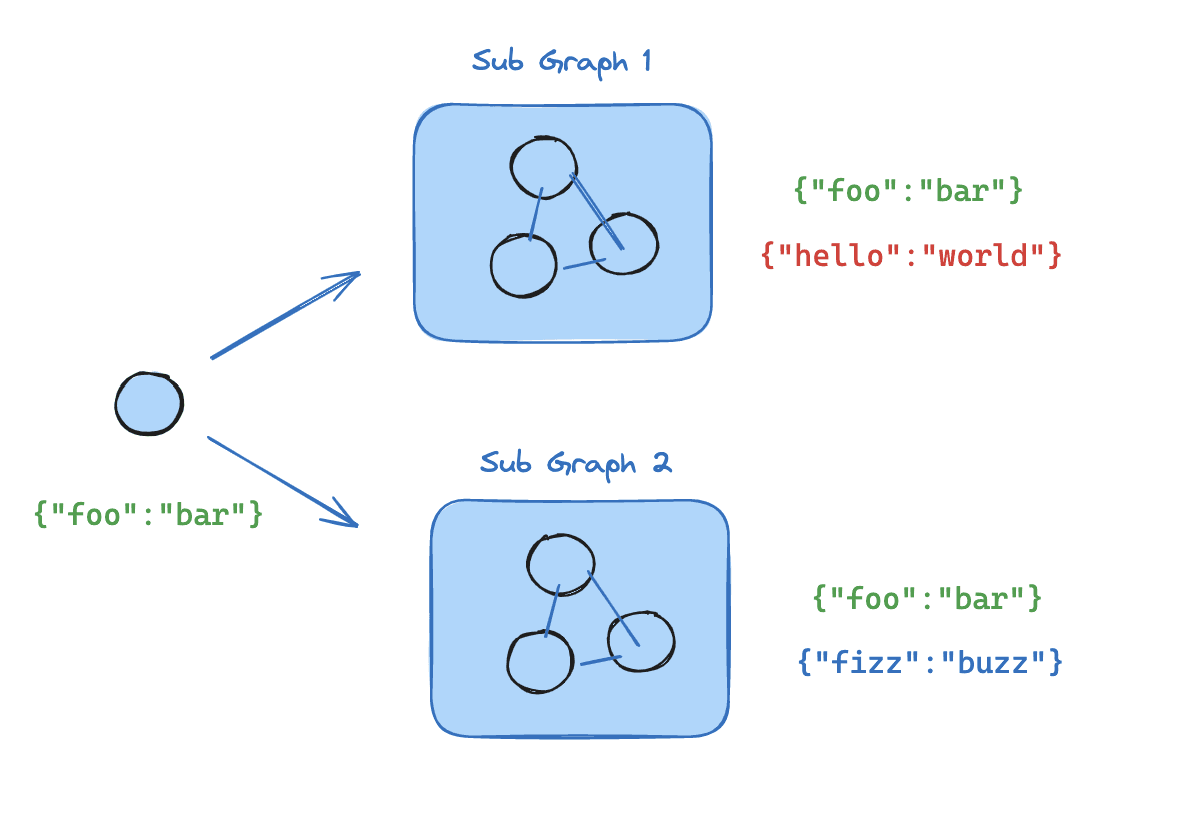
Managing state across multiple agents is the hardest part. Each agent has its own context window, and the communication layer between them can look very different. Some systems use a shared memory or blackboard that every agent reads and writes to. Others pass explicit messages between pairs of agents. Still others enforce strict turn-taking, where a supervisor picks who speaks next. The right choice depends on whether you need loose coordination or tight orchestration.
LangGraph's subgraph feature helps in the orchestrated case - you encapsulate an agent's internal logic in a subgraph node with its own local state schema, exposing only certain outputs to the parent graph21. Each agent runs somewhat independently, and you control what they share.
In April 2025, Google introduced the Agent2Agent (A2A) protocol - an open standard for agents to communicate across different platforms22. The idea is that an agent from Vendor A could call upon one from Vendor B, or a company could mix-and-match best-of-breed agents. A2A handles message passing, authentication, and session state between agents. It's a recognition that the future consists of an ecosystem of agents that need a common language, much like microservices have APIs.
ATLAS (Academic Task Learning Agent System) is a good example of multi-agent done right - a Coordinator agent interacts with the user and delegates to a Planner (study plans), Notetaker (content summarization), and Advisor (conceptual questions). Each is a distinct LLM prompt with a clear role15. Microsoft's AutoGen framework takes a similar approach: an Admin facilitates, a Planner outlines tasks, a Developer writes code, a Tester runs it. Inspired by human software teams15.
Anthropic's own research assistant shows a different shape. It spawns parallel search agents for different facets of a question - an orchestrator-workers setup where breadth of exploration matters more than tight shared context6. Harrison Chase's Kiroku document assistant uses yet another mix: one agent drafts, another checks for consistency or medical terminology, and a human approves each section. It's an agent network that combines multi-agent orchestration with HITL at every checkpoint15.
The honest assessment: many "multi-agent" apps are actually a single agent calling multiple tools, where each tool internally invokes an LLM. The boundary blurs. Anthropic found that many coding tasks weren't a good fit for multi-agent approaches because they require tight, shared context that's easier for a single model to handle2. The token cost is real - multi-agent runs used ~15x more tokens than single-agent in Anthropic's experiments6. Multi-agent is only worth it when the task is high-value enough to justify that cost. The practical endpoint for most teams is a hybrid system: a powerful primary agent with a few specialist helper-agents or tools, not a swarm of dozens. Keeping the team small and well-organised mitigates most of the failure modes above - the swarms that impress in demos are usually the ones that fail in production.
If you're building one, a few design rules survive every production post-mortem:
- Keep the number of agents minimal. More agents means more communication overhead and more failure points.
- Define each agent's role sharply and make sure the prompts reflect that role - overlap and contradiction between agents is where misalignment starts.
- Use a shared knowledge base for common facts, but avoid giving every agent the entire state. Keep each agent's context focused on what its role needs.
- Test each agent independently before combining them. Debugging one agent's prompt is tractable; debugging a swarm after the fact is not.
- Monitor the interactions. LangSmith (for logging LLM calls) or LangGraph's trace viewer make it feasible to see who said what when. Logging every inter-agent message is how you diagnose coordination bugs.
Self-Correction
Can agents actually check their own work? I expected self-correction to be the silver bullet - have the model review its output and fix mistakes. The reality is more nuanced than the pattern names suggest.
LLM as Judge
The simplest version: after an agent produces an answer, feed the question and answer to a separate "judge" prompt that scores quality and identifies errors. If the score is too low, the agent tries again.
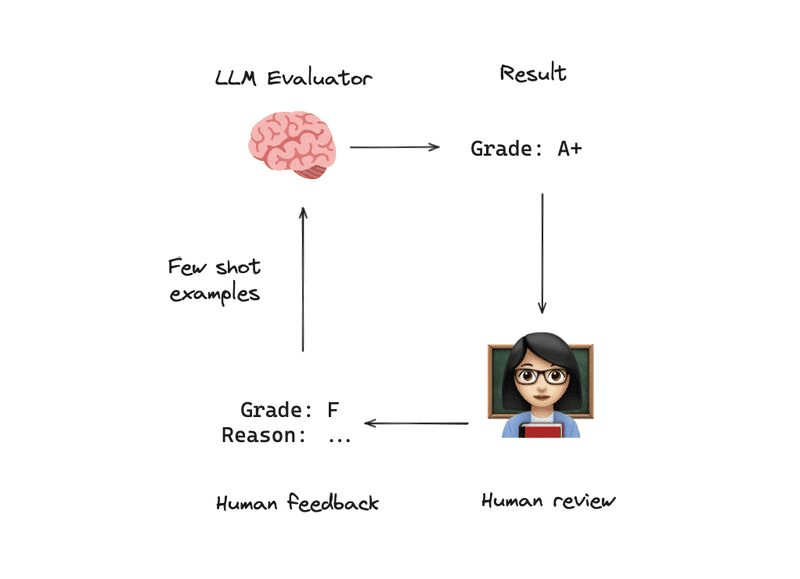
The problem is that an LLM judge can be biased in the same ways as the original model. The fix is a self-improving feedback loop: whenever the judge's evaluation disagrees with actual human feedback, log that case. Periodically update the judge prompt with few-shot examples of those disagreements. Over time, the judge gets better aligned with human preferences - an evaluation flywheel23.
Research like "Who Validates the Validators?" explores exactly this problem23. The takeaway: LLM evaluators are useful but should be calibrated and validated against real human opinions. Keep a human in the loop at least periodically to make sure the judge isn't drifting or reinforcing subtle biases. They're a starting point, not a final answer.
Reflexion
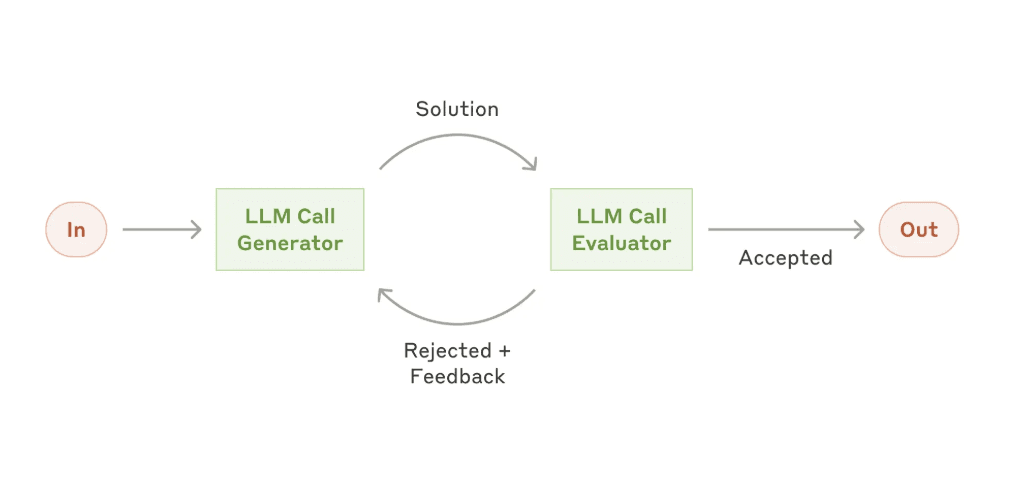
Reflexion (Shinn et al., 2023) has the agent attempt a solution, then critique its own output, then use that critique to produce an improved version. The agent plays both student and teacher2:
- Produce an initial solution (likely imperfect)
- Critique it: "What could be improved? What might be incorrect?"
- Generate a list of issues
- Use those issues to guide a second attempt
- Optionally loop until the critique finds nothing major
This works surprisingly well for math problems and coding challenges where the model can spot its own mistakes on reflection. But a TACL 2024 survey found that purely self-generated feedback rarely achieves reliable self-correction24. The model that made the mistake often can't see the mistake. External signals - test results, tool outputs, human feedback - are what make self-correction actually work2526.
A common variant uses a second model as the critic - GPT-4 critiquing a GPT-3.5 answer, or a larger model critiquing a cheaper one. The asymmetry helps: the critic sometimes catches mistakes the solver was structurally blind to, simply because it has different failure modes. Even a single model can do this in two stages by role-playing evaluator and solver separately.
A more sophisticated version uses tree search. Language Model Monte Carlo Tree Search (LM-MCTS) tries multiple reasoning paths, using a value function (possibly an LLM or heuristic) to evaluate partial solutions and prune bad trajectories early27. Reflection becomes the steering mechanism for the search.
Self-Healing Code
When agents write code, the environment itself provides feedback. This has become a distinct pattern:
- Generate code from a specification
- Execute it or run tests
- If errors occur, feed the error messages back with instructions to fix
- Loop with a cap on attempts
It's using runtime errors and test results as the evaluator instead of a learned model. This dramatically increases success rates because the model doesn't need to be perfect on the first try - it can learn from concrete failures.
The self-healing codebase agent extends this with memory15. It stores bug+fix pairs as vector embeddings. When a new error occurs, it retrieves similar past errors to guide the fix. Over time it builds a library of solutions to common pitfalls - an innovative blend of long-term memory and reflection specifically for coding.
Red Teaming
Finding weaknesses before users do. LangFuzz generates pairs of similar inputs designed to probe consistency - slight alterations to a question that shouldn't change the answer dramatically28. If the agent's answers to the pair are wildly inconsistent, that flags a potential issue. Another approach: simulate malicious users with adversarial agents that try to trick the main agent into breaking rules, then use the failures to patch vulnerabilities. Researchers have used exactly this technique to red-team models like GPT-4 - one AI attempts to socially engineer another, and the failures become training signal for the defences.
Learning from Experience
Self-correction fixes mistakes in the moment. Learning from experience improves the agent between versions. The distinction matters: one is intra-task, the other cross-task.
The cheapest form is to log failures as few-shot examples and feed them into subsequent prompts - "when the agent encountered this kind of input before, here's the correct response." Offline evaluation on real conversation transcripts identifies common failure modes that you can then target with prompt changes, schema tweaks, or tool adjustments. If you have enough usage data, reinforcement learning from human feedback (RLHF) on your specific task is the strongest version - fine-tuning the model to prefer actions that led to success in your logs29. It's non-trivial outside large orgs, but conceptually it's the same idea: close the loop between performance and improvement.
The theme across all the self-correction patterns is closing the loop. Agents aren't fire-and-forget scripts. You monitor how they perform, you evaluate that performance (automated or human-guided), and you have mechanisms - prompt updates, retraining, new tools - to make them better. The distinction between "the model critiques itself mid-task" and "the operator improves the model over time based on real usage" is where the patterns above start to stack.
Humans in the Loop
Given the 39% degradation in multi-turn performance, the self-correction limitations, and the Air Canada case establishing that companies bear full liability for agent outputs - human oversight isn't optional. It's a legal and practical necessity.
The question isn't whether to include humans but where and how much. Too many checkpoints and you negate the efficiency gains. Too few and errors go unchecked30.
At the lightest end, approval checkpoints pause the agent before irreversible actions - executing a large transaction, sending an email, deleting data - and ask a human to confirm. One step up, edit-and-continue lets a human directly modify the agent's intermediate output before the agent proceeds. LangGraph supports this through breakpoint nodes that halt the graph and allow state modification30. A Web UI generator agent, for example, generates HTML/CSS, lets the human preview and give feedback, then continues refining31.
Agents can also proactively ask when they're unsure - "I have two ways to interpret your request, which do you mean?" - using human input at decision points rather than waiting for mistakes. When confidence drops too low or the conversation goes in circles, fallback escalation transfers entirely to a human with full context preserved. Production support bots do this routinely: if the user explicitly asks to speak to a human, or the bot's confidence in its answer is low, or the conversation starts looping, control passes to a support agent with the conversation history attached so the human doesn't have to start from scratch.
The most ambitious version is the PayMan pattern - human-as-a-service: the agent gets a tool like request_human_help(task_description, price) for CAPTCHAs, phone calls, physical actions, or anything the AI can't do15. Under the hood it's an agent tool that posts tasks to a human marketplace, waits for a worker to complete the job, and returns the result to the agent's state like any other tool call. The agent becomes an orchestrator of both AI and human resources.
Kiroku, Harrison Chase's AI document assistant, demonstrates the balance well. The AI drafts each section of a medical report, but a human reviews, edits, and approves every section before it's finalized. Multiple internal agents enforce specific requirements - one for medical terminology, one for clarity - but a human has the final word. The AI handles perhaps 80% of the work; the human does the 20% that requires judgment and accountability15.
Where exactly to put checkpoints is its own design decision. A few rules of thumb: insert a human review step right before any irreversible external action - sending an email, making a purchase, deleting data. Insert one when multiple interpretations are possible and the agent is genuinely unsure. Insert one when the agent's confidence score drops below a threshold. And insert one on any risky-output trigger - the output touches regulated content, names a third party, or looks like it might violate policy.
Making the handoff smooth is as important as deciding where to put it. When a human intervenes, the system has to integrate the correction back into the agent's state so the agent doesn't ignore it the next turn. It has to preserve context so the human isn't re-reading the whole transcript. And it needs real UI affordances for the human - a clear place to approve, edit, or comment, and a clear view of what the agent is asking for. The design principle the rest of the pattern rests on: AI handles routine cases autonomously, routes uncertain or risky cases to humans, and gives human experts the tools to intervene cleanly. Not full autonomy, not full human control - most production deployments land in that middle.
Tools and Retrieval
The patterns above handle how agents think, remember, and coordinate. Tool use is how they interact with the real world.
ReAct
The ReAct framework (Yao et al., 2022) is the baseline for tool-using agents16. The agent interleaves reasoning ("Thought") with acting ("Action"). On each loop iteration, it either calls a tool or decides it has enough information to answer. The environment executes the tool and returns the result as an "Observation," which feeds back into the next reasoning step. In practice the prompt template looks something like:
Thought: <the agent's reasoning about what to do next>
Action: <tool_name>[<tool_input>]
Observation: <result returned from the tool>
... (repeat until the agent decides it has enough info)
Answer: <final response to the user>What makes ReAct work in practice: well-documented tools with clear input/output schemas (good tool documentation significantly improves reliability2), chain-of-thought prompting that encourages the model to reason before acting, error handling for when tools return nothing useful, and a termination condition so the agent knows when to stop searching and start answering.
ReAct agents are powerful for open-ended tasks - research a topic, book a flight, debug an application - but unpredictable. And remember that 39% degradation: each Thought-Action-Observation cycle is another turn of conversation, each one slightly less reliable than the last. The need for safeguards (routing, validation, human oversight) is why all the earlier patterns exist. They're the scaffolding around a ReAct core. Some benchmarks compare direct API calls against GUI automation for agent actions, finding significant performance differences depending on the task type32.
Agentic RAG
Retrieval-Augmented Generation is so common it deserves its own discussion. Basic RAG is a pipeline: take a query, search an index, fetch relevant documents, insert them in the prompt, generate an answer with citations. It's a workflow, not an agent.
Agentic RAG puts the retrieval under the agent's control. The agent might do multiple retrieval steps - ask one query, read results, realize something is missing, refine the query and search again. It might choose among multiple data sources based on the question type. It might verify each factual claim in its answer against the source documents, triggering additional searches for unsupported claims.
Several advanced retrieval patterns make agentic RAG more powerful. Multi-hop retrieval chains queries where each informs the next. "Who won the Nobel Prize in Physics in the year the author of The Road Not Taken was born?" requires finding Robert Frost, finding his birth year (1874), then finding the Nobel Physics winner that year. A static single-step RAG can't handle this - an agent can, through linked queries.
GraphRAG swaps vector stores for structured knowledge graphs. The agent translates questions into graph queries (e.g., Cypher for Neo4j) to get precise relational information. Microsoft's "From Local to Global GraphRAG" approach extracts entities and relations from text into a graph, then uses network analysis and prompting to answer complex queries33. Self-querying retrievers take a different angle - the LLM generates search queries that include metadata filters like year:2021 and type:report, producing more targeted results than pure semantic similarity.
Then there's ensemble retrieval: running multiple methods in parallel - keyword search and vector search, fine-grained paragraph index and coarse document-level index - then merging results. IncarnaMind used this for personal document Q&A, combining sliding-window chunks with document-level retrieval15. The Sophisticated Controllable RAG Agent project takes it further: decomposing hard questions into sub-questions, performing iterative retrieval with re-planning, and verifying every claim against sources15.
Realm-X (AppFolio's property management assistant) shows the production impact of careful RAG design - parallel retrieval and workflow branching boosted accuracy by 2x and reduced latency significantly15.
Structured Output
When an agent must return specific formats - JSON, SQL, API calls - you need enforcement beyond "please return JSON":
Native function calling (like OpenAI's API) lets you define a schema and get structured responses reliably. For models without this feature, libraries like Guardrails or regex-based validators catch format issues and feed errors back for correction.
The JSON Patch approach (TrustCall) is clever for complex schemas34. Instead of asking the model to output a full nested JSON structure in one shot (which often breaks), you have it output JSON Patch operations - small, incremental changes to a JSON document. Each patch is easier to get right, and you validate after each one. The reported benefits are three: it's faster and cheaper because the model doesn't waste tokens rewriting large chunks, it's resilient to validation errors because you catch and fix them incrementally, and it produces accurate updates to existing data without accidentally deleting other parts - which matters for anything that reads-modifies-writes structured state. It works across use cases from information extraction to filling a routing schema to multi-step agent tool use where intermediate data lives in JSON. You can even combine it with function calling: define a function whose schema expects a list of JSON Patch operations, then apply those patches to an in-memory object.
For code outputs, combine structural enforcement with execution: generate code, compile or run tests, feed errors back, iterate. The "structure" being enforced is passing all tests. The same idea applies to other structured languages - if the agent should output SQL, give it few-shot examples where every output is a SQL snippet with no extra commentary, then programmatically test that the query is syntactically valid (run EXPLAIN on it) and doesn't contain forbidden clauses. If it fails, prompt the agent to fix the SQL. Piecewise output assembly - generating a function body in one step, inserting it into a class template in another - constrains each step and reduces errors further.
Planning and Reasoning
Agents tackling complex tasks benefit from explicit planning before execution35. The Plan-and-Execute pattern: the agent first generates a high-level plan of steps, then executes them one by one, revising the plan if a step fails or yields unexpected information. Sometimes the plan is for the user to see and approve; sometimes it's purely the agent's own internal guidance and never surfaces to the UI. Erdogan et al.'s Plan-and-Act framework boosted web task success by ~54% using a separate planner and executor35. OpenAI's function-calling examples sometimes formalise this as two functions - one that outputs a plan, another that executes each step.
ReWoo (Reasoning Without Observation) separates internal reasoning from tool-requiring reasoning. The agent first thinks through the problem using only internal knowledge - forming a hypothesis and identifying specific gaps - then uses tools only for those gaps. This avoids wasting tool calls on things the model already knows.
Emerging Tool Patterns
The tool landscape is evolving fast. Meta's Toolformer showed models can learn to insert API calls into their own text during training36. The Model Context Protocol (MCP) and Google's A2A standard envision agents dynamically discovering available tools and their capabilities at runtime2237.
Even more experimental: agents creating new tools for themselves. Microsoft's AutoGen demonstrated agents that collaboratively write Python functions which then get executed as tools15. WorkTeam had agents translate natural language instructions into executable workflows38. Powerful, but it amplifies errors - sandboxing these auto-generated tools is essential.
Edge and Local Agents
Most examples assume cloud-based models, but there's growing interest in running agents on smaller, local models for privacy or offline use. TinyAgent and similar projects demonstrate structured tool use on small models like Llama 2 7B/13B - fine-tuning or prompting them to output function call formats, effectively enabling ReAct-like behavior without a cloud API. The reasoning is weaker, but if the tools do the heavy lifting (calculator, database lookup), a small model can manage basic orchestration. Running agents at the edge means no data leaves the device, which is attractive for privacy-sensitive applications15.
Ensemble Agents
Having multiple agents tackle the same problem in different ways, then reconciling their answers, is another emerging pattern. In the debate format, two agents with opposing viewpoints argue a topic and a judge (or human) decides who is more convincing - the idea being that agents call out each other's errors, leading to more truthful answers. The diverse-thought-chains variant prompts multiple instances with slightly different randomness or instructions, then votes or synthesizes a final answer. It's expensive (cost scales linearly with agents), but useful when a single run has a significant chance of failure. Some products already run two different models and only trust the answer if they agree15.
Multi-Modal Agents
Agents can extend beyond text by treating other modalities as input conversions or output tools. Voice integration plugs speech-to-text (OpenAI's Whisper, Google's speech API) and text-to-speech (ElevenLabs, Amazon Polly) around the agent's text-based core. The design considerations around voice are their own small discipline: the agent needs to produce more conversational, auditory-friendly output (shorter sentences, occasional verbal cues like "hmm" or tone control), and for responsiveness it usually needs to handle barge-in - users interrupting mid-reply - and partial speech input rather than waiting for a clean turn boundary.
Vision-capable models analyse images directly in the prompt, and you can expose that as a tool - something like a see_image function that takes an image reference and returns a description, letting the agent reason about visual data as part of a ReAct loop. Browser automation tools like Selenium let agents control web UIs through DOM reading and simulated clicks. NASA JPL's ROSA agent connects LangChain to the Robot Operating System (ROS) for natural language robot control15. For any robotics or physical-action setting, the safety story matters as much as the capability: human-in-loop approval for critical actions and a constrained action space to rule out dangerous moves are baseline requirements.
The challenge across all modalities is that they inflate context requirements and add latency. Describing a complex image may produce hundreds of tokens. Executing UI actions takes real time. These are solvable engineering problems, but they need deliberate design.
Security
As agents gain tool access, prompt injection becomes a first-class concern39. Malicious input can trick agents into ignoring instructions or performing harmful actions. Recommended defense patterns:
Run the LLM in constrained mode. Strictly validate outputs - if expecting SQL, disallow anything that's not a SELECT. Execute tools in sandboxes with minimal permissions. Require human confirmation for dangerous actions. Keep user content separate from system prompts (context segmentation)40. Security-by-design is becoming part of the agentic pattern language, and frameworks are starting to provide safety wrappers out of the box.
Production Deployment
When you deploy agents serving many users, additional patterns and considerations arise beyond the agent's logic itself.
Logging and tracing is vital - log each action, tool call, and LLM prompt/response (excluding sensitive data) for debugging and monitoring. Tools like LangSmith or custom logging let you replay conversations, see where an agent went wrong, and gather stats like tokens per query or tool call frequency. Logging is also critical for auditability: if an agent made a wrong decision, you need a record of why.
For throughput, treat LLM calls as asynchronous operations and batch them when possible. For long-running agents, use a job queue (Redis Queue, Celery) and worker processes - don't block your web server thread for 30 seconds while an agent works. Return an immediate response ("Your request is being processed") and deliver the result via WebSocket or email. This also helps with retrying failed tasks and scaling horizontally.
Dynamic scaling matters because agents can be heavy on memory and compute. Implement backpressure (queue or reject requests when overwhelmed) to avoid hitting rate limits on external APIs. Monitor key metrics: error rates, latency, cost (token usage spikes from prompt bugs), and user feedback (thumbs-down spikes might indicate a regression). Treat your agent like a microservice that needs ops monitoring.
Continuous evaluation and A/B testing: regularly run a suite of test queries through your agent to check for regressions when updating prompts or adding tools. Automated eval might include LLM-as-judge scoring and specific checks ("did it cite sources?"). A/B testing different agent versions with real users can reveal whether quality gains justify cost differences.
Versioning and rollback is non-negotiable. Version your prompts and chains like code. If a new version performs worse, roll back. Keep a staging environment where changes run on internal users first, and a canary path in production so you can compare old and new versions under real traffic before a full cutover. Prompt changes can silently regress quality in ways unit tests won't catch - the only safety net is being able to revert quickly.
Backend-enforced permissions are the other pattern worth calling out separately from prompt injection. Rather than trusting the agent to stay within bounds, have the agent call a backend API that enforces the rules - account-level permissions, spending limits, rate quotas. The agent requests the action; the backend approves or denies. Sandbox any code execution. Set hard spending limits per user. Authenticate both the user and the agent's right to act on their behalf. Prompt injection defences (constrained mode, output validation, context segmentation) live one layer above this - backend enforcement is the fallback when prompts fail.
For data privacy, be mindful of personal data in conversation logs and long-term memory stores - comply with regulations (GDPR etc.) by providing ways to delete user data. Vector databases should be treated as containing personal data if you store user utterances in them.
Measuring What Works
Security constrains what the agent can do. But how do you know the constrained agent is actually performing well? This turns out to be one of the hardest problems - we lack good automated metrics beyond simple task completion.
Benchmarks
The gap between demo and production is stark. BEARCUBS tested agents on real web tasks like booking a flight or editing a Google Doc. Humans succeeded 84.7% of the time. The best AI agent hit ~24%10. A popup or an unexpected modal is enough to derail most agents.
EconEvals tests agents on economic decision-making with hidden or shifting variables - budgeting, game theory, adapting to changing conditions. LLMs lack consistent rational decision-making over multiple turns when the landscape shifts41. ROLETHINK evaluates whether role-playing agents can maintain inner thoughts distinct from their outward persona - early results show models have a shallow grasp of this42.
SAFEARENA is particularly worth watching. It tests web agents on tasks with potential for harm and found that many agents fail to recognize unsafe actions. The practical implication: tool permissioning systems that give each tool a safety profile are becoming a requirement, not a nice-to-have43.
Chain Analysis
As agent workflows grow complex, it's hard to know which component causes failures. SCIPE (Systematic Chain Improvement and Problem Evaluation) automates this - run the agent on test cases, have an LLM judge evaluate each node's output, compute per-node failure statistics. It pinpoints the node that, if improved, would most likely boost final accuracy44. Targeted improvement beats guessing.
Paradigm, an AI-powered spreadsheet startup, runs thousands of agents in parallel. By tracing each agent's operations with LangSmith, they track token usage per user and implemented usage-based billing from that data45. Their case illustrates that designing the system around the agents - monitoring, cost management, scaling - matters as much as designing the agents themselves.
Transparency
Deploying agents in high-stakes settings requires systematic ways to audit decision trails, verify knowledge sources, and ensure constraint compliance46. That means attribution (citations for factual claims, already common in RAG), rationales (explanations for why an action was chosen), and honesty about the limits of both. Getting truthful rationales is tricky - there's a real risk of rationalization, where the agent generates a plausible but untrue explanation for its choice. Interpretable agent research is just beginning - and that gap between what agents can do and what we can verify is part of why the hype has cooled.
What's Left
Zoom out and a few lessons from the past year of building with these patterns are hard to miss:
- Larger context and fancier prompts don't automatically yield coherent multi-turn performance. The 39% drop is the most important single finding in this post, and the patterns only soften it.
- More agents and tools solve more complex tasks, but they introduce new failure modes and expenses. 4x-15x token overhead is normal, and multi-agent often matches single-agent on quality.
- Self-improvement loops help, but without grounding in external feedback they hit a ceiling. Test results, tool outputs, human signals - without those, self-correction is mostly theatre.
- Security can't be an afterthought. As agents gain autonomy, prompt injection, memory poisoning, and misuse become first-class concerns. Defence has to be designed in, not bolted on.
In practice, that shapes how you deploy. Augment existing processes rather than aiming for total autonomy4 - pick well-scoped tasks with clear success criteria ("extract these fields from these documents", "answer support tickets about password resets"). Keep humans in the loop for critical decisions. Add autonomy incrementally, starting with a workflow and gradually letting the LLM make more decisions as confidence builds. Be transparent about limitations and design fallbacks to safe states. Treat agent behaviour bugs like software bugs - the work doesn't end when the agent is deployed; that's when it begins.
A few open challenges remain:
- Robustness and generalisation. Agents still struggle outside their training distribution. Novel tool schemas, unusual phrasings, or new domains are enough to break them.
- Evaluation metrics. We lack good automated metrics for agent success beyond task completion. Human evaluation is often the only way to assess if output is useful, correct, and safe.
- Efficiency. The token appetite of advanced agents is enormous - 4x to 15x more for multi-agent setups6 - demanding caching, smaller specialist models for subtasks, and aggressive state compression.
- Ethics and alignment. With more autonomous behaviour comes the need to ensure agents act in alignment with human values. Agents can discover creative but unapproved strategies to achieve their goals46, and that's a harder alignment problem than a single-turn chatbot's.
But here's the tension I keep coming back to: the 39% degradation problem means that making agents conversational - which is what users want - makes them less reliable. The most effective interaction patterns are structured prompts, not free-form chat. That's a design conflict with no clean resolution. The patterns in this post are ways to manage that tension, not resolve it.
Footnotes
-
Laban et al., "LLMs Get Lost In Multi-Turn Conversation" (2025). arXiv:2501.05321. Comprehensive study of 15 LLMs across 200,000+ simulated conversations revealing systematic 39% performance degradation in multi-turn vs single-turn interactions, with identified behavioral patterns including premature solution attempts, answer bloat, loss-in-middle-turns, and cascading errors. ↩ ↩2 ↩3 ↩4
-
Anthropic, "Building effective agents" (Dec 2024) - a blog post outlining patterns like prompt chaining, routing, parallelization, etc., and best practices for agent design drawn from Anthropic's research and experience. ↩ ↩2 ↩3 ↩4 ↩5 ↩6 ↩7 ↩8 ↩9 ↩10 ↩11
-
Hacker News discussion on single vs. multiple LLM calls (2024). An OpenAI engineer's insight on when to prefer one big model call versus a sequence of calls, shared in a comment (summarized in the text above). ↩
-
Adrian Krebs, "AI Agents: Hype vs. Reality", Kadoa blog (Dec 2024). An overview of the challenges facing autonomous agents and perspective on monolithic vs. multi-agent designs, arguing for pragmatic use-cases first. ↩ ↩2
-
Air Canada chatbot incident - The Guardian (2023). Example of legal issues when an airline's AI assistant provided misleading info, leading to a court injunction (underscoring the importance of reliability). ↩
-
Anthropic Engineering, "How we built our multi-agent research system" (Oct 2024). Detailed the orchestrator-worker agent pattern, noting token usage was ~15x higher than single-agent. ↩ ↩2 ↩3 ↩4
-
Andrew Ng, The Batch newsletter (Aug 2024). Noted the drop in GPT-4's token pricing by ~$79 per year and advised focusing on functionality over cost optimization (since cost trends are favorable). ↩ ↩2 ↩3
-
LangChain Docs - "How to manage conversation history" (2023). Techniques for filtering, trimming, and summarizing chat history to keep prompts concise and relevant. ↩ ↩2
-
LangChain Docs - "Adding long-term memory (semantic search)" (2023). Discusses multi-vector indexing and advanced retrieval methods for agent memory. ↩ ↩2
-
Reddit (r/LangChain), "10 Agent Papers You Should Read from March 2025" - Community summary of recent papers, including Plan-and-Act, MemInsight, and the BEARCUBS benchmark (agents at 24.3% vs humans 84.7% on web tasks). ↩ ↩2
-
Park et al., "Generative Agents: Interactive Simulacra of Human Behavior" (2023). Created simulated characters with long-term memory and reflection. ↩
-
LangGraph Documentation - "Cross-thread persistence" (2023). Describes sharing state between agent sessions (useful for long-term memory and global knowledge bases). ↩ ↩2
-
Saptak Sen, Essay on long-term agent memory (2025). Explores hybrid approaches to memory storage, analogous to human working vs. long-term memory. ↩
-
LangGraph Documentation - "Time Travel" (2023). Describes replaying and forking agent states for debugging and iterative improvement. ↩ ↩2
-
Nir Diamant's GenAI Agents project (2023) - Open-source examples of many agent patterns (ATLAS academic agent, multi-agent research assistant, self-healing code agent, etc.) available on GitHub. These illustrate how the concepts discussed can be implemented with LangChain/LangGraph in real applications. ↩ ↩2 ↩3 ↩4 ↩5 ↩6 ↩7 ↩8 ↩9 ↩10 ↩11 ↩12 ↩13 ↩14 ↩15
-
Yao et al., "ReAct: Synergizing Reasoning and Acting in Language Models" (Oct 2022). Introduced the ReAct prompting approach for LLMs to decide when to use tools and how to chain reasoning steps. ↩ ↩2
-
LangGraph Tutorial - "Map-reduce operations" (2023). Example of dynamically spawning graph branches based on LLM-generated lists and aggregating results (implementing flexible map-reduce workflows). ↩ ↩2
-
Cemri et al., "Why Do Multi-Agent LLM Systems Fail?" (Apr 2025). Empirical taxonomy of 14 failure modes in multi-agent systems. ↩
-
Together AI demo, "Mixture-of-Agents architecture" (2024). Demonstrated a system routing queries to multiple specialized 8B Groq model agents and then combining their answers (showing MoE approach to agents). ↩
-
LangChain Evaluation - Simulated chat evaluation (2023). Using two agents (one as a fake user, one as assistant) to generate conversations and then scoring the assistant, as a way to automate evals. ↩
-
LangGraph Docs - "Subgraphs for multi-agent systems" (2023). How to encapsulate an agent within a subgraph node for better modularity and isolation in a larger graph (each sub-agent manages its own state). ↩
-
Google Developers Blog, "Announcing the Agent2Agent (A2A) Protocol" (Apr 2025). Introduced a standardized protocol for agent interoperability. ↩ ↩2
-
Shreya Shankar et al., "Who Validates the Validators? Aligning LLM-Assisted Evaluation with Human Preferences" (Apr 2024). Proposes methods (EvalLLM, EvalGen) for improving LLM-based evaluators using human feedback, highlighting the importance of calibrating AI judges. ↩ ↩2
-
Kamoi et al., "When Can LLMs Actually Correct Their Own Mistakes? A Critical Survey" (TACL 2024). Found that purely self-generated feedback rarely achieves reliable self-correction. ↩
-
Gou et al., "CRITIC: Large Language Models Can Self-Correct with Tool-Interactive Critiquing" (ICLR 2024). Showed that using external tools for validation led to consistent performance gains. ↩
-
Huang et al., "Large Language Models Cannot Self-Correct Reasoning Yet Without External Feedback" (2024). arXiv:2310.01798. Demonstrated that LLMs are unable to reliably recognize their own reasoning mistakes without external signals. ↩
-
Yao et al., "Tree of Thoughts: Deliberate Problem Solving with Large Language Models" (2023). Explores multiple reasoning paths in parallel. ↩
-
LangChain LangFuzz (Sep 2023). Experimental library for fuzz-testing LLM applications by generating pairs of similar inputs to find inconsistencies in outputs (metamorphic testing for AI). ↩
-
Hao et al., "Retrospective: Language Model is Basically an Optimization Problem" (2023). Introduced chain-of-hindsight methods where the model explains its reasoning after producing an answer, then analyzes that reasoning for flaws. ↩
-
LangGraph Tutorial - "Human-in-the-loop and Breakpoints" (2023). Shows how to insert a pause for user input in an agent workflow and resume after, including editing agent state mid-run. ↩ ↩2
-
Community example - "Web UI Generator Agent" by Ajit A. (2023). Implements a loop of an agent generating Tailwind CSS code and a human reviewing it each cycle, using LangGraph interrupts to allow accept/reject feedback. ↩
-
Li et al., "API-Bank: A Comprehensive Benchmark for Tool-Augmented LLMs" (2023). Compares direct API call approaches versus GUI automation for agent actions, alongside the WebArena benchmark for web-based agent evaluation. ↩
-
Poliakov & Shvai, "Improving RAG for Multi-Hop Queries using Database Filtering with LLM-Extracted Metadata" (2024). Research showing that combining LLM reasoning with structured database queries can improve multi-hop question answering (an example of advanced RAG techniques). ↩
-
W. Hinthorn, "trustcall: Reliable and efficient structured data extraction using JSON patch operations" (Aug 2023). GitHub README and demo for the TrustCall library. Introduces the JSON patch approach to structured outputs. ↩
-
Erdogan et al., "Plan-and-Act: Improving Planning of Agents for Long-Horizon Tasks" (Mar 2025). Introduced a planner/executor framework boosting web task success by ~54%. ↩ ↩2
-
Schick et al., "Toolformer: Language Models Can Teach Themselves to Use Tools" (2023). Fine-tuned a model to insert API calls into its text. ↩
-
Google Research, "Improving LLM Tool Use with MCP" (Aug 2024). Described the Model Context Protocol for dynamic tool discovery. ↩
-
Qian et al., "ChatDev: Communicative Agents for Software Development" (2024). Demonstrated multiple agents collaborating to translate natural language instructions into executable software workflows. ↩
-
Beurer-Kellner et al., "Design Patterns for Securing LLM Agents against Prompt Injections" (June 2025). Proposed principled patterns to mitigate prompt injection attacks. ↩
-
OpenAI, "Function Calling" announcement (Jun 2023). Describes how models can return structured data via function calls, which helps implement reliable tool use and output formatting. ↩
-
Chen et al., "EconEvals: Benchmarking Economic Decision-Making in LLM Agents" (2025). A benchmark testing agent decision-making in scenarios with shifting variables, budgeting constraints, and game-theoretic reasoning. ↩
-
Wang et al., "ROLETHINK: Evaluating Theory of Mind in Role-Playing Agents" (2025). A benchmark evaluating the separation of inner thought and outward persona in role-playing agents. ↩
-
Zhou et al., "SAFEARENA: Evaluating Safety of Autonomous Web Agents" (2025). A benchmark testing autonomous web agents on tasks with potential for harm, highlighting the need for tool permissioning systems. ↩
-
LangChain Blog - "SCIPE: Systematic Chain Improvement and Problem Evaluation" (Nov 2024). Discusses the SCIPE tool for identifying the weakest node in an LLM chain by analyzing intermediate failures. ↩
-
LangChain Case Study - "How Paradigm runs and monitors thousands of agents in parallel" (Sep 2024). Describes Paradigm's use of LangChain and LangSmith for an AI spreadsheet product, including parallel agent orchestration and usage-based pricing. ↩
-
AryaXAI, "Risks of Current Agents" (2025). Paper breaking down risks of agents across memory, tools, and environments. ↩ ↩2