The ability to generate stunning AI images has become accessible to everyone. Remember the days of generative adversarial networks (GANs)? Those models could only produce blurry, small-scale images. Today, we stand at a point where high-resolution, life-like images are available to anyone, thanks to advanced open-source models like Stable Diffusion XL and checkpoints like Juggernaut.
While there are proprietary tools like Midjourney and DALL·E from OpenAI offering image generation services, they come with subscription costs and built-in safety layers. Fortunately, the open-source ecosystem around generative AI offers robust alternatives. The most renowned among these is Stable Diffusion XL, launched in late July 2023.
Creating these images doesn't require vast computing resources from your end. The community has developed various checkpoints - fine-tuned versions of these models using additional specialized training data. These are readily available on platforms like Civit AI, some of which are highly optimized for photorealism.
User Interfaces
The key to using these models lies in user-friendly interfaces. The most well-known option is the Stable Diffusion Web UI - an incredibly powerful tool. There are other options that might be initially less daunting, such as Comfy UI that offers an intuitive drag-and-drop editor similar to Blender or Unreal Engine.
The interface I'm using is Fooocus, which combines ease of use with powerful features. Like many AI UIs, it's built upon the foundational open-source project Gradio.
Getting Started
The README.md is good to read through, but in general, setting up is straightforward:
- Clone the repository from GitHub
- Create a Python virtual environment and install the required packages
- Run the entry script with
python entry_with_update.pyto automatically download default models (note: these files can be quite large)
Using Fooocus
With Juggernaut XL as the base model, you're now equipped to bring any imaginative concept to life. The UI of Fooocus, similar to Midjourney but free, is highly intuitive. I run it on a modest RTX 2060, and it typically takes about 45 seconds to generate two high-quality images.
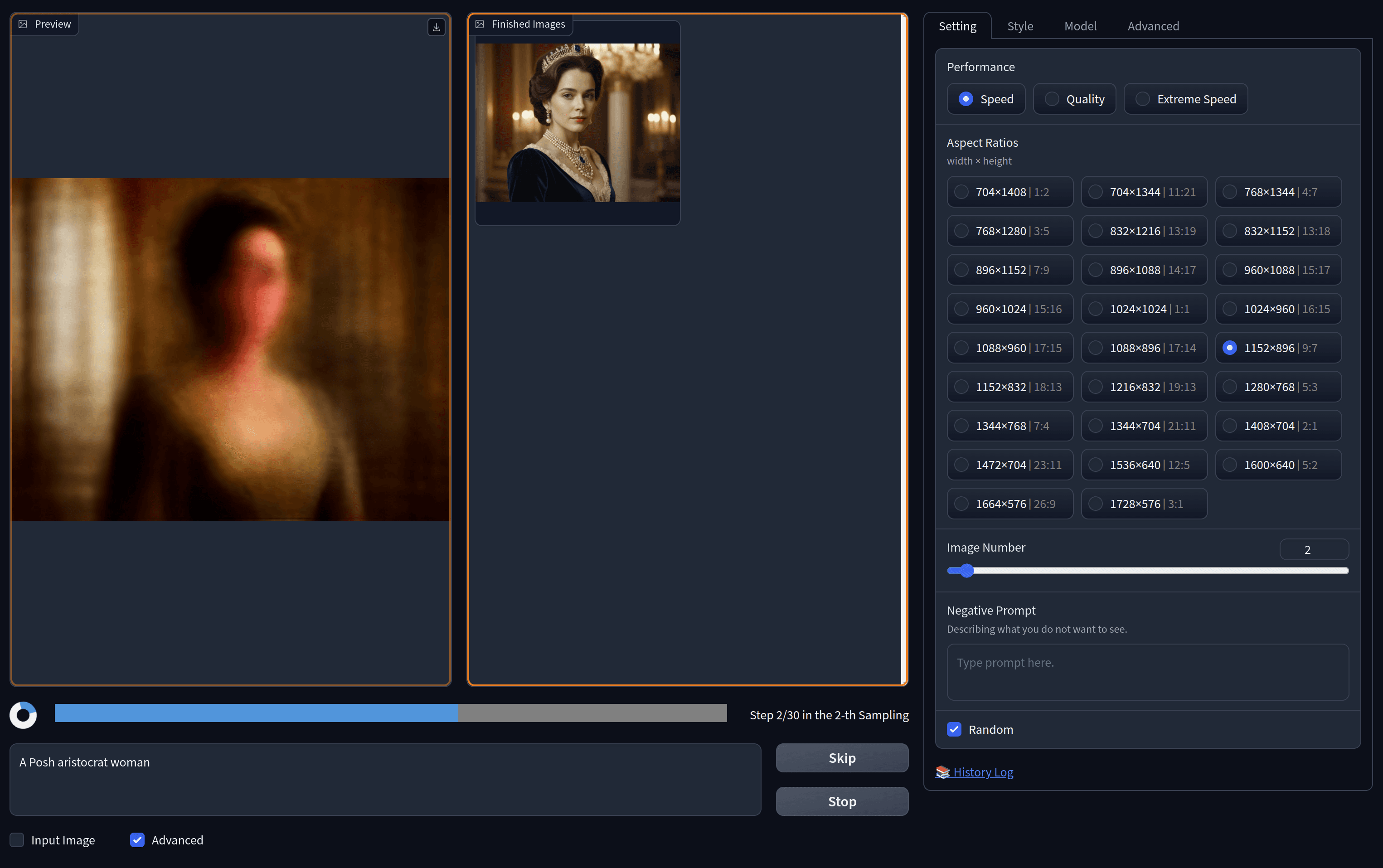
The advanced tab in Fooocus unlocks a bunch of other features - performance settings, aspect ratio, the number of images to generate, and style variations can all be set here. You can experiment with different artistic styles, such as anime or retro video game aesthetics.
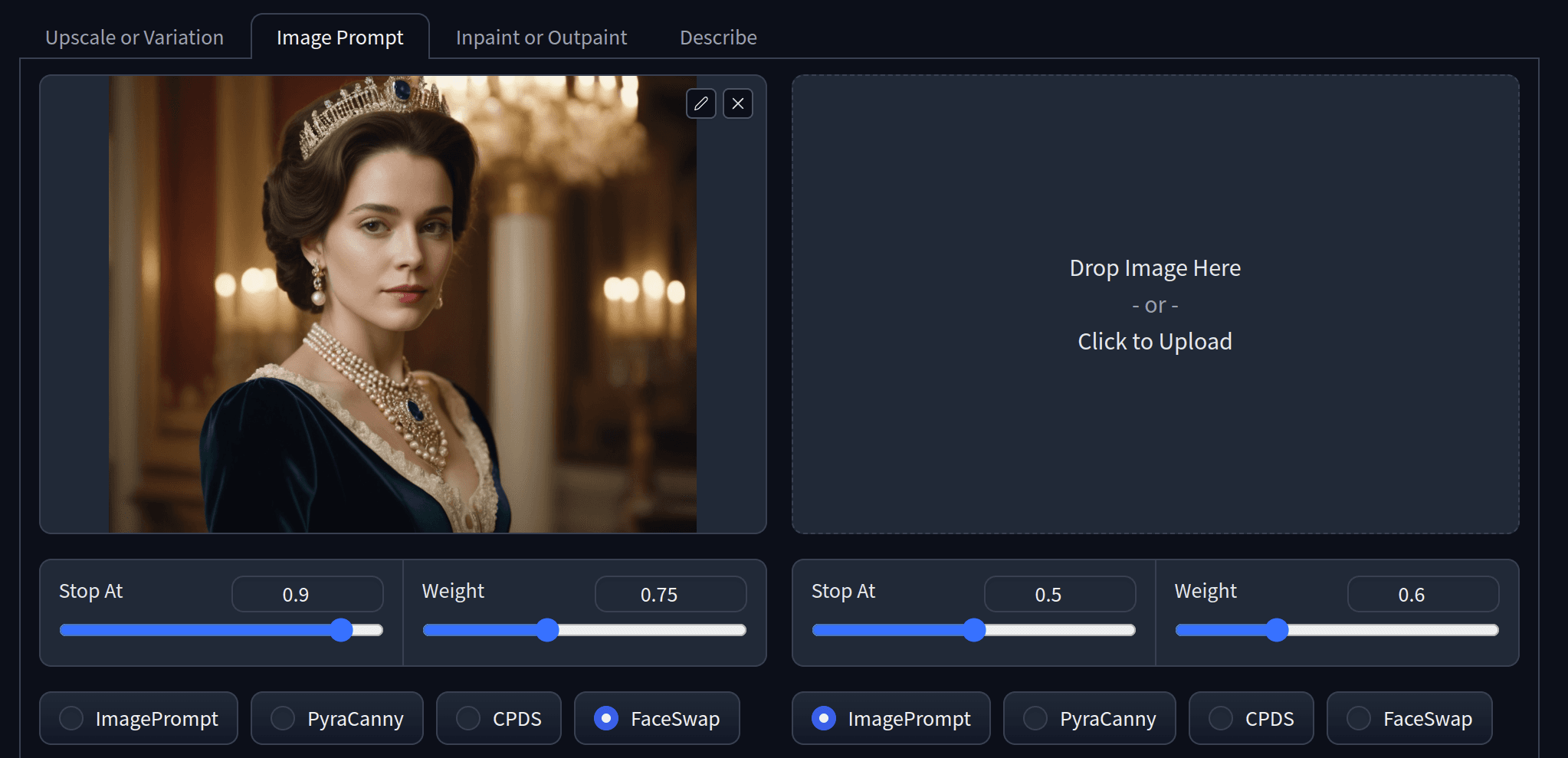
You can also generate an image and save this as your base image, then create a new prompt and check the box for input image. This allows for consistency between images. For example, for people, you can use face swap and then write a text prompt to change the setting. Most importantly, we have pretty good continuity between faces.
Beyond Images
The journey doesn't end with still images. Pika Labs recently showcased a groundbreaking text-to-video platform. For open-source enthusiasts, Stability AI has introduced Stable Diffusion Video, opening new horizons in video creation.
As an update in 2024, Google's Lumiere, a space-time diffusion model for video generation, brings AI video closer to real than unreal!