Building on my tweet comparing vector databases, I dive deeper into embedding models and their applications in Retrieval-Augmented Generation (RAG) systems. The landscape of embedding models evolves rapidly, and understanding how to leverage them effectively can dramatically improve your retrieval systems.
This article explores advanced techniques for enhancing text retrieval quality, choosing the right embedding models, and implementing effective reranking strategies.
Embedding Models and Retrieval Techniques
New embedding models are released frequently, with performance continuously improving. The Massive Text Embedding Benchmark (MTEB) Leaderboard is an excellent resource for tracking the best embedding models available.
However, even the best embedding models sometimes fall short. When this happens, consider these advanced techniques to enhance text retrieval quality:
- Retrieve More and Re-rank: Increase the number of text extracts retrieved and re-rank them using models like
bge-reranker-large. - Use Different Length Windows: Embed documents using various window lengths (e.g., 1000 and 500 words) so you're effectively embedding your document multiple times.
- LLM-assisted Extraction: Use large language models (LLMs) to extract only the relevant parts of the text in your retrieve pipeline, then (optionally) re-embed and re-rank the extracted text.
- RAG-Fusion: Perform multiple query generations and use Reciprocal Rank Fusion to re-rank search results.
- Lemmatization: Keep one version for generating embeddings (with stopwords removed and lemmatization applied) and another with the original text for LLM context, that will be sent to the LLM as context.
- Hybrid Search: Incorporate results from classic lexical algorithms like
bm25in the re-ranking or RAG-fusion step. - HyDE Approach: Implement the HyDE approach, which uses hypothetical document embeddings generated by LLMs to match queries more effectively. This performs answer-to-answer embedding similarity search, rather than the traditional query-to-answer embedding similarity search used in standard RAG retrieval.
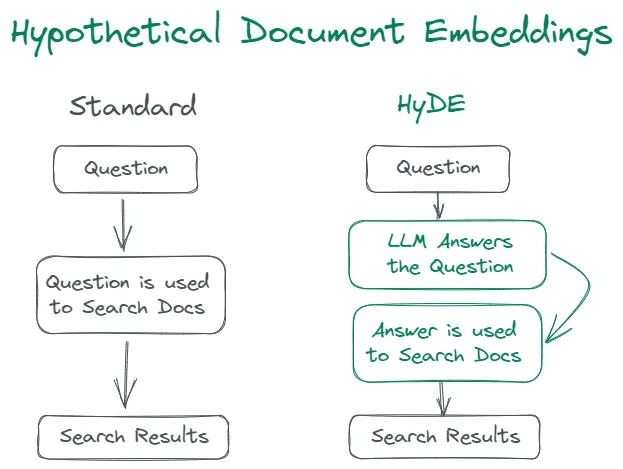
Choosing the Right Embedding Model
When selecting an embedding model, it's better to use Encoder-Decoder Models (Sequence-to-Sequence Models) like T5 or Encoder-only Models (Autoencoding Models) like BERT and RoBERTa, rather than Decoder-only Models (Autoregressive Models) like LLaMA or Mistral.
Encoder-only models offer bidirectional embedding, capturing the full context of the sentence for more accurate embeddings. While it's possible to extract embeddings from decoder-only models, they don't provide optimal performance. Larger models require more computation power and processing time. Encoder-only models excel at bidirectional embedding because they encode all information in the sentence, not just what's necessary to generate the next word.
Recommended models:
- Instructor-XL: A T5-based model with 3 billion parameters, optimized for instruction-following capabilities during embedding generation.
- BGE-XXL: An 11-billion parameter model that offers robust performance.
- BGE-Large-v1.5: A smaller, 1-billion parameter bi-encoder model performing well in various tasks.
- BGE-Reranker-Large: A cross-encoder model ideal for reranking.
The Importance of Re-Rankers
Re-rankers, or cross-encoders, play a critical role in maximizing retrieval recall. While a simple bi-encoder retrieves relevant documents, a cross-encoder refines this list by assigning a similarity score to each document-query pair, ensuring that only the most important documents reach the LLM.
We cannot simply return numerous documents to fill up the LLM context (context stuffing) because this reduces the LLM's recall performance. Note that this refers to LLM recall, which differs from retrieval recall.
When information is stored in the middle of a context window, an LLM's ability to recall that information becomes worse than if it hadn't been provided at all. This phenomenon is documented in the research paper "Lost in the Middle: How Language Models Use Long Contexts" (2023).
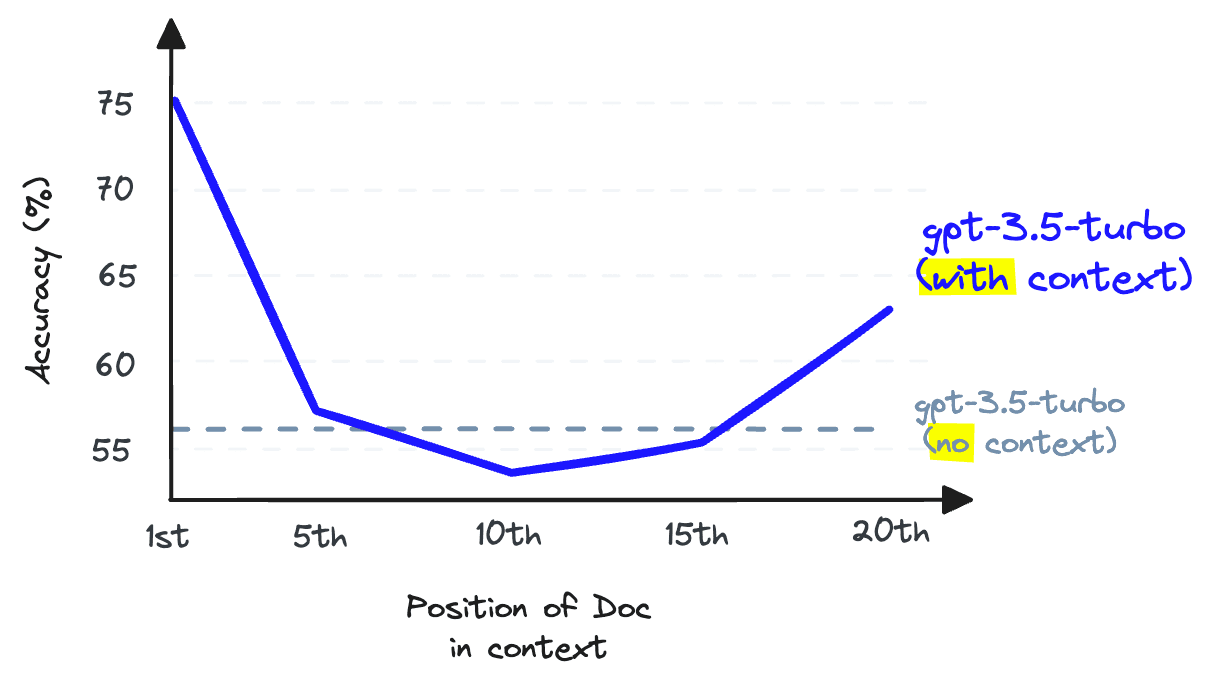
The solution is to maximize retrieval recall by retrieving many documents, then maximize LLM recall by minimizing the number of documents that reach the LLM. We achieve this by reordering retrieved documents and keeping only the most relevant ones through reranking.
This creates a two-stage retrieval system where the vector database step typically includes a bi-encoder or sparse embedding model:
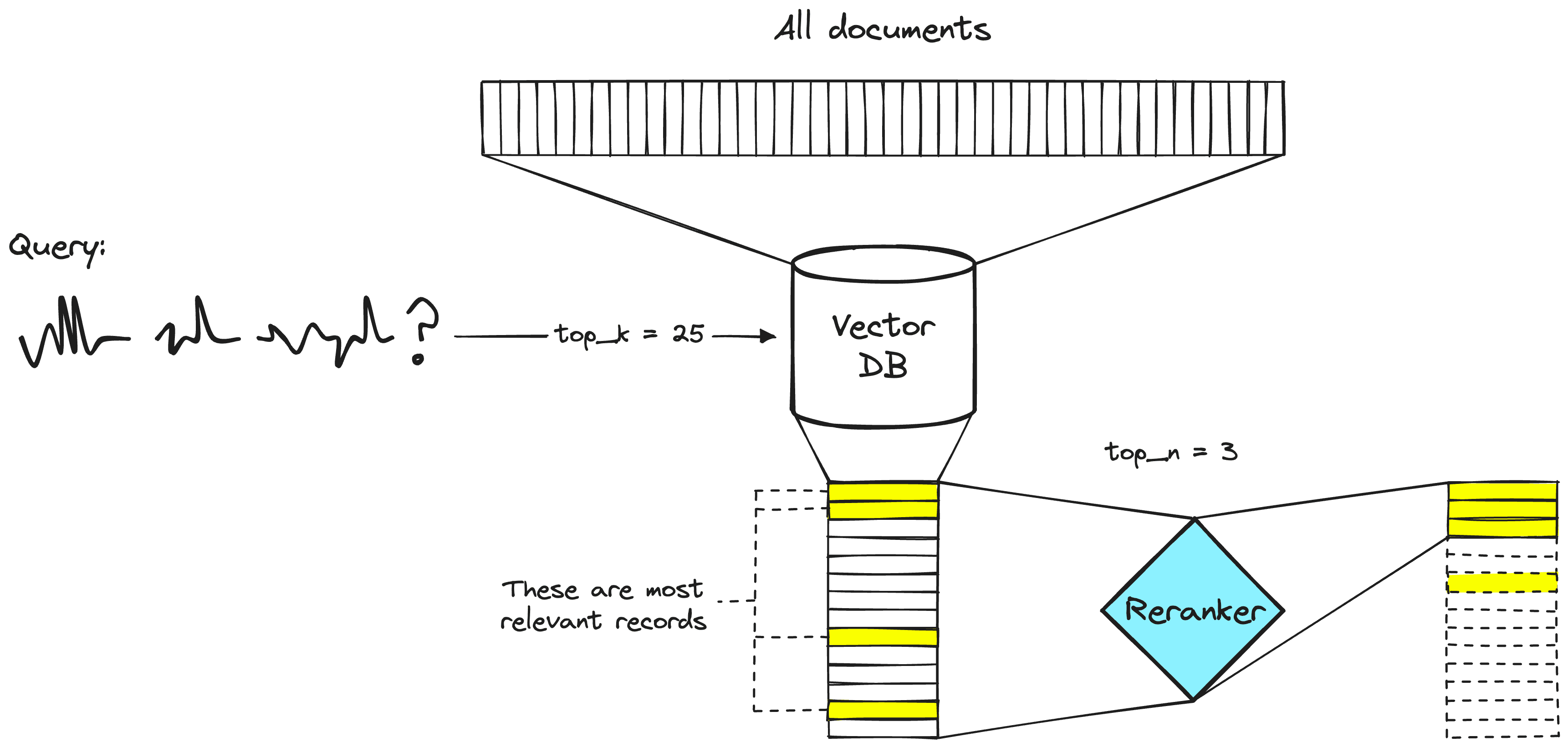
Search engineers have used rerankers in two-stage retrieval systems for years. In these systems:
- First stage: An embedding model/retriever retrieves relevant documents from a larger dataset
- Second stage: A reranker reorders those documents for optimal relevance
We use two stages because retrieving documents from large datasets is much faster than reranking large document sets. Rerankers are slow, retrievers are fast.
Why Use Re-Rankers?
Re-rankers are more accurate than embedding models because they consider the query and document together, preserving more information. However, they are slower because they process each query-document pair individually. Despite this, their superior accuracy makes them invaluable in applications requiring precise relevance, such as medical information retrieval or detailed research queries.
The intuition behind a bi-encoder's inferior accuracy lies in its limitations:
- Information compression: Bi-encoders must compress all possible meanings of a document into a single vector, causing information loss
- No query context: Bi-encoders lack query context since embeddings are created before receiving the user query
Rerankers overcome these limitations by:
- Direct processing: Receiving raw information directly into transformer computation, reducing information loss
- Query-specific analysis: Running at query time enables document meaning analysis specific to the user query, rather than producing generic, averaged meanings
Vector Databases: An Overview
Vector databases store data as high-dimensional vectors, making them essential for efficiently managing and searching through large embedding datasets.
Here's an overview of popular vector database options:
-
Elasticsearch: A distributed search and analytics engine that supports various types of data. One of the data types that Elasticsearch supports is vector fields, which store dense vectors of numeric values. In version 7.10, Elasticsearch added support for indexing vectors into a specialized data structure to support fast kNN retrieval through the kNN search API. In version 8.0, Elasticsearch added support for native natural language processing (NLP) with vector fields.
-
Faiss: A library for efficient similarity search and clustering of dense vectors. It contains algorithms that search in sets of vectors of any size, up to ones that possibly do not fit in RAM. It also contains supporting code for evaluation and parameter tuning. It is developed primarily at Meta’s Fundamental AI Research group.
- A lot of vector databases are built on top of this, including pgvector and Pinecone
-
Milvus: An open-source vector database that can manage trillions of vector datasets and supports multiple vector search indexes and built-in filtering. It is a cloud-native vector database solution that can manage unstructured data. It supports automated horizontal scaling and uses acceleration methods to enable high-speed retrieving of vector data.
- Milvus supports multiple approximate nearest neighbor algorithm based indices like IVF_FLAT, Annoy, HNSW, RNSG, etc.
-
Qdrant: A vector similarity search engine and vector database. It provides a production-ready service with a convenient API to store, search, and manage points - vectors with an additional payload. Qdrant is tailored to extended filtering support. It makes it useful for all sorts of neural-network or semantic-based matching, faceted search, and other applications.
-
Chroma: An AI-native open-source embedding database that's simple, feature-rich, and integrates with various tools and platforms. Provides both JavaScript and Python APIs.
- Claims to be the first AI-centric vector database and looks promising, though persistence may be limited when self-hosting
- Features a time-series function that could be valuable for streaming real-time data events and performing queries over time series
-
OpenSearch: A community-driven, open source fork of Elasticsearch and Kibana following the license change in early 2021. It includes a vector database functionality that allows you to store and index vectors and metadata, and perform vector similarity search using k-NN indexes.
-
Weaviate: An open-source vector database that allows you to store data objects and vector embeddings from your favorite ML-models, and scale seamlessly into billions of data objects.
-
Vespa: A fully featured search engine and vector database. It supports vector search (ANN), lexical search, and search in structured data, all in the same query. Integrated machine-learned model inference allows you to apply AI to make sense of your data in real time.
-
pgvector: An open-source PostgreSQL extension for storing and querying vector embeddings within your database. Built on the Faiss library and easy to install with a single command.
- Basic PostgreSQL extension that's open source, free, and ubiquitous
- May not benchmark as well as specialized vector databases
- Excellent for integrating with relational metadata, though not as fast as best-of-breed vector databases
-
Vald: A highly scalable distributed fast approximate nearest neighbor dense vector search engine. Vald is designed and implemented based on the Cloud-Native architecture. It uses the fastest ANN Algorithm NGT to search neighbors. Vald has automatic vector indexing and index backup, and horizontal scaling which made for searching from billions of feature vector data.
- Vald uses a distributed index graph to support asynchronous indexing. It stores each index in multiple agents which enables index replicas and ensures high availability.
- Vald is also open-source and free to use. It can be deployed on a Kubernetes cluster and the only cost incurred is that of the infrastructure.
-
Apache Cassandra: An open source NoSQL distributed database trusted by thousands of companies. Vector search is coming to Apache Cassandra in its 5.0 release, which is expected to be available in late 2023 or early 2024. This feature is based on a collaboration between DataStax and Google, who are working on integrating Apache Cassandra with Google’s open source vector database engine, ScaNN.
-
ScaNN (Scalable Nearest Neighbors, Google Research): A library for efficient vector similarity search, which finds the k nearest vectors to a query vector, as measured by a similarity metric. Vector similarity search is useful for applications such as image search, natural language processing, recommender systems, and anomaly detection.
-
Pinecone: A fully managed vector database designed for machine learning applications. Fast, scalable, and built on Faiss.
- Offers filtering, vector search libraries, and distributed infrastructure for reliability and speed
- Hosted solution with limited free tier (one index) and expensive paid plans
- De-facto choice for many projects, though not self-hosted
-
Marqo: Simple to use with built-in embedding and inference management, multi-modal support, and automatic text/image chunking.
-
Embeddinghub: An open-source solution for storing machine learning embeddings with high durability and easy access. Supports intelligent analysis (approximate nearest neighbor operations) and regular analysis (partitioning and averaging). Uses HNSW algorithm via HNSWLib for high-performance lookups.
-
Redis: The popular key-value store that also supports vector databases. Widely available, free, open source, and extremely fast. Popular in the Rails community. See the quick start guide for implementation details.
Common Features of Vector Databases
Vector databases and vector libraries both enable vector similarity search, but differ significantly in functionality:
Vector Databases:
- Store and update data dynamically
- Handle various data source types
- Perform queries during data import
- Provide user-friendly, enterprise-ready features
Vector Libraries:
- Store data only (no updates)
- Handle vectors exclusively
- Require importing all data before building indexes
- Need more technical expertise and manual configuration
Many vector databases are built on existing libraries like Faiss, leveraging proven algorithms and features to accelerate development. Most vector databases share these common capabilities:
-
Vector similarity search - Finding k nearest vectors to a query vector using various similarity metrics. Useful for image search, NLP, recommender systems, and anomaly detection.
-
Vector compression - Reducing storage space and improving query performance through scalar quantization, product quantization, and anisotropic vector quantization.
-
Flexible nearest neighbor search - Supporting both exact (perfect recall, slower) and approximate (faster, slight recall trade-off) search depending on your accuracy-speed requirements.
-
Multiple similarity metrics - Supporting L2 distance, inner product, cosine distance, and other metrics suited to different use cases and data types.
-
Multi-modal data support - Handling text, images, audio, video, and other data types by transforming them into vector embeddings using appropriate machine learning models.
When choosing a vector database, consider your specific needs and requirements. Remember that vector databases excel at storing vectors efficiently and performing mathematical operations on them, but should not be used as persistent storage for your primary data.
Conclusion
Embeddings and vector databases form the backbone of modern RAG systems. The key to building effective retrieval systems lies in understanding the trade-offs between different approaches:
- Choose appropriate embedding models based on your architecture needs (encoder-only vs decoder-only)
- Implement two-stage retrieval with reranking to maximize both retrieval and LLM recall
- Select vector databases that match your scalability, performance, and operational requirements
As embedding models continue to improve and new techniques emerge, the potential for enhancing retrieval systems grows. The combination of advanced embedding techniques, strategic reranking, and well-chosen vector databases can dramatically improve the quality and efficiency of your RAG implementations.
References
- Top 10 best vector databases and libraries
- Reddit Discussion on Open Source Vector Databases
- Navigating the Vector Database Landscape
- Not All Vector Databases Are Made Equal
- Reddit: Finding better embedding models
- Rerankers and Two-Stage Retrieval